Chapter 47: Multimodal Large Model (VLM) Data Recipes: From Pre-Training to Visual Alignment¶
Abstract¶
As architectural innovations in Vision-Language Models (VLMs) converge, the sophistication of data recipes has become the primary dividing line between leading models and their followers. This chapter systematically deconstructs the data engineering practices of mainstream VLMs—including Qwen2.5-VL, InternVL3, LLaVA-OneVision, and MiniCPM-V—through the lens of "recipes." The discussion first establishes a three-stage pipeline covering pre-training, multi-task high-resolution alignment, and Supervised Fine-Tuning (SFT), explaining the order-of-magnitude differences in data scale, quality requirements, and freezing strategies at each stage. It then cross-compares these models' data composition ratios across image-text pairs, interleaved image-text documents, OCR-Rich data, visual grounding data, and video data, identifying key trends such as the primacy of re-captioning, safe thresholds for OCR data, and the evolution of video data from optional to mandatory. The chapter subsequently analyzes the data engineering divergence between the Dynamic Hi-Res Patching and Native Resolution camps with respect to token-length management and bucketing, as well as quality-improvement mechanisms combining CLIP-score filtering with strong-VLM re-annotation. The chapter emphasizes that transforming raw alt-text into executable visual supervision signals is the central challenge for reproducibility in modern VLM data recipes.
Keywords¶
VLM data recipe; vision-language model; re-captioning; high-resolution training; OCR-Rich data; multimodal SFT
Learning Objectives¶
- Design a three-stage VLM pipeline covering pre-training, multi-task high-resolution alignment, and SFT, and articulate the differences in data scale, quality requirements, and freezing strategies at each stage.
- Compare Qwen2.5-VL, InternVL3, LLaVA-OneVision, and MiniCPM-V with respect to their data composition ratios across image-text pairs, interleaved documents, OCR-Rich data, visual grounding, and video data.
- Distinguish the data engineering divergences between the Dynamic Hi-Res Patching and Native Resolution camps in token-length management and bucketing.
- Design a quality-improvement mechanism combining CLIP-score filtering with strong-VLM re-annotation, and establish safe OCR data thresholds.
- Explain why transforming raw alt-text into executable visual supervision signals is the central challenge for reproducibility in VLM data recipes.
Case Study: Data Recipe Bottlenecks in Vision-Language Model (VLM) Reproduction¶
In industrial-grade reproduction practices of Vision-Language Models (VLMs), researchers frequently observe a classic performance bottleneck: even when employing the same visual encoder specifications as state-of-the-art models (such as Qwen2.5-VL), paired with a Large Language Model (LLM) backbone of comparable parameter scale, and rigorously following early classic two-stage training pipelines (such as LLaVA-1.5's Stage-1 visual alignment pre-training on 558K LAION-CC-SBU pairs, and Stage-2 full-parameter fine-tuning on LLaVA-Instruct-150K), the resulting scores on complex multimodal benchmarks like MMMU and DocVQA fall significantly short of expectations—often by gaps of 10 to 15 percentage points. While such models demonstrate fluent conversational abilities and basic instruction-following in preliminary human evaluations, their performance on high-difficulty cognitive tasks lags substantially.
In-depth engineering analyses reveal that the root of this performance gap lies not primarily in model architecture, but rather in the limitations of early public methodologies across data engineering dimensions. Specifically, this bottleneck can be attributed to four neglected data engineering vectors:
- Data Quality Degradation: The image-text relevance of raw web-crawled alt-text (e.g., in the LAION dataset) is typically low, with a median CLIP cosine similarity of only around 0.26. In contrast, advanced models commonly use data re-annotated by strong models (like GPT-4V), achieving median similarities above 0.61. Low-quality captions cause the model to establish incorrect cross-modal alignments during pre-training.
- Resolution Downsampling Loss: Traditional fixed-resolution preprocessing (e.g., resizing to 336×336) completely erases the fine-grained textual information densely packed in financial PDFs and textbook illustrations, directly impairing the model's Document Visual Question Answering (DocVQA) capabilities.
- Data Type Coverage Deficiency: Early instruction fine-tuning datasets (such as LLaVA-Instruct-150K) lack instructions rich in Optical Character Recognition (OCR-Rich) data, ChartQA, and visual Grounding (featuring bounding box coordinates). This distributional deficiency leaves the model with poor generalization in document understanding and precise localization tasks.
- Lack of Curriculum Scheduling: In traditional approaches, all data is uniformly mixed and sampled across stages. However, modern state-of-the-art VLMs employ dynamic sampling strategies, upsampling high-information-density data (such as visual mathematical reasoning) in later stages and introducing an annealing window of high-quality data at the end of pre-training. Mixed sampling without phase isolation significantly reduces the convergence efficiency of higher-order capabilities.
This case reveals the core proposition of current VLM engineering research and development: the sophistication of the data recipe directly determines the model's capability ceiling. As architectural innovations gradually converge, fine-grained control at the data engineering level has become the critical factor delineating model performance. In the rapid iteration cycle of multimodal technologies, constructing more refined and rigorous multimodal data engineering recipes is far more crucial than minor architectural tweaks to the model.
Prerequisites and Compliance Notice: This chapter focuses on the "data recipe" and curriculum scheduling differences specific to particular VLMs. The foundational topics of image-text pair crawling, MinHash deduplication pipelines, basic OCR extraction, and general-purpose cross-modal alignment preprocessing (e.g., Resize/CenterCrop image processing pipelines) are covered in depth in Ch08 (Image-Text Pairs), Ch09 (Re-annotation and Document Understanding), Ch10 (Video and Audio), and Ch11 (Cross-Modal Alignment). For underlying general-purpose pipelines, readers may refer to the multimodal data engineering panorama in Figure 47-1. Additionally, for copyright provenance risks associated with image crawling, refer directly to Ch04 §4.4 and Ch27 (Data Compliance). This chapter covers "recipes" only, and does not revisit the "underlying plumbing."
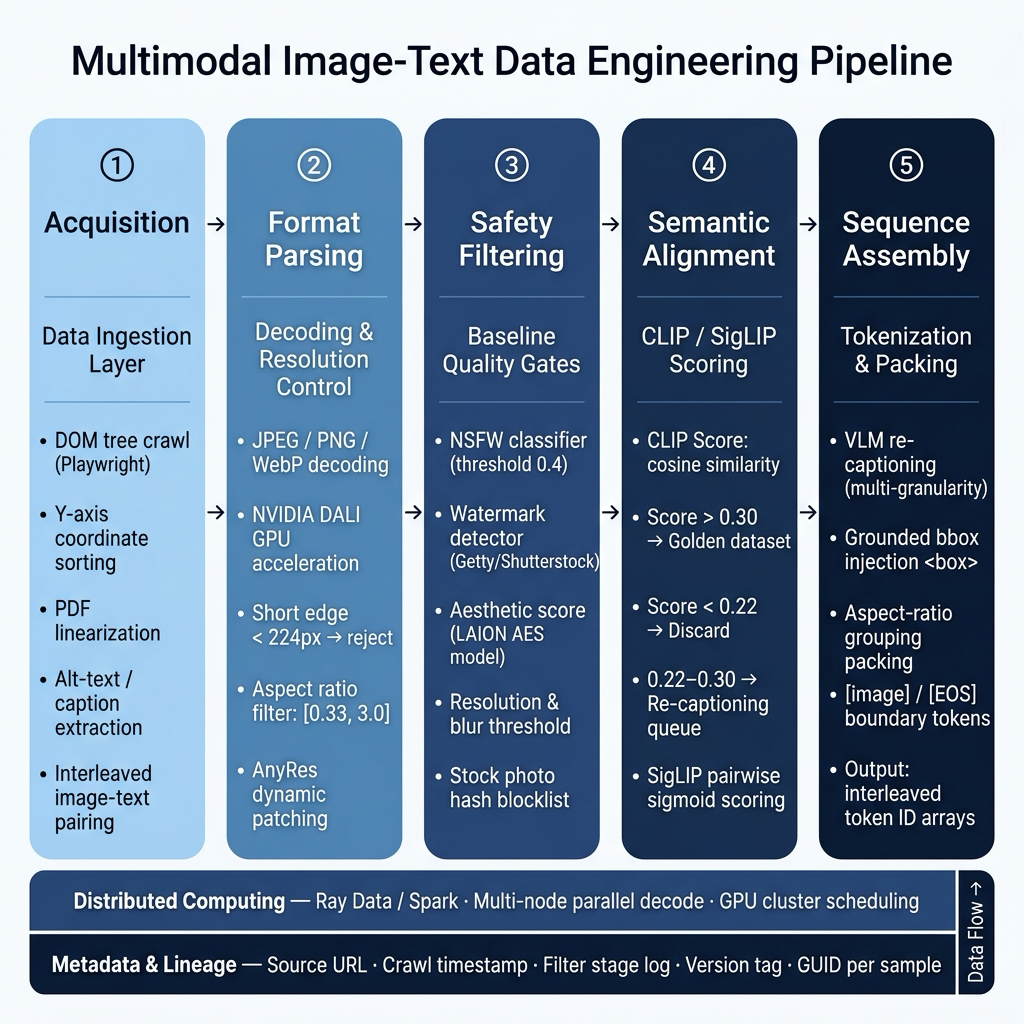
Figure 47-1: Multimodal Data Engineering Panorama (adapted from Chapter 8 base figure).
47.1 The Three-Stage VLM Data Pipeline¶
A close reading of the technical reports for Qwen2.5-VL or InternVL3 reveals that modern VLM data recipes have crystallized into a highly standardized "three-stage pipeline" (as shown in Figure 47-2). Even the pre-training stage alone has evolved beyond simple "concept binding" toward deep "visual feature structuring." Each stage exhibits order-of-magnitude differences in data quality requirements, type distribution, and volume, and blindly mixing data across the three stages is the leading cause of recipe failure for many teams.

Figure 47-2: VLM Three-Stage Data Pipeline.
Stage 1: Pre-training (Feature Alignment)
The core objective of this stage is coarse-grained alignment between visual concepts and text vocabulary. Data scale is typically in the range of hundreds of millions to billions of image-text pairs, with primary sources including CLIP-filtered LAION subsets (Schuhmann et al. 2022), DataComp-1B (Gadre et al. 2023), COYO-700M, and re-captioned datasets that emerged over the past two years (e.g., ShareGPT4V-1.2M, LLaVA-Recap-558K).
Three key engineering principles are prominent among leading models at this stage. First, freeze the LLM and train only the visual encoder and projector to prevent catastrophic forgetting in the LLM caused by low-quality noisy image-text data. Second, apply a CLIP-Score filtering threshold (typically ≥ 0.28) to remove image-text pairs with very low relevance—this single step can eliminate up to 70% of low-quality samples from the raw LAION-5B. Third, re-captioning takes priority over raw alt-text—ablation experiments by InternVL3 show that replacing the alt-text of 558K original LAION samples with detailed descriptions rewritten by a strong VLM improves visual alignment accuracy at Stage 1 by approximately 7 MMMU percentage points [D] (Chen et al. 2023).
Stage 2: Multi-Task and High-Resolution Alignment
This is the stage that enables new-generation VLMs to comprehend invoices, financial reports, and complex academic chart figures. Data scale is typically in the tens of millions of samples, but requirements for type diversity and format correctness multiply substantially. Key data types introduced at this stage include: high-resolution OCR data (PDF screenshots with text coordinate annotations), DocVQA, InfoVQA, TextVQA, visual grounding data (with bounding box coordinates), interleaved image-text web data, and chart QA datasets (ChartQA, PlotQA, FigureQA).
The central engineering challenge at this stage is resolution adaptation and token-length management. When OCR image resolution increases from 336×336 to 1344×1344, the number of vision tokens produced by a single image surges from approximately 256 to approximately 4,096, requiring the batch size to be reduced to 1/16 of the original to maintain GPU memory. InternVL3 (Chen et al. 2024) employs a Dynamic Resolution Bucketing strategy, clustering all training images into approximately 40 predefined resolution buckets by aspect ratio and area; each batch mixes only samples from the same bucket, effectively reducing padding waste and improving overall GPU utilization by approximately 23% [D]. Models begin to be unfrozen at this stage, though most teams still retain some LLM layer freezing to prevent regression in base language capabilities under extreme OCR data distributions.
Stage 3: Supervised Fine-Tuning and Alignment (SFT)
At this stage, data volume drops sharply to the millions or even hundreds of thousands, with the core objective of training the model to adopt a "human conversational register." Data sources include complex logical reasoning tasks (Visual CoT), visual mathematics problems (MathVista (Lu et al. 2023), GeoQA, MathV360K), GPT-4V-synthesized conversation distillation, multi-turn dialogue, and human preference feedback (RLHF/DPO).
SFT imposes the highest data quality requirements of all three stages. Qwen2.5-VL's technical report discloses [D] that human-reviewed high-quality samples account for more than 30% of the SFT data mixture, and any sample receiving an automatic LLM-as-Judge score below 4.0/5.0 is discarded. Simultaneously, in InternVL3's SFT dataset (approximately 1.2M samples, fully open-source), pure natural-scene image-text pairs have fallen below 10%, while OCR-Rich, Grounding, and Chart high-density types collectively exceed 60% [D]—a proportion that would have been unimaginable three years ago. Given the extreme scarcity of high-quality data, synthesis has become the dominant theme of this stage, and is the central subject of the deep-dive in §47.4.
47.2 Cross-Comparison of Mainstream VLM Data Compositions¶
As with pure-text foundation models, the data barriers between multimodal models are equally high. Table 47-1 presents a cross-comparison of data recipes for leading VLMs, derived from the latest technical reports (as of April 2026) and open-source community inferences. This is not merely a compilation of numbers; it reflects each organization's distinct engineering philosophy about what visual intelligence fundamentally requires.
(Note: Annotation convention in the table: [D] = explicitly disclosed in report; [I] = inferred; [E] = estimated.)
Table 47-1: Cross-Comparison of Mainstream VLM Data Compositions (4 rows × 8 columns).
| Model Family | Pre-training Pair Scale | Pre-training Cleaning Strategy | Interleaved Document Ratio | SFT Multimodal Instruction Volume | Video Data Scale | OCR/Doc Specialization | Hi-Res Resolution Support |
|---|---|---|---|---|---|---|---|
| Qwen2.5-VL | ~2B+ Pairs [I] | Proprietary image filtering + rewrite | Very high (~30%) [I] | ~5M+ [E] | Very high, variable-length clips [D] | Strong, multilingual OCR | Native Resolution |
| InternVL 3 | ~1.2B Pairs [D] | Full re-annotation (ShareGPT4V) (Chen et al. 2023) | High (~20%) [I] | ~1.2M (fully open-source) [D] | Moderate, keyframe extraction | Very strong, Chinese-English bilingual | Dynamic Hi-Res |
| LLaVA-OneVision | ~1B Pairs [D] | Relies on existing high-quality open-source datasets | Moderate (~15%) [E] | ~1M (single/multi/video) [D] | Moderate, AnyRes-Video | Moderate | AnyRes Patching |
| MiniCPM-V | ~500M Pairs [E] | Edge-specialized, extreme refinement | High (layout-biased) [I] | ~800K [E] | Weak (biased toward image-text interaction) | Strong, edge-optimized | Adaptive slicing |
From the table above, engineers must internalize the following five underlying trends to avoid repeating data recipe mistakes:
Trend 1: Garbage In, Garbage Out (GIGO) Carries Even Higher Risk in the Visual Domain
Qwen and InternVL no longer trust the text portion of raw crawled image-text pairs. They have expended tens of thousands of GPU hours using prior-generation strong models to re-caption billions of images, yielding performance gains that far exceed the benefit of adding tens of billions of parameters. The LLaVA-OneVision (Li et al. 2024) paper explicitly states [D] that replacing original alt-text with GPT-4V-rewritten captions during pre-training improves MMMU by 4.2 points, whereas adding 50% more data yields only 1.1 points. The leverage effect of data quality is amplified several-fold in the visual domain.
Trend 2: Interleaved Data Is the Bridge to Image-Text Reasoning
Teaching a model to understand a single image and a single sentence is foundational, but enabling a model to parse the logic of image-text interleaving in web page layouts is the next level. The proportion of interleaved document data (e.g., MMC4 (Zhu et al. 2023), OBELICS (Laurençon et al. 2023)) directly determines model performance on in-context learning and long-document reasoning. Qwen2.5-VL's investment in interleaved web data significantly exceeds that of its contemporaries [I], which is a key data-side reason for its lead on complex multi-image reasoning tasks such as MMMU-Pro.
Trend 3: The "Hard Threshold" Effect of OCR and Grounding Data
Not all OCR data linearly improves document understanding. When the proportion of OCR-Rich data in the SFT total falls below 15%, the model's fine-grained text reading capability shows a cliff-edge degradation; when the proportion exceeds 25%, gains plateau but do not reverse [E]. This means OCR data has an "engineering safety threshold"—falling below it severely degrades document capability, while exceeding it yields only marginal returns. InternVL3 maintains OCR-Rich data at approximately 30% of the SFT total [D], precisely landing above this threshold.
Trend 4: Video Data Is Transitioning from "Optional" to "Mandatory"
In the LLaVA-1.5 era, video data was an elite "premium feature" that only a handful of teams pursued. But as Qwen2.5-VL and InternVL3 begin natively supporting long-video understanding, the adequacy of video data has become a key factor in overall capability rankings. Qwen2.5-VL's lead on video understanding benchmarks such as Video-MME and MVBench is substantially attributable to its large-scale variable-length video clip data introduced during pre-training [D], not purely to architectural improvements.
Trend 5: MiniCPM-V's "Edge Data Refinement" Philosophy
MiniCPM-V offers a fundamentally different data recipe paradigm: under constrained overall scale, extreme data quality refinement substitutes for scale expansion. In its SFT data, each sample undergoes dual filtering via "multi-model voting + secondary human review" [I], making the average construction cost per sample more than 5× that of a standard synthetic pipeline. The result: using less than one-fifth the data volume, it achieves performance on typical edge deployment scenarios (document screenshot recognition, multilingual OCR) that approaches or exceeds models with significantly more parameters. This demonstrates that for vertically optimized specific scenarios, the value density of refined data can fully surpass brute-force scaling.
47.3 Key Technical Differences: Native Resolution vs. Dynamic Hi-Res¶
A persistent engineering pain point in the multimodal field is the token explosion caused by high-resolution images. If images are forcibly resized to 224×224, the model becomes "nearsighted" and can never parse the densely arranged text in invoices or mathematical formulas. To address this, two fundamentally divergent processing philosophies have emerged in data pipelines, with the fundamental divergence already manifesting during data preprocessing.
Figure 47-3 illustrates the corresponding workflow or structure.

Figure 47-3: Native vs. Dynamic Resolution Data Pipeline Comparison.
Camp 1: Dynamic Hi-Res Patching (AnyRes)
Represented by InternVL and LLaVA series models. During data input preprocessing, the system keeps the input resolution of the visual encoder (e.g., CLIP-ViT) fixed (e.g., 448×448). For a tall image of 1000×2000, the data engine dynamically crops it into multiple 448×448 patch sub-images without distorting the aspect ratio, while additionally generating a low-resolution global thumbnail.
On the language model side, the input is a special sequence: [Global Thumbnail Token] [Patch 1] [Patch 2] ... [Patch N]. This approach is extremely pragmatic from an engineering standpoint: it directly reuses existing powerful open-source visual encoders (e.g., CLIP-ViT-L/14@336) without modifying any operators, and is fully compatible with standard training frameworks. Data preprocessing scripts are minimal, with the slicing operation for a single image requiring approximately 2ms. The trade-off is semantic discontinuity at patch boundaries: the model may exhibit cross-patch hallucinations when handling extra-large tables spanning patches, continuous mathematical formulas, or landscape-oriented PDFs. InternVL3's technical report candidly acknowledges that on "cross-page table" questions in DocVQA (Mathew et al. 2021), the Dynamic Hi-Res approach has an error rate approximately 8% higher than Native Resolution [D].
Camp 2: Native Resolution (M-RoPE)
Represented by Qwen2-VL and Qwen2.5-VL. These models abandon rigid tiling logic; during the data loading stage, images are allowed to enter directly at their native resolution and native aspect ratio. By introducing M-RoPE (Multimodal Rotary Position Embedding) (Wang et al. 2024), the traditional 1D positional encoding is extended to 2D (x/y coordinates for images) and even 3D (for the temporal dimension t of video). During data organization, only the actual width and height token counts of each image need to be dynamically fed into the attention computation; no padding is required.
This recipe preserves the most complete global and local information, entirely eliminating semantic discontinuity at patch boundaries, and is the highest-precision approach. However, its data engineering complexity is also the highest: training data must be precisely bucketed and packed by token count (rather than image count) to prevent extreme length variance within each batch causing OOM errors. Qwen2.5-VL specifically developed a "token-aware" data packer that constrains the total vision token count per batch within a fixed interval, sacrificing approximately 15% of training throughput in exchange for a near-zero OOM rate [I].
Table 47-2 summarizes the corresponding comparison and engineering considerations.
Table 47-2: Native Resolution vs. Dynamic Hi-Res Data Processing Differences (2 rows × 6 columns).
| Resolution Approach | Representative Model | Image Data Preprocessing Action | Visual Encoder Modification | LLM-side Token Sequence Characteristics | Strengths and Weaknesses |
|---|---|---|---|---|---|
| Native Res. | Qwen2.5-VL | Retain original image, dynamically unfold by patch size | Remove fixed positional embedding | 2D absolute coordinate mapping (M-RoPE) | Highest precision, no boundary discontinuity / Very high engineering complexity, prone to memory fragmentation |
| Dynamic Patching | InternVL3 / LLaVA | Preserve aspect ratio, dynamically crop at equal intervals | No modification needed, can be fully frozen | <global> <patch1> <patch2> linear concatenation |
Simple engineering, compatible with open-source stack / Stitching seam artifacts, introduces redundant computation |
Engineering Selection Guidance: For mid-sized teams or resource-constrained scenarios, Dynamic Hi-Res Patching is the more pragmatic starting point; stitching seam artifacts can be partially mitigated by adding overlap crop (approximately 30% overlap region). If the goal is to target state-of-the-art performance on document understanding benchmarks such as DocVQA and OCRBench, and sufficient engineering compute is available, Native Resolution is an ultimate direction worth the engineering investment. Between the two, there is no absolute superiority—only a reasonable trade-off matched to team resources.
47.4 Multimodal Instruction Data Synthesis¶
At the SFT stage, high-quality instruction data becomes the final piece that determines the model's capability ceiling. Since having humans draw bounding boxes around objects (Grounding) or compose complex visual logic problems is prohibitively expensive, a "synthetic data factory" has become standard practice for leading organizations.

Figure 47-4: Multimodal Instruction Synthesis Pipeline.
As shown in Figure 47-4, multimodal instruction synthesis has long surpassed the simplistic approach of "having GPT-4V look at an image and compose a sentence." A modern data synthesis pipeline typically involves the coordination of the following components:
- Foundational visual perception networks: Use readily available specialized small models—such as Grounding DINO (Liu et al. 2023) to extract all object bounding boxes, PaddleOCR to extract dense text, and even depth estimation models to extract 3D depth information.
- Textual representation: Forcibly translate the perceived visual information into structured plain text (e.g., JSON or Markdown).
- Knowledge recombination with a capable LLM: Feed the text enriched with bounding box and OCR information into a capable language model. Since the image has already been converted to precise text, even a pure-text GPT-4 (rather than GPT-4V) can complete this step—instructing it to generate complex reasoning questions such as: "Based on the invoice total in the upper right corner of the image and the line items on the left, calculate the tax rate."
- Quality filtering and deduplication: Use self-consistency (majority-vote across multiple samples) or LLM-as-Judge to score the quality of synthesized outputs, filtering out samples with severe hallucinations or logical incoherence; also perform semantic-level instruction deduplication to prevent a single image from spawning large numbers of homogeneous question-answer pairs.
Table 47-3 summarizes the corresponding comparison and engineering considerations.
Table 47-3: Comparison of Multimodal Instruction Data Synthesis Methods (3 rows × 5 columns).
| Synthesis Approach | Core Dependent Models | Typical Application Scenarios | Cost Estimate | Noise and Hallucination Risk |
|---|---|---|---|---|
| GPT-4V Distillation | External closed-source VLM API | Complex logical reasoning, long summarization | Very high (API quota dependent) | Relatively low, but constrained by teacher model's inherent biases |
| Self-Distillation Pipeline (Self-Instruct) | Proprietary perception models + open-source strong LLM | Fine-grained object grounding, dense OCR | Moderate (compute amortization) | Relatively high; depends on OCR recall rate, prone to phantom boxes |
| Rule-based Template Generalization | Structured databases (e.g., knowledge graphs) | Simple attribute QA, chart value retrieval | Very low (script generation) | Very low, but poor instruction diversity, stilted language |
Below is the core code framework for a Qwen2.5-VL-style self-distillation caption rewriting pipeline:
Listing 47-1 provides a process flow example.
# Self-distillation caption rewriting core workflow (skeleton outline)
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
from PIL import Image
RECAPTION_PROMPT = (
"Please write a detailed scene description for this image (150-300 words). "
"Cover: the main subject, spatial relationships, color and lighting, "
"any visible text (if present), emotional atmosphere, and possible use scenarios. "
"Do not begin with 'The image shows'."
)
def recaption_batch(image_paths: list[str], model, processor) -> list[str]:
results = []
for img_path in image_paths:
image = Image.open(img_path).convert("RGB")
messages = [{"role": "user", "content": [
{"type": "image", "image": image},
{"type": "text", "text": RECAPTION_PROMPT}
]}]
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=[text], images=[image], return_tensors="pt").to("cuda")
output_ids = model.generate(**inputs, max_new_tokens=512, temperature=0.7)
caption = processor.decode(output_ids[0], skip_special_tokens=True)
results.append(caption)
return results
Listing 47-1: Process flow example.
Key Engineering Notes:
temperature=0.7is a critical parameter for preventing caption mode collapse; values below 0.5 cause generated styles to become homogeneous.- For OCR-Rich images (e.g., invoices, tables), the
RECAPTION_PROMPTshould explicitly require "verbatim reproduction of all visible text in the image" to avoid hallucinations. - It is recommended to mix different image types (natural scenes, documents, charts) within the same batch to prevent the model from overfitting to a single distribution.
- After each batch completes, re-score the relevance between the new captions and images using CLIP-Score (threshold ≥ 0.30); discard low-scoring samples rather than recycling them.
47.5 Specialized Processing for Long Video, Document, and OCR Data¶
As VLMs extend toward complex real-world scenarios, the proportion of static high-quality natural landscape images is gradually declining, replaced by human-made images containing high-density information. Data teams have accumulated a set of reusable engineering best practices for the following three high-information-density variants:
1. Dense Document and OCR Data (Document-Rich Data)
To improve model performance on document and multimodal understanding benchmarks such as DocVQA and MMMU, teams including InternVL and Qwen extensively incorporate financial reports (with dense PDF tables), medical record screenshots, and complex academic posters.
Their processing approach has gone beyond simple image input; it now employs a "text-assisted injection" strategy: before the data stream enters the model, high-resolution images are first passed through a dedicated OCR engine (e.g., PaddleOCR-v4 or the specialized MinerU PDF parser). The extracted plain text is directly encoded as "gold-standard context" at the beginning of the human instruction (e.g., System: This image contains the following text: <OCR>...<OCR>).
Furthermore, data pipelines apply intensive color inversion, grayscale conversion, noise injection (augmentation), and even deliberate text masking or the addition of stain artifacts to the original images. This augmented training strategy aims to reduce the visual encoder's reliance on top-level LLM common-sense completion, forcing it to genuinely learn character recognition from visual features. Once document data falls below 15% of the total, the model's fine-grained text reading capability may show noticeable degradation.
2. Spatio-Temporal Dimensionality Reduction for Long Video Streams
The core challenge of video processing is spatio-temporal information redundancy. Assume a 10-minute supermarket surveillance video is input at 30fps, generating a total of 18,000 frames. Converting all of them into tokens would rapidly exceed current context windows of 128K or even 1M tokens.
Early models (e.g., Video-LLaVA) used a simple "fixed-count frame sampling" strategy (e.g., uniformly extracting 8 or 16 frames regardless of video length). This is adequate for short clips of a few seconds but poorly suited to educational videos spanning tens of minutes. Modern models (e.g., Qwen2.5-VL) now use content-aware dynamic frame rate sampling based on optical flow (Dynamic Optical Flow Sampling).
The data engine first computes pixel-level differences between adjacent frames (e.g., SSIM or Flow-net features). During long static scenes lasting several minutes, the engine may retain only 1 sparse keyframe per period; when rapid motion appears (e.g., the moment of a car accident or a magic card reveal), the engine performs dense sampling multiple times per second and attaches a dedicated temporal marker (<Time-Step=2.1s>) to each image slice. This data pre-packaging technique helps support long-video reasoning training while conserving compute.
3. Multimodal Interleaved Documents (Interleaved Documents / Web Pages)
Most complex human knowledge (e.g., Wikipedia, technical blogs) does not exist as isolated single images or single sentences, but in an interleaved form of "a paragraph of text + a structural diagram + another paragraph of supplementary text + a data table." When constructing high-quality pre-training and alignment data, engineers must write highly complex HTML parsers to strictly serialize a web page's DOM tree.
The core principle is: the physical sequential order of text and images in the token sequence must be preserved exactly. Engineers must treat images as special symbols that occupy a large portion of the token budget, embedding them within the text (e.g., The architecture of Transformers is shown here: <Image_Token_Start>...<Image_Token_End>. Note that the self-attention...). If data cleaning (e.g., removing web page advertisement banners) causes images to become misaligned with their associated text, serious logical confusion will be induced within the model (e.g., a description of a cat becomes paired with an image of a shoe). For this reason, large laboratories typically develop dedicated heuristic interleaved document cleaning toolkits (Interleaved Cleaners).
47.6 Core Case Studies¶
From the current open-source ecosystem, this chapter selects three representative VLM data pipeline reproduction pathways, each corresponding to a different typical engineering starting point: full open-source reproduction, refinement from low-quality data, and reverse-engineering a recipe from large-scale long-video data.
Case A: Full Open-Source SFT Data Reproduction for InternVL3¶
The InternVL team open-sourced not only model weights, but also a million-scale SFT high-quality instruction dataset (InternVL-Chat-V1-5-SFT-1.2M). The data engineering highlight is its fine-grained classification and refinement.
The team partitions training data into multiple subsets: ChartQA (chart analysis), DocVQA (document parsing), MathV360K (mathematical reasoning), LLaVA-Instruct (general daily interaction), ShareGPT4V (high-quality descriptions), and others. During the data packing stage, the training engine ensures that the composition ratio of each type is balanced within each batch, preventing OCR-type data from being overrepresented in batches due to its longer average token length.
Reproduction pathway: Download the InternVL-Chat-V1-5-SFT-1.2M dataset from HuggingFace (CC-BY-4.0 license) and use the open-source training code InternVL2-Training. On 8× A100 GPUs, the SFT stage of InternVL3-8B can be reproduced in approximately 36 hours. Key configuration: Global Batch Size = 512, Learning Rate = 2e-5, image resolution using the Dynamic 448×N scheme with a maximum of 12 patches per image.
Key takeaway: By studying its open-source data composition logic, one can clearly understand "how 1.2M fine-tuning samples enable emergent general visual dialogue capabilities in a frozen backbone that surpass models with significantly more parameters"—the answer lies not in scale, but in the balance of type coverage and the information density of individual samples.
Case B: LAION Refinement and LLaVA-Recap-558K¶
Early LAION datasets contain a large proportion of loosely correlated alt-text (e.g., the image shows a cat, but the text reads "click to buy cat food"). Feeding this directly into a model causes it to learn incorrect image-text correspondences. The open-source community validated an improvement pathway through the LLaVA-Recap-558K project.
Refinement workflow:
- Apply CLIP-Score filtering on LAION-CC-SBU (threshold 0.28), selecting approximately 700K highly relevant image-text pairs from the original approximately 3 million samples.
- Further filter out low-quality images using the LAION-Aesthetics-V2 visual aesthetics scoring model (Schuhmann et al. 2022), retaining approximately 558K.
- Use LLaVA-1.5-13B with a specific system prompt (requiring detailed scene descriptions of 150–250 words) to regenerate captions for all 558K images.
- Recompute CLIP-Score between the new captions and images, applying a secondary filter at a threshold of 0.30 (discarding approximately 5%).
The cost of this secondary refinement is approximately: 558K × 13B model inference cost ≈ approximately 80 GPU hours (single A100). The resulting LLaVA-Recap-558K has become a gold-standard cold-start resource for countless mid-sized VLM teams, with the median CLIP-Score rising from 0.26 in the original to 0.38 [E].
Case C: Engineering Inference of Qwen2.5-VL Long-Video Data Recipe¶
Unlike InternVL's fully open-source approach, Qwen2.5-VL's training data has not been publicly disclosed. However, based on key disclosures in its technical report and community reproduction experiments, we can reasonably infer the core configuration of its long-video data pipeline.
Basis for inference: The Qwen2.5-VL technical report [D] explicitly discloses: (1) video pre-training data uses a "variable-length timestamp" format, with each frame annotated with <|vision_start|> timestamp <|vision_end|> markers; (2) video frame rates use a content-adaptive strategy, with a minimum of 0.5fps for static scenes and a maximum of 2fps for high-motion scenes; (3) training data includes long video clips exceeding one hour (supported by M-RoPE's temporal dimension).
Inferred pipeline:
- Step 1 — Video Sources: Collect raw video material from YouTube (Creative Commons license), Pexels, and a subset of WebVid-10M, categorized by content type (tutorials / documentaries / science communication / event recordings).
- Step 2 — Shot Segmentation: PySceneDetect performs content-diff-based automatic shot segmentation; filter out shots with duration < 3s or > 10 min.
- Step 3 — Frame Sampling: Compute inter-frame SSIM for each shot segment; static segments (SSIM > 0.95) are sampled at 0.5fps; motion segments (SSIM < 0.80) are sampled at 2fps.
- Step 4 — Multi-Frame Captioning: Arrange the keyframes of each shot (typically 4–16 frames) into a "temporal sequence image" and input it into Qwen2.5-VL-7B to generate a temporal description, requiring the description to include timestamps in the format "at second N, the frame shows...".
- Step 5 — Spatio-Temporal Alignment Verification: Use keyword extraction to verify whether temporal words in the caption correspond to actual frame indices (e.g., "camera push-in" must occur within the frame range where the SSIM gradient is rising); misaligned samples are discarded.
Key finding: Community reproduction experiments [E] show that on models with equivalent parameter counts, introducing long-video data with the above spatio-temporal aligned captions improves the Video-MME (long-video subset) score by approximately 6–9 percentage points, while the same duration of random frame sampling improves it by only 2–3 percentage points. The quality of temporal information in captions, not frame count, is the true bottleneck for long-video understanding.
47.7 Implementation Risks, Costs, and Applicability Boundaries¶
When implementing enterprise-grade in-house VLM data recipes, one must consider not only algorithmic design but also the high engineering compute costs and the latent risks that technical reports typically do not fully address. The following seven lessons come from real production post-mortems, not theoretical speculation.
1. Caption Mode Collapse and Hallucination Amplification
During the synthetic data factory stage, if a single teacher model is used to generate synthetic captions at scale, the trained student model is prone to mode collapse. For example, the student model may habitually begin responses with "The image shows...", or may inherit the teacher model's inherent biases—upon seeing someone in a white lab coat, even if the person in the image is a doctor, the model calls them a "scientist." To mitigate this collapse, the synthesis pipeline's prompt library must contain sufficiently diverse template variants, the decoding stage's temperature noise must be actively increased (e.g., Temperature > 0.7 or applying Top-P sampling), and a reward model-based filtering mechanism must be introduced to suppress the cascading amplification of single-model hallucinations.
2. High-Resolution Memory Black Holes and Gradient Throughput Waste (Padding Penalty)
When using Native Resolution to process large batches of non-standard-sized images, if advanced sequence packing algorithms are lacking, images of different aspect ratios will cause extreme length variance within a training batch. To align tensors, the backend must use large amounts of padding to fill voids—these useless padding tokens not only directly cause HBM OOM errors, but also consume significant compute for meaningless zero-gradient backpropagation. The only solution is to introduce variable-length sequence-aware FlashAttention variants (Varlen FlashAttention) (Dao et al. 2022), or to adopt a token-count-based rather than sample-count-based packing strategy.
3. Synthesis API Costs: A Budget Line Item That Requires Independent Accounting
Calling GPT-4V APIs to synthesize high-quality multimodal instructions is not free. Current costs for calling a top closed-source visual API to process a single medium-resolution image (with a prompt) are typically in the range of $0.005 to $0.01 USD. Building a million-scale high-quality instruction dataset may incur direct API expenditures of $5,000 to $10,000. Consequently, a two-level cascade distillation approach—using "proprietary lightweight open-source VLMs for initial screening + large models for validation"—has become an important cost-reduction pathway for industrial-grade data platforms.
4. Image Compliance and Copyright Risks
Unlike plain text, image content exposes source and authorization issues more readily when conducting rights verification and compliance auditing. Crawling high-resolution images containing real human faces, or unauthorized large-scale collection of commercially copyrighted images carrying invisible digital watermarks, may incur serious compliance risks. Any image crawling task entering a production scheduling environment must strictly follow the security audit mechanisms of Ch04 §4.4 and Ch27 (Data Compliance) for face blurring and compliant provenance metadata tagging.
5. The "Seesaw Effect" from Data Type Imbalance
When the proportion of OCR-Rich data exceeds 40%, the model's natural scene understanding capabilities (e.g., landscape description, human emotion recognition) may show noticeable degradation—an effect known in the field as the "seesaw effect." The solution is to introduce a "capability-aware dynamic sampler": at the end of each epoch, use a set of lightweight capability probes (a rapid evaluation set of approximately 50 questions per category) to measure relative scores across capability dimensions, then automatically increase the next-epoch sampling probability for low-scoring categories, dynamically maintaining balance across all capability dimensions.
6. Hidden Distribution Bias in Multilingual OCR Data
For models requiring multilingual OCR support (e.g., Qwen2.5-VL's 29-language coverage), an easily overlooked pitfall is that OCR training data for different languages is highly uneven in font distribution. Chinese has thousands of common fonts, while Arabic training data often covers only 5–10 fonts. When the model encounters out-of-distribution fonts in real scenarios (e.g., Arabic handwriting or variant script forms), OCR recognition rates can plummet from 92% to below 40% [E]. It is recommended to perform font coverage auditing on training data for each language, and to prioritize expanding font diversity for low-coverage languages using font synthesis (Font Synthesis) tools rather than simply appending more image-text pairs.
7. Applicability Boundaries: When Not to Pursue Top-Tier Recipes
Not all scenarios require the complex data recipes of Qwen2.5-VL's caliber. The following three situations warrant considering a downgraded strategy:
- Vertical domain with small data: If the application scenario is highly concentrated (e.g., factory defect inspection image analysis only), using the LLaVA-1.5 two-stage scheme with 300–500 high-quality domain-annotated samples for LoRA fine-tuning often outperforms a full three-stage pipeline with generic data recipes, at a cost more than 100× lower.
- Ultra-low-latency inference: If deployment on edge devices (e.g., mobile phones, embedded chips) is required, prioritize MiniCPM-V's edge data refinement philosophy rather than endlessly stacking interleaved web data.
- Cold-start rapid validation: During the product POC stage, it is advisable to quickly establish a baseline using LLaVA-Recap-558K + LLaVA-Instruct-150K (approximately 24 hours), verify product logic feasibility, and then invest resources in custom data engineering.
Chapter Summary¶
The capability improvements of multimodal VLMs appear on the surface to stem from the synergy of visual and language architectures, but fundamentally depend on systematic data governance. Starting from a real-world data recipe failure incident, this chapter systematically deconstructed four core dimensions of modern leading VLM data recipes:
- Three-stage pipeline (§47.1): Pre-training, multi-task alignment, and SFT have entirely different requirements for data scale, quality, and type; forced mixing across stages is the most common root cause of failure.
- Cross-comparison trends (§47.2): From Qwen2.5-VL and InternVL3 to LLaVA-OneVision and MiniCPM-V, "re-captioning takes priority over alt-text," "interleaved data proportion determines reasoning depth," and "edge refinement philosophy" are three engineering principles that can be directly operationalized.
- Resolution dichotomy (§47.3): Between Native Resolution (the Qwen approach) and Dynamic Hi-Res (the InternVL/LLaVA approach), there is no absolute superiority—only reasonable trade-offs matched to team resources.
- Synthetic data factories (§47.4–§47.5): The self-distillation caption rewriting pipeline, forced OCR injection, and long-video dynamic frame rate sampling strategy are three high-value engineering modules that can be directly reused.
Three case studies (§47.6) provide three different entry pathways: "full open-source reproduction" (InternVL3), "refinement from low-quality data" (LAION-Recap), and "reverse-engineering a recipe from a technical report" (Qwen2.5-VL long video), corresponding to teams with different resource endowments and engineering starting points.
Seven implementation risks (§47.7) reveal engineering details that technical reports generally avoid, with the "applicability boundaries" section in particular reminding readers: the most complex recipe is not necessarily the most suitable one—always prioritize business scenarios and team resource constraints above all else.
Once VLMs have mastered the "visual understanding" capability for both the physical world and two-dimensional surfaces through the high-standard data recipes described in this chapter, they also acquire the foundation for processing visual inputs and driving downstream generative tasks. In the next chapter, Ch48: Data Engineering for Multimodal Generative Models, we shift perspective toward generative tasks, discussing how data recipes will evolve as models transition from "observers" to generators of pixels and video.
References¶
Chen Z, Wu J, Wang W, Su W, Chen G, Xing S, Zhong M, Liu Q, Lu Y, Li B, others (2023) InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks (ShareGPT4V). arXiv preprint arXiv:2312.14238.
Chen Z, Wang W, Tian H, Ye S, Gao Z, Cui E, Tong X, Hu J, Luo J, Ma S, others (2024) InternVL3: Exploring Advanced Training and Test-Time Scaling for Vision-Language Models. arXiv preprint arXiv:2504.10479.
Dao T, Fu D Y, Ermon S, Rudra A, Ré C (2022) FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In: Advances in Neural Information Processing Systems 35:16344-16359. https://doi.org/10.52202/068431-1189.
Gadre S Y, Ilharco G, Fang A, Hayase J, Ilharco G, Marten T, Wortsman M, Goyal S, Guha E, Jain H, others (2023) DataComp: In Search of the Next Generation of Multimodal Datasets. In: Advances in Neural Information Processing Systems 36. Available at: https://arxiv.org/abs/2304.14108.
Laurençon A, Saulnier L, Tronchon L, Bekman S, Singh A, Lozhkov A, Wang T, Karamcheti S, Rush A M, Kiela D, others (2023) OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents. arXiv preprint arXiv:2306.16527.
Li B, Zhang Y, Guo D, Zhang R, Li F, Zhang J, Zhang Y, Zhu P, Zhang Z, Yang J, others (2024) LLaVA-OneVision: Easy Visual Task Transfer. arXiv preprint arXiv:2408.03326.
Liu H, Li C, Wu Q, Lee Y J (2024b) Visual Instruction Tuning (LLaVA-1.5). In: Advances in Neural Information Processing Systems 36.
Liu S, Zeng Z, Ren T, Li F, Zhang H, Yang J, Li C, Yang J, Su H, Zhu J, others (2023) Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. arXiv preprint arXiv:2303.05499.
Lu P, Bansal H, Xia T, Liu J, Li C, Hajishirzi H, Cheng H, Chang K W, Galley M, Gao J (2023) MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts. arXiv preprint arXiv:2310.02255.
Mathew M, Karatzas D, Jawahar C V (2021) DocVQA: A Dataset for VQA on Document Images. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp 2200-2209. https://doi.org/10.1109/wacv48630.2021.00225.
Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, others (2021) Learning Transferable Visual Models from Natural Language Supervision (CLIP). In: Proceedings of the 38th International Conference on Machine Learning, pp 8748-8763.
Schuhmann C, Beaumont R, Vencu R, Gordon C, Wightman R, Cherti M, Coombes T, Katta A, Mullis C, Wortsman M, others (2022) LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Models. In: Advances in Neural Information Processing Systems 35:25278-25294. Available at: https://arxiv.org/abs/2210.08402.
Wang P, Bai S, Tan S, Wang S, Fan Z, Bai J, Chen K, Liu X, Wang J, Ge W, others (2024) Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution. arXiv preprint arXiv:2409.12191.
Yue X, Ni Y, Zhang K, Zheng T, Liu R, Zhang S, Stevens J, Jiang C, Zheng N, Sun T, others (2024) MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 9556-9567. https://doi.org/10.1109/cvpr52733.2024.00913.
Zhu W, Hessel J, Awadalla A, Gadre S Y, Dodge J, Fang A, Yu Y, Schmidt L, Wang W Y, Choi Y (2023) Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved with Text. arXiv preprint arXiv:2304.06939.