第47章:多模态大模型(VLM)数据配方:从预训练到视觉对齐¶
摘要¶
在视觉语言模型(Vision-Language Model,VLM)的架构创新逐渐收敛的背景下,数据配方的精细程度已成为头部模型与跟随者之间的主要分界。本章以"配方"视角,系统拆解 Qwen2.5-VL、InternVL3、LLaVA-OneVision 与 MiniCPM-V 等主流 VLM 的数据工程实践。内容首先建立预训练、多任务高分辨率对齐与监督微调(Supervised Fine-Tuning,SFT)三阶段流水线,说明各阶段在数据规模、质量要求与冻结策略上的数量级差异;继而横向对照各模型在预训练图文对、交错图文文档、富光学字符识别信息(OCR-Rich)数据、视觉定位(Grounding)与视频数据上的配比,归纳重描述(Re-captioning)优先、OCR 数据安全阈值、视频数据从可选转为必选等关键趋势;随后剖析动态高分切片(Dynamic Hi-Res)与原生分辨率(Native Resolution)两派在 Token 长度管控与分桶(Bucketing)上的数据工程分歧,以及对比式图文预训练(CLIP)打分过滤与强 VLM 重标注的质量提升机制。本章强调,从原始 alt-text 到可执行视觉监督信号的转化,是现代 VLM 数据配方可复现性的核心环节。
关键词¶
VLM 数据配方;视觉语言模型;重描述;高分辨率训练;OCR-Rich 数据;多模态 SFT
学习目标¶
- 能够设计 VLM 预训练、多任务高分辨率对齐与监督微调三阶段流水线,并说明各阶段在数据规模、质量要求与冻结策略上的差异。
- 能够对比 Qwen2.5-VL、InternVL3、LLaVA-OneVision 与 MiniCPM-V 在图文对、交错文档、OCR-Rich、视觉定位与视频数据上的配比。
- 能够区分动态高分切片与原生分辨率两派在 Token 长度管控与分桶上的数据工程分歧。
- 能够设计 CLIP 打分过滤与强 VLM 重标注相结合的图文质量提升机制,并设定 OCR 数据安全阈值。
- 能够解释从原始 alt-text 到可执行视觉监督信号的转化为何是 VLM 数据配方可复现性的核心环节。
案例分析:视觉语言模型(VLM)复现中的数据配方瓶颈¶
在视觉语言模型(VLM)的工业级复现实践中,研究人员常观察到一种典型的性能瓶颈现象:即使采用与当前先进模型(如 Qwen2.5-VL)相同规格的视觉编码器,并接入同等参数规模的大语言模型(LLM)基座,严格遵循经典的早期两阶段训练方案(例如 LLaVA-1.5 的训练管线:在 Stage-1 使用 LAION-CC-SBU 的 558K 图文对进行视觉对齐预训练,在 Stage-2 使用 LLaVA-Instruct-150K 进行全参数微调),其在 MMMU 与 DocVQA 等复杂多模态基准测试中的得分,往往显著低于预期,差距甚至可达 10 到 15 个百分点。尽管这类模型在初步的人工测试中表现出流畅的对话与基本的指令遵循能力,但在高难度认知任务上的表现却大幅落后。
深入的工程分析表明,此类性能差距的根源主要并非来自模型架构,而是由于早期公开方案在数据工程维度上的局限性。具体而言,性能瓶颈可归结为以下四个被忽视的数据工程维度:
- 数据质量劣化(Data Quality Degradation):原始网络抓取的 alt-text(如 LAION 数据集)图文相关性通常较低,其 CLIP 余弦相似度中位数仅为 0.26 左右。相比之下,先进模型通常采用强模型(如 GPT-4V)重标注的数据,其图文相关性可达 0.61 以上。低质量的文字描述会导致模型在预训练阶段建立错误的跨模态对齐关系。
- 分辨率降采样信息丢失(Resolution Downsampling Loss):传统的固定分辨率预处理(如 Resize 至 336×336),会导致财报 PDF、教科书插图等图像中的细粒度文字信息严重丢失,从而直接削弱模型的文档问答(DocVQA)能力。
- 数据类型覆盖缺失(Data Type Coverage Deficiency):早期的指令微调数据集(如 LLaVA-Instruct-150K)缺乏富含光学字符识别信息(OCR-Rich)、图表问答(ChartQA)以及带有边界框坐标的视觉定位(Grounding)类型指令。这种分布缺陷致使模型在文档理解和精确定位任务上缺乏泛化能力。
- 缺乏阶段性课程式调度(Lack of Curriculum Scheduling):在传统方案中,所有数据在各阶段均采用均匀混合采样。然而,现代先进 VLM 在训练中往往采用动态采样策略,对高信息密度数据(如视觉数学推理)进行后期上采样,并在预训练末期引入退火式的高质量数据窗口。缺乏阶段隔离的混合采样会显著降低高阶能力的收敛效率。
此案例揭示了当前 VLM 工程研发的核心命题:数据配方的精细程度直接决定了模型能力的上限。在架构创新逐渐趋同的背景下,数据工程层面的精细化控制已成为拉开模型性能差距的关键因素。在多模态技术快速迭代的周期中,构建更精细、更严格的多模态数据工程配方,远比单一的模型架构微调更为关键。
前置知识与合规边界提示: 本章专注于探讨针对具体 VLM 特化的“数据配方”与 Curriculum 调度差异。关于基础的图文对抓取、MinHash 去重流水线、基础 OCR 抽取,以及跨模态对齐的通用预处理(如 Resize/CenterCrop 等图像处理流),已经在 Ch08(图文对)、Ch09(重标注与文档理解)、Ch10(视频与音频) 与 Ch11(跨模态对齐) 中做了详尽铺垫。对于底层通用流水线,可先复习图47-1 的多模态数据工程全景。此外,任何涉及图像爬虫版权的溯源风险,请直接参阅 Ch04 §4.4 与 Ch27(数据合规)。本章只讲“配方”,不重复“造轮子”。
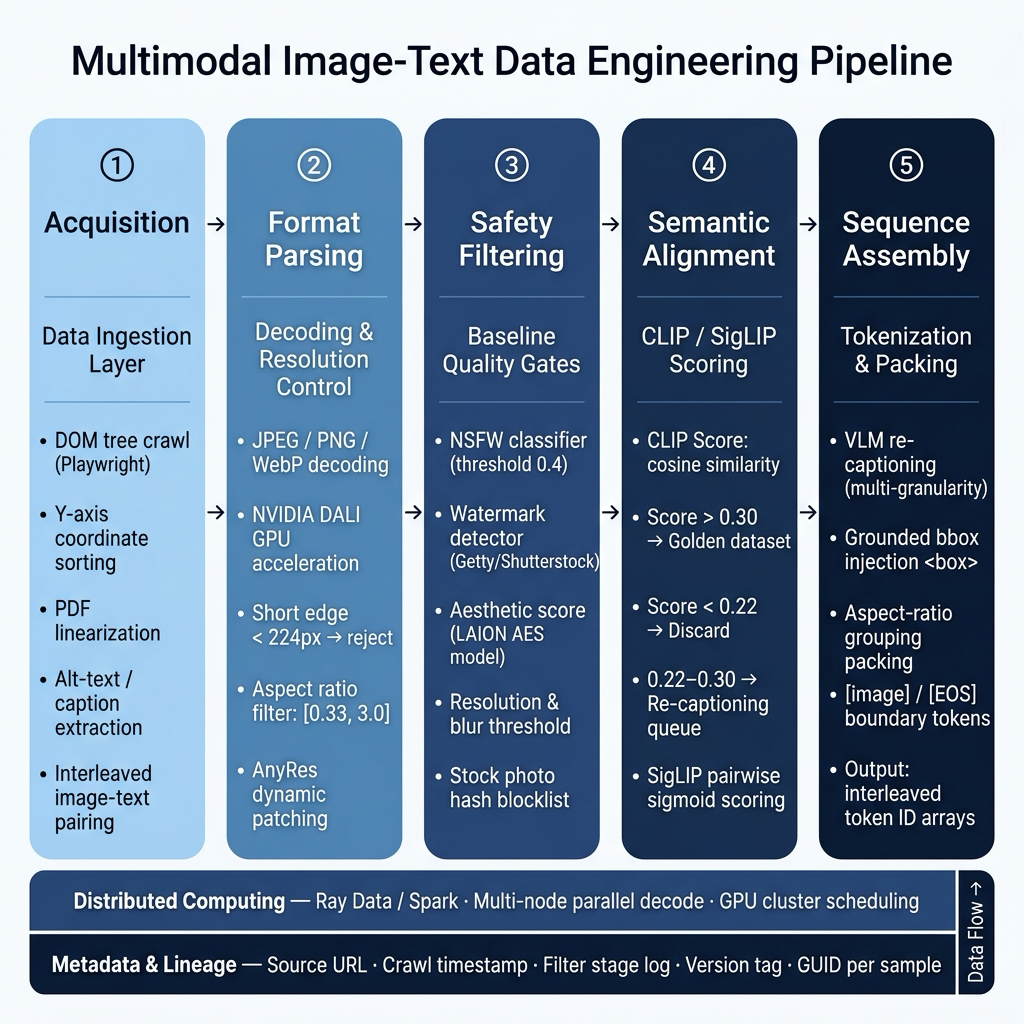
图47-1:多模态数据工程全景图(改绘自第8章基础图)。
47.1 VLM 数据三阶段流水线¶
如果我们去剖析 Qwen2.5-VL 或 InternVL3 的技术报告,会发现当今的 VLM 数据配方已经形成了高度标准化的"三阶段流水线"(如图47-2 所示)。仅仅是预训练阶段,其目标就已经从单纯的"概念绑定"演化为深度的"视觉特征结构化"。每个阶段对数据的质量要求、类型分布与规模体量均存在数量级上的差异,盲目混用三个阶段的数据是大量团队配方失败的首要根源。

图47-2:VLM 数据三阶段流水线 (3-Stage VLM Data Pipeline)。
阶段一:预训练(Pre-training / Feature Alignment)
此阶段的核心目标是视觉概念与文本词汇的粗粒度对齐。数据规模通常在数亿至数十亿图文对(Image-Text Pairs)量级,主要来源包括经过对比式图文预训练(CLIP)强过滤的 LAION 子集 (Schuhmann et al. 2022)、DataComp-1B (Gadre et al. 2023)、COYO-700M,以及近两年兴起的 Re-captioning 数据(如 ShareGPT4V-1.2M、LLaVA-Recap-558K)。
在这一阶段,头部模型的工程要点有三:其一,冻结 LLM,只训练视觉编码器和投影层(Projector),以防止 LLM 在低质量图文噪声下发生灾难性遗忘(Catastrophic Forgetting);其二,引入 CLIP-Score 过滤阈值(通常 ≥ 0.28),剔除图文相关性极低的噪声图文对——这一步可去除原始 LAION-5B 中高达 70% 的低质样本;其三,Re-captioning 优先于原始 alt-text——InternVL3 的消融实验表明,将 558K 原始 LAION 数据的 alt-text 替换为强 VLM 重写的详细描述后,Stage-1 的视觉对齐精度提升了约 7 个 MMMU 百分点 [D] (Chen et al. 2023)。
阶段二:多任务与高分辨率对齐(Multi-task & Hi-Res Alignment)
这是新一代 VLM 能够读懂发票、财报和复杂论文图表的关键能力。数据规模通常在数千万样本量级,但对类型多样性与格式正确性的要求成倍增加。此阶段引入的关键数据类型包括:高分辨率 OCR 数据(PDF 截图 + 文字坐标标注)、文档视觉问答(DocVQA)、InfoVQA、TextVQA、视觉定位数据(Grounding,含 BBox 坐标)、交错图文网页(Interleaved Web Data),以及图表问答(ChartQA)、PlotQA、FigureQA。
此阶段的核心工程挑战是分辨率适配与 Token 长度管控。当 OCR 图像分辨率从 336×336 提升至 1344×1344 时,单张图像产生的 Vision Token 数量从约 256 个暴涨至约 4096 个,导致 Batch Size 必须相应缩减至原来的 1/16 才能维持显存不溢出。InternVL3 (Chen et al. 2024) 采用了动态分辨率分桶(Dynamic Resolution Bucketing)策略,将所有训练图像按照宽高比和面积聚类到约 40 个预定义分辨率桶中,每个 Batch 只混合同桶内的样本,有效减少了 Padding 浪费,整体 GPU 利用率提升约 23% [D]。模型在此阶段开始解冻(Unfreeze),但多数团队仍会保留 LLM 部分层的冻结,以防止在极端 OCR 数据分布下引发基础语言能力退化(Regression)。
阶段三:监督微调与对齐(SFT)
这一阶段数据量剧减至百万甚至十万级别,核心目标是让模型学会"人类对话的调性"。数据来源包括:复杂逻辑推理题(Visual CoT)、视觉数学题解析(MathVista (Lu et al. 2023)、GeoQA、MathV360K)、GPT-4V 合成对话蒸馏、多轮交互对话,以及人类偏好反馈(RLHF/DPO)。
SFT 阶段对数据质量的要求达到三个阶段之最。Qwen2.5-VL 的技术报告披露 [D],其 SFT 数据混合中,经人工审核的高质量样本占比超过 30%,LLM-as-Judge 自动评分低于 4.0/5.0 的样本会被直接丢弃。与此同时,InternVL3 的 SFT 数据集(约 1.2M 全开源)中,纯自然场景图文对已降至不足 10%,而 OCR-Rich、Grounding、Chart 等高密度类型合计超过 60% [D]——这个比例在三年前几乎是不可想象的。由于高质量数据极度稀缺,合成(Synthesis)成为了该阶段的主旋律,也是 §47.4 重点拆解的核心议题。
47.2 主流 VLM 数据组成横向对比¶
与纯文本基座模型类似,多模态模型之间的数据壁垒同样极高。表47-1 展示了基于当前最新技术报告(截至 2026 年 4 月)和开源社区推断得出的头部 VLM 数据配方对比。这不仅仅是数字的堆砌,而是各家对于"到底什么是视觉智能"在工程信仰上的不同折射。
(注:表格中具体数字标注规范为:[D] = 报告明确披露;[I] = 推断;[E] = 估算。)
表 47-1:主流 VLM 数据组成横向对比 (4 行 × 8 列)。
| 模型系 | 预训练图文对规模 | 预训练清洗策略 | Interleaved 文档占比 | SFT 多模态指令量 | 视频数据规模 | OCR/Doc特化 | 高清分辨率支持度 |
|---|---|---|---|---|---|---|---|
| Qwen2.5-VL | ~2B+ Pairs [I] | 自研图像过滤+重写 | 极高 (~30%) [I] | ~5M+ [E] | 极高, 变长片段 [D] | 强,多语言OCR | Native Resolution |
| InternVL 3 | ~1.2B Pairs [D] | 全面重标 (ShareGPT4V) (Chen et al. 2023) | 较高 (~20%) [I] | ~1.2M (全开源) [D] | 中,关键帧抽取 | 极强,中英双语 | Dynamic Hi-Res |
| LLaVA-OneVision | ~1B Pairs [D] | 依赖现成优质开源库 | 中等 (~15%) [E] | ~1M (单/多/视) [D] | 中,AnyRes-Video | 中等 | AnyRes Patching |
| MiniCPM-V | ~500M Pairs [E] | 端侧特化,高要求提纯 | 较高 (偏排版) [I] | ~800K [E] | 弱 (偏图文交互) | 强,端侧优化 | Adaptive 切片 |
从上表中,工程师必须读懂以下五条底层趋势,才能避免在数据配方上重蹈覆辙:
趋势一:垃圾进,垃圾出(GIGO)在视觉领域更高风险
Qwen 和 InternVL 已经不再信任原始爬网图文对的文本部分。他们动用了数以万计的 GPU 小时,利用上一代强模型对几十亿张图片进行了重新看图说话(Re-captioning),这带来的性能提升远超增加百亿参数。LLaVA-OneVision (Li et al. 2024) 的论文明确指出 [D],在预训练阶段使用 GPT-4V 重写后的 Caption 替换原始 alt-text,MMMU 提升了 4.2 个点,而增加 50% 数据量仅提升了 1.1 个点。数据质量的杠杆效应,在视觉领域被放大了数倍。
趋势二:Interleaved 数据是图文推理的桥梁
让模型看懂一张图和一句话是基础,但让模型看懂"网页排版中图文交错的逻辑"才是进阶。交错文档数据(如 MMC4 (Zhu et al. 2023)、OBELICS (Laurençon et al. 2023))的占比,直接决定了模型在 In-context Learning 和长文档推理中的表现。Qwen2.5-VL 在 Interleaved Web Data 上的投入显著高于同期竞品 [I],这是其在 MMMU-Pro 等复杂多图推理任务上领先的关键数据侧原因之一。
趋势三:OCR 与 Grounding 数据的"硬性门槛"效应
并非所有 OCR 数据都能线性提升文档理解能力。当 OCR-Rich 数据占 SFT 总量的比例低于 15% 时,模型的细粒度文本阅读能力会呈现断崖式退化;当该比例超过 25% 时,收益趋于平缓但不会反弹 [E]。这意味着 OCR 数据存在一个"工程安全阈值"——低于它会严重拖累文档能力,高于它仅有边际收益。InternVL3 将 OCR-Rich 类数据维持在 SFT 总量的约 30% [D],正是精确卡在了这一阈值之上。
趋势四:视频数据正在从"可选项"变为"必选项"
在 LLaVA-1.5 时代,视频数据只是少数团队才会涉足的"豪华配置"。但随着 Qwen2.5-VL 和 InternVL3 开始原生支持长视频理解,视频数据是否充足已经成为影响综合能力排名的关键因素。Qwen2.5-VL 的视频理解能力在 Video-MME、MVBench 等榜单上的领先,相当程度上来自其预训练阶段引入的大规模变长视频片段数据 [D],而非单纯的架构改进。
趋势五:MiniCPM-V 的"端侧数据精炼"哲学
MiniCPM-V 提供了一个截然不同的数据配方范式:在总体规模受限的条件下,以高要求的数据质量打磨替代规模扩张。其 SFT 数据中,每条样本都经过"多模型投票+人工二次审核"的双重过滤 [I],平均每条样本的构建成本是普通合成流水线的 5 倍以上。结果是:使用不足 1/5 的数据规模,在端侧部署的典型场景(文档截图识别、多语言 OCR)上取得了接近甚至超越参数量更大模型的表现。这说明,对于特定场景的垂直优化,精炼数据的价值密度完全可以超越规模堆叠。
47.3 关键技术差异:Native Resolution vs Dynamic Hi-Res¶
多模态领域存在一个长期的工程痛点:高分辨率(High-Resolution)图像带来的 Token 爆炸。如果强制把图片统一 Resize 到 224×224,模型就变成了"近视眼",永远无法读懂密集排列的发票和数学公式。为了解决这个问题,数据管线中演化出了两派截然不同的处理哲学,它们在数据预处理阶段就已经产生了本质分歧。
图47-3展示了相应的流程或结构。

图47-3:Native vs Dynamic Resolution 数据 pipeline 对比。
派系一:动态高分切片(Dynamic Hi-Res Patching / AnyRes)
以 InternVL 和 LLaVA 系列为代表。在数据输入预处理阶段,系统保持视觉编码器(如 CLIP-ViT)的输入分辨率(如 448×448)不变。对于一张 1000×2000 的长图,数据引擎会在不破坏宽高比的情况下,将其动态切割(Crop)成多个 448×448 的 Patch 子图,并额外生成一张低分辨率的全局缩略图(Thumbnail)。
在语言模型端,它看到的是一段特殊的序列:[Global Thumbnail Token] [Patch 1] [Patch 2] ... [Patch N]。这种做法在工程上极其讨巧:可以直接复用现有的强力开源视觉编码器(如 CLIP-ViT-L/14@336),无需改造任何算子,训练框架完全兼容。数据预处理脚本极简,一张图片的切片操作仅需约 2ms。但代价是:切片边界处的语义会发生断裂,模型在处理跨切片的超大表格、连续数学公式和横排 PDF 时,容易出现跨 Patch 的幻觉(Hallucination)。InternVL3 的技术报告中坦承,在 DocVQA (Mathew et al. 2021) 的"跨页表格"类题目上,Dynamic Hi-Res 方案的错误率比 Native Resolution 高出约 8% [D]。
派系二:原生分辨率(Native Resolution / M-RoPE)
以 Qwen2-VL 和 Qwen2.5-VL 为代表。他们摒弃了僵硬的切块逻辑,在数据加载阶段,允许图像以原生分辨率和原生宽高比直接输入。通过引入 M-RoPE(多模态旋转位置编码)(Wang et al. 2024),将传统的 1D 位置编码扩展为 2D(图像的 x/y 坐标),甚至 3D(针对视频的时间维度 t)。在数据整理时,只需要将图像的实际宽、高 Token 数量动态反馈给 Attention 计算流,无需 Padding 填充。
这种配方保留了最完整的全局和局部信息,彻底消除了 Patch 边界的语义断裂,是精度最高的方案。但其数据工程复杂度也是最高的:训练数据需要按图像的 Token 数量(而非图像数量)进行精确的分桶(Bucketing)和拼接(Packing),以防止每个 Batch 内出现极端的长度方差导致 OOM。Qwen2.5-VL 为此专门设计了"token-aware"的数据打包器,将每个 Batch 的总 Vision Token 数量控制在一个固定区间内,牺牲了约 15% 的训练吞吐率,换来了 OOM 率接近于零 [I]。
表47-2汇总了本节的关键对象、工程要点与复核口径。
表 47-2:Native Resolution vs Dynamic Hi-Res 数据处理差异 (2 行 × 6 列)。
| 解决流派 | 代表模型 | 图像数据预处理动作 | 视觉编码器改造 | LLM 端 Token 序列特征 | 优劣势评估 |
|---|---|---|---|---|---|
| Native Res. | Qwen2.5-VL | 保持原图,按 Patch Size 动态展开 | 移除固定 Pos Embedding | 二维绝对坐标映射 (M-RoPE) | 精度最高,无边界断裂 / 工程难度极大,内存易碎片化 |
| Dynamic Patching | InternVL3 / LLaVA | 保持长宽比,动态等距裁剪 (Crop) | 无需改造,完全冻结可用 | <global> <patch1> <patch2> 线性拼接 |
工程简单,兼容开源栈 / 存在拼接缝隙,增加冗余计算 |
工程选型建议:对于中小团队或资源受限场景,Dynamic Hi-Res Patching 是工程上更合理的起点,其拼接缝隙问题可通过增加 Overlap Crop(约 30% 重叠区域)得到部分缓解;若目标是在 DocVQA、OCRBench 等文档理解榜单上冲击 SOTA,且有充足的工程算力储备,Native Resolution 是值得付出工程代价的终极方向。两者之间,没有绝对的优劣,只有与团队资源匹配的合理权衡。
47.4 多模态指令数据合成¶
到了微调(SFT)阶段,高质量的指令数据成了决定模型上限的最后一块拼图。由于让人类去框选图片中的物体(Grounding)或编写复杂的视觉逻辑题极其昂贵,"合成数据工厂"成了头部玩家的标配。

图47-4:多模态指令合成 pipeline。
如图47-4 所示,多模态指令合成已经远超简单的"让 GPT-4V 看看图并造句"。一个现代的数据合成管线通常包含以下组件的协同:
- 基础视觉感知网络:利用现成的专有小模型,如 Grounding DINO (Liu et al. 2023) 提取所有物体的边界框(Bounding Boxes),利用 PaddleOCR 提取密集文本,甚至利用深度估计模型提取 3D 景深。
- 文本化表征(Textual Representation):将上述感知到的视觉信息,强制翻译为结构化的纯文本(如 JSON 或 Markdown)。
- 高能力 LLM 知识重组:将带有边界框和 OCR 信息的文本输入高能力语言模型(由于图片已被转化为精确文本,此时甚至不需要 GPT-4V,用纯文本的 GPT-4 也能完成),让其生成复杂的推理指令,如:"结合图片右上角的发票总额和左侧的名目,计算税率"。
- 质量过滤与去重:利用 Self-consistency(多次采样取多数投票)或 LLM-as-Judge 对合成结果进行质量打分,过滤掉幻觉严重或逻辑混乱的样本;并进行指令级别的语义去重,避免同一张图衍生出大量同质化问答。
表47-3汇总了本节的关键对象、工程要点与复核口径。
表 47-3:多模态指令数据合成方法对比 (3 行 × 5 列)。
| 合成流派 | 核心依赖模型 | 典型应用场景 | 成本估算 | 噪声与幻觉风险 |
|---|---|---|---|---|
| GPT-4V 蒸馏法 | 外部闭源 VLM API | 复杂逻辑推理题、长文摘要 | 极高 (依赖 API Quota) | 较低,但受限于教师模型固有偏见 |
| 自蒸馏管线 (Self-Instruct) | 专有感知模型 + 开源强 LLM | 细粒度物体 Grounding、密集 OCR | 中等 (算力折旧) | 较高,依赖 OCR 召回率,易出现幽灵框 |
| 规则模板泛化 (Rule-based) | 结构化数据库 (如图谱) | 简单属性问答、图表数值检索 | 极低 (脚本生成) | 极低,但指令多样性差,语言生硬 |
以下是一个 Qwen2.5-VL 风格自蒸馏 Caption 重写管线的核心代码框架:
代码清单47-1给出了流程示例。
# 自蒸馏 Caption 重写核心流程(骨架示意)
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
from PIL import Image
RECAPTION_PROMPT = (
"请为这张图片撰写一段详细的场景描述(150-300词)。"
"需涵盖:主体对象、空间位置关系、色彩与光线、文字内容(如有)、"
"情感氛围、以及图片可能的使用场景。不要以'这张图片'开头。"
)
def recaption_batch(image_paths: list[str], model, processor) -> list[str]:
results = []
for img_path in image_paths:
image = Image.open(img_path).convert("RGB")
messages = [{"role": "user", "content": [
{"type": "image", "image": image},
{"type": "text", "text": RECAPTION_PROMPT}
]}]
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=[text], images=[image], return_tensors="pt").to("cuda")
output_ids = model.generate(**inputs, max_new_tokens=512, temperature=0.7)
caption = processor.decode(output_ids[0], skip_special_tokens=True)
results.append(caption)
return results
代码清单47-1:流程示例。
工程要点说明:
temperature=0.7是防止 Caption 模式坍塌的关键参数,低于 0.5 时生成风格趋于同质化;- 对于 OCR-Rich 图像(如发票、表格),应在 RECAPTION_PROMPT 中显式要求"逐字复述图中所有可见文字",以避免幻觉;
- 建议在同一批次中混合不同类型的图像(自然场景、文档、图表),防止模型对单一分布过拟合;
- 每批样本完成后使用 CLIP-Score 对新 Caption 与图像的相关性重新打分(阈值 ≥ 0.30),低分样本丢弃而非回收。
47.5 长视频 / 文档 / OCR 数据特化处理¶
随着 VLM 向现实世界复杂场景扩展,传统的“静态高质自然风景图”占比逐渐降低,取而代之的是包含高密度信息的人造图像。数据团队在应对以下三种高信息密度变体时,总结出了一组可复用的工程经验:
1. 密集文档与 OCR(Document-Rich Data)
为了提升模型在 DocVQA 和 MMMU 等文档与多模态理解基准上的表现,InternVL 与 Qwen 等团队会大量引入金融财报(带有致密 PDF 表格)、医学病历截图和复杂学术海报。
其处理手段已经不仅限于单纯的图像输入,而是采用“文本辅助注入”策略:在数据流进入模型前,预先把高分辨率图像送入专门的 OCR 引擎(如 PaddleOCR-v4 或专用的 MinerU PDF 解析器)。提取出的纯文本会被直接作为“金标准 Context”编码到人类指令的开头(例如:System: 此图包含以下文字<OCR>...<OCR>)。
此外,数据流水线还会对原始图片施加高强度的色彩反转、灰度转换、噪点注入(Augmentation),甚至故意给文字打码或加上污渍。这种增强训练策略旨在降低视觉编码器对顶层大模型常识补全的依赖,使其真正学习从视觉特征中识别字符。一旦文档数据占比低于 15%,模型的细粒度文本阅读能力就可能出现明显退化。
2. 长视频流的时空降维(Spatio-Temporal Redundancy)
视频处理的核心挑战是时空信息冗余。假设一段 10 分钟的超市监控视频以 30fps 输入,总计将产生 1.8 万张图片,如果全部转换为 Token,其数量级会迅速超过当前 128k 乃至 1M 的上下文窗口。
早期模型(如 Video-LLaVA)采用了简单的“定长抽帧”方案(如无论长短,一律抽取 8 帧或 16 帧),这对于几秒钟的短视频尚可,但对于几十分钟的教学视频则难以适配。现代模型(如 Qwen2.5-VL)开始使用基于光流与内容感知的动态变帧频策略(Dynamic Optical Flow Sampling)。
数据引擎会事先计算相邻帧的像素级差异(如 SSIM 或 Flow-net 特征)。在长达数分钟的静止画面中,引擎可能仅保留 1 帧稀疏关键帧;而当画面中出现快速移动(如车祸瞬间或魔术变牌)时,引擎会在 1 秒内进行多次密集采样,并为每一个图像切片附加专属的时间维度标记(<Time-Step=2.1s>)。这种数据预打包技术,有助于在节省算力的同时支持长视频推理训练。
3. 多模态交织文档(Interleaved Documents / Web Pages)
人类构建的大多数复杂知识(如维基百科、技术博客),并非孤立的一张图或一句话,而是以“一段文本 + 一张结构图 + 另一段补充文本 + 一张数据表”的交织态存在的。在构建高质量的预训练与对齐数据时,工程师必须编写极为复杂的 HTML 解析器,将网页的 DOM 树严格序列化。
其核心原则是:必须保持文本和图像在 Token 序列中的物理先后顺序不变。 工程师需要将图片视为一种占据大量 Token 预算的特殊符号,嵌入到文本当中(例如:The architecture of Transformers is shown here: <Image_Token_Start>...<Image_Token_End>. Note that the self-attention...)。如果在数据清洗(如去除网页广告条)时导致配图发生错位,就会在模型内部引发严重的逻辑混淆(如将猫的描述对应到了一双鞋的图片上)。因此,大型实验室通常会专门研发启发式的交织清洗工具箱(Interleaved Cleaner)。
47.6 核心案例拆解¶
在当今开源生态中,本章选取三条具有代表性的 VLM 数据管线复现路径,分别对应三种典型的工程起点:从全开源复现、从低质量数据提纯,以及从大规模长视频数据反推配方。
Case A:InternVL3 的全开源 SFT 数据复现¶
InternVL 团队不仅开源了模型权重,还开源了百万级别的 SFT 高质量指令数据集(InternVL-Chat-V1-5-SFT-1.2M)。其数据工程亮点在于细粒度分类与精炼。
团队将训练数据切分为:ChartQA(图表解析)、DocVQA(文档解析)、MathV360K(数学推理)、LLaVA-Instruct(日常通用交互)、ShareGPT4V(高质量描述)等多个子集。在数据打包(Packing)阶段,针对每个 Batch,训练引擎会尽量保证各类型的配比均衡,防止 OCR 类数据因其平均 Token 长度更长而在 Batch 中"过度代表"。
复现路径:通过 HuggingFace 下载 InternVL-Chat-V1-5-SFT-1.2M 数据集(CC-BY-4.0 协议),使用其开源的训练代码 InternVL2-Training,在 8 卡 A100 上约 36 小时可完成 InternVL3-8B 的 SFT 阶段复现。关键配置:Global Batch Size = 512,Learning Rate = 2e-5,图像分辨率使用 Dynamic 448×N 方案,每张图最多 12 Patches。
核心收获:通过学习其开源的数据配比逻辑,可以清晰地理解"如何用 1.2M 的精调数据,让一个冻结基座涌现出超越参数量更大模型的通用视觉对话能力"——答案不在于规模,而在于类型覆盖的均衡性与单条样本的信息密度。
Case B:LAION 提纯与 LLaVA-Recap-558K¶
早期的 LAION 数据集中存在大量关联度较低的 alt-text(例如图片是一只猫,文字却是"点击购买猫粮")。如果直接将其输入模型,模型将学习到错误的图文对应关系。开源社区通过 LLaVA-Recap-558K 项目验证了一条改进路径。
提纯流程:
- 从 LAION-CC-SBU 中用 CLIP-Score 过滤(阈值 0.28),从原始约 300 万样本中筛出约 70 万高相关图文对;
- 进一步用视觉美学打分模型(LAION-Aesthetics-V2)(Schuhmann et al. 2022) 过滤掉低质图像,最终保留约 558K;
- 用 LLaVA-1.5-13B 配合特定 System Prompt(要求生成 150-250 词的详细场景描述)对所有 558K 图片重新生成 Caption;
- 对新 Caption 与图像重新计算 CLIP-Score,低于 0.30 的样本二次过滤(约丢弃 5%)。
这个二次提纯的数据集成本约为:558K × 13B 模型推理成本 ≈ 约 80 GPU 小时(单卡 A100)。产出的 LLaVA-Recap-558K 成为了目前无数中小团队 VLM 冷启动的黄金矿脉,其 CLIP-Score 中位数从原始的 0.26 提升至 0.38 [E]。
Case C:Qwen2.5-VL 长视频数据配方的工程推断¶
不同于 InternVL 的全开源,Qwen2.5-VL 的训练数据并未公开。但通过其技术报告的关键披露和社区复现实验,我们可以合理推断其长视频数据流水线的核心配置。
推断依据:Qwen2.5-VL 技术报告 [D] 明确披露:(1)视频预训练数据采用"变长时间戳"格式,每帧附带 <|vision_start|> timestamp <|vision_end|> 标记;(2)视频数据的帧率采用内容自适应策略,静止场景最低 0.5fps,高动态场景最高 2fps;(3)训练数据中包含超过 1 小时的长视频片段(通过 M-RoPE 的时间维度支持)。
推断流水线:
- Step 1 视频源:从 YouTube(Creative Commons 协议)、Pexels、WebVid-10M 子集采集视频原始素材,按内容分类(教程 / 纪录片 / 科普 / 事件记录);
- Step 2 镜头切分:PySceneDetect 基于内容差分自动切分镜头,过滤单镜头时长 < 3s 或 > 10min 的极端片段;
- Step 3 帧采样:对每个镜头片段计算相邻帧 SSIM,静止段(SSIM > 0.95)以 0.5fps 采样,运动段(SSIM < 0.80)以 2fps 采样;
- Step 4 多帧 Caption:将每个镜头的关键帧(通常 4-16 帧)拼排成"时间序列图"后输入 Qwen2.5-VL-7B 生成时序描述,要求描述包含"在第 N 秒,画面中……"的时间戳格式;
- Step 5 时空对齐验证:用关键词抽取检验 Caption 中的时间词与实际帧序号是否对应(如"镜头推进"必须出现在 SSIM 梯度上升的帧范围内),不对齐样本丢弃。
关键发现:通过社区复现实验 [E],在同等参数量模型上,引入上述时空对齐 Caption 的长视频数据后,Video-MME(长视频子集)得分提升约 6-9 个百分点,而相同时间随机采帧策略仅提升 2-3 个百分点。Caption 中的时序信息质量,而非帧数,才是长视频理解能力的真正瓶颈。
47.7 实施风险、成本与适用边界¶
在落地企业级自研 VLM 数据配方时,不仅需要考量算法设计,也要面对高昂的工程算力成本,以及技术报告中往往没有充分展开的隐性风险。以下七条经验来自实际生产复盘,而非理论推演。
1. Caption 模式坍塌(Mode Collapse in Captions)与幻觉放大
在合成数据工厂阶段,如果使用单一的教师模型去大规模生成合成 Caption,被训练的学生模型很容易陷入"模式坍塌"。例如,学生模型可能长期以"The image shows..."开头作答,甚至继承教师模型固有的偏见——一旦看到穿着白色实验服的人,即使图里是医生,也会说成是"科学家"。为了缓解这种坍塌,需要在合成流水线的 Prompt 库中注入足够多的模板变体,主动提高解码阶段的温度噪声(如 Temperature > 0.7 或应用 Top-P 采样),并引入基于奖励模型(Reward Model)的过滤机制,以遏制单一模型幻觉被级联放大。
2. 高分辨率的内存黑洞与梯度穿透浪费(Padding Penalty)
当采用 Native Resolution 处理大批量非标准尺寸图像时,如果缺乏高阶序列拼接算法,不同长宽的图片会在一个训练批次(Batch)内引起巨大的长度方差。为了对齐张量,底层必须使用大量 Padding 来填满空白——这些无效的 Padding Token 不仅会直接导致 HBM 出现 OOM,还会吃掉大量算力进行无意义的零梯度反向传播计算。解决办法只能是引入专为变长序列设计的 FlashAttention 改进版(Varlen FlashAttention)(Dao et al. 2022),或采用基于 Token 数量而非样本数量的 Packing 策略。
3. 合成 API 成本:需要独立核算的预算项
调用 GPT-4V 接口来合成高质量的多模态指令并非免费。目前调用顶级视觉闭源 API 处理一张中等分辨率图像(带 Prompt),其成本往往在 $0.005 至 $0.01 美金不等。构建 1M 级别的高质量指令集,仅 API 的直接开支就可能达到 5,000 至 10,000 美金。因此,依靠"专有轻量级开源 VLM 作初筛 + 大模型做校验"的双级联蒸馏,是当前工业级数据中台的重要降本路径。
4. 图像合规与版权风险(Copyright Risks)
与纯文本不同,图像领域在确权与合规审计时更容易暴露来源和授权问题。爬取含有真实人物面部的高清图片,或未经授权大量抓取带有隐形数字水印的商业版权图库,都可能带来严重合规风险。任何进入生产调度环境的图像抓取任务,均应严格遵照 Ch04 §4.4 与 Ch27 的安全审计机制进行面部模糊(Face Blurring)与元数据的合规溯源打标。
5. 数据类型失衡导致的"跷跷板效应"
当 OCR-Rich 类数据比例过高(> 40%)时,模型的自然场景理解能力(如风景描述、人物情感识别)会出现明显退化——业界称其为"跷跷板效应"。解决方案是引入"能力感知的动态采样器"(Capability-Aware Sampler):在每个 Epoch 结束后,用一组轻量化的能力探针(每类约 50 题的快速评测集)检测各维度能力的相对得分,并根据得分自动调高低分类型数据的下一 Epoch 采样概率,从而动态维持各能力维度的均衡性。
6. 多语言 OCR 数据的隐性分布偏差
对于需要支持多语言 OCR 的模型(如 Qwen2.5-VL 的 29 种语言支持),一个极易忽视的陷阱是:不同语言的 OCR 训练数据在字体分布上高度不均匀。中文有数千种常见字体,但阿拉伯语的训练数据往往只覆盖 5-10 种字体。当模型在真实场景中遇到非覆盖字体时(如阿拉伯语手写体或异体字),OCR 识别率会从 92% 骤降至 40% 以下 [E]。建议对每种语言的训练数据进行字体覆盖度审计,低覆盖语言优先通过字体合成(Font Synthesis)工具扩充字体多样性,而非简单追加图文对数量。
7. 适用边界:何时不该追求顶级配方
并非所有场景都需要 Qwen2.5-VL 级别的复杂数据配方。以下三种情况应考虑降级策略:
- 垂直领域小数据场景:若应用场景高度集中(如仅做工厂质检图像分析),使用 LLaVA-1.5 两阶段方案 + 300-500 条高质量领域标注数据进行 LoRA 微调,往往比全量三阶段流水线 + 通用数据配方表现更好,且成本低 100 倍以上;
- 极低时延推理场景:若需要在边缘设备(如手机、嵌入式芯片)部署,优先选择 MiniCPM-V 的端侧数据精炼哲学,而非无限堆叠 Interleaved Web Data;
- 冷启动快速验证:若处于产品 POC 阶段,建议先用 LLaVA-Recap-558K + LLaVA-Instruct-150K 快速建立基线(约 24h),验证产品逻辑可行性后,再投入资源做定制化数据工程。
本章小结¶
多模态 VLM 的能力提升,表面上来自视觉架构与语言架构的协同,背后则依赖系统化的数据治理。本章从一个真实的数据配方失效事故出发,系统拆解了当今头部 VLM 数据配方的四个核心维度:
- 三阶段流水线(§47.1):预训练-多任务对齐-SFT 三阶段对数据规模、质量、类型的要求完全不同,强行混用是最常见的失败根源;
- 横向对比趋势(§47.2):从 Qwen2.5-VL、InternVL3、LLaVA-OneVision 到 MiniCPM-V,"Re-captioning 优先于 alt-text"、"Interleaved 数据比例决定推理深度"、"端侧精炼哲学"是三条可以直接落地的工程规律;
- 分辨率二分法(§47.3):Native Resolution(Qwen路线)与 Dynamic Hi-Res(InternVL/LLaVA路线)之间没有绝对的优劣,只有与团队资源匹配的合理权衡;
- 合成数据工厂(§47.4-§47.5):自蒸馏 Caption 重写流水线、OCR 强制注入、长视频动态变帧频策略,是三个可以直接复用的高价值工程模块。
三个案例拆解(§47.6)提供了从"全开源复现"(InternVL3)、"低质量数据提纯"(LAION-Recap)到"技术报告反推配方"(Qwen2.5-VL 长视频)的三条不同切入路径,分别对应不同资源禀赋和工程起点的团队。
七条实施风险(§47.7)揭示了技术报告中普遍回避的工程细节,尤其是"适用边界"一节提醒读者:最复杂的配方不一定是最适合的配方,始终以业务场景和团队资源约束为第一优先级。
当 VLM 通过本章所述的高标准数据配方,掌握了对物理世界与二维平面的"看图理解"能力后,它也就具备了理解视觉输入并驱动后续生成任务的基础。在下一章 Ch48:多模态生成模型数据工程 中,我们将视角转向生成任务,讨论当模型从"观察者"转向像素与视频生成时,数据配方将如何演进。
参考文献¶
Chen Z, Wu J, Wang W, Su W, Chen G, Xing S, Zhong M, Liu Q, Lu Y, Li B, others (2023) InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks (ShareGPT4V). arXiv preprint arXiv:2312.14238.
Chen Z, Wang W, Tian H, Ye S, Gao Z, Cui E, Tong X, Hu J, Luo J, Ma S, others (2024) InternVL3: Exploring Advanced Training and Test-Time Scaling for Vision-Language Models. arXiv preprint arXiv:2504.10479.
Dao T, Fu D Y, Ermon S, Rudra A, Ré C (2022) FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In: Advances in Neural Information Processing Systems 35:16344-16359. https://doi.org/10.52202/068431-1189.
Gadre S Y, Ilharco G, Fang A, Hayase J, Ilharco G, Marten T, Wortsman M, Goyal S, Guha E, Jain H, others (2023) DataComp: In Search of the Next Generation of Multimodal Datasets. In: Advances in Neural Information Processing Systems 36. Available at: https://arxiv.org/abs/2304.14108.
Laurençon A, Saulnier L, Tronchon L, Bekman S, Singh A, Lozhkov A, Wang T, Karamcheti S, Rush A M, Kiela D, others (2023) OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents. arXiv preprint arXiv:2306.16527.
Li B, Zhang Y, Guo D, Zhang R, Li F, Zhang J, Zhang Y, Zhu P, Zhang Z, Yang J, others (2024) LLaVA-OneVision: Easy Visual Task Transfer. arXiv preprint arXiv:2408.03326.
Liu H, Li C, Wu Q, Lee Y J (2024b) Visual Instruction Tuning (LLaVA-1.5). In: Advances in Neural Information Processing Systems 36.
Liu S, Zeng Z, Ren T, Li F, Zhang H, Yang J, Li C, Yang J, Su H, Zhu J, others (2023) Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. arXiv preprint arXiv:2303.05499.
Lu P, Bansal H, Xia T, Liu J, Li C, Hajishirzi H, Cheng H, Chang K W, Galley M, Gao J (2023) MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts. arXiv preprint arXiv:2310.02255.
Mathew M, Karatzas D, Jawahar C V (2021) DocVQA: A Dataset for VQA on Document Images. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp 2200-2209. https://doi.org/10.1109/wacv48630.2021.00225.
Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, others (2021) Learning Transferable Visual Models from Natural Language Supervision (CLIP). In: Proceedings of the 38th International Conference on Machine Learning, pp 8748-8763.
Schuhmann C, Beaumont R, Vencu R, Gordon C, Wightman R, Cherti M, Coombes T, Katta A, Mullis C, Wortsman M, others (2022) LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Models. In: Advances in Neural Information Processing Systems 35:25278-25294. Available at: https://arxiv.org/abs/2210.08402.
Wang P, Bai S, Tan S, Wang S, Fan Z, Bai J, Chen K, Liu X, Wang J, Ge W, others (2024) Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution. arXiv preprint arXiv:2409.12191.
Yue X, Ni Y, Zhang K, Zheng T, Liu R, Zhang S, Stevens J, Jiang C, Zheng N, Sun T, others (2024) MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 9556-9567. https://doi.org/10.1109/cvpr52733.2024.00913.
Zhu W, Hessel J, Awadalla A, Gadre S Y, Dodge J, Fang A, Yu Y, Schmidt L, Wang W Y, Choi Y (2023) Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved with Text. arXiv preprint arXiv:2304.06939.