Front-Matter Guide: Publication Structure and Reading Paths¶
1. Positioning and Contributions of This Book¶
This book addresses data engineering problems in the era of large models. It discusses the complete process by which data moves from raw material into training, evaluation, applications, platform governance, and long-term asset accumulation. The Chinese mainline is the authoritative source version. The current publication structure is frozen as 14 parts, 48 chapters, 15 projects, and 8 appendices (A-H). The English manuscript is maintained as the translation and external-submission preview version; terminology, contributor metadata, and publisher-managed metadata should still be verified before final delivery.
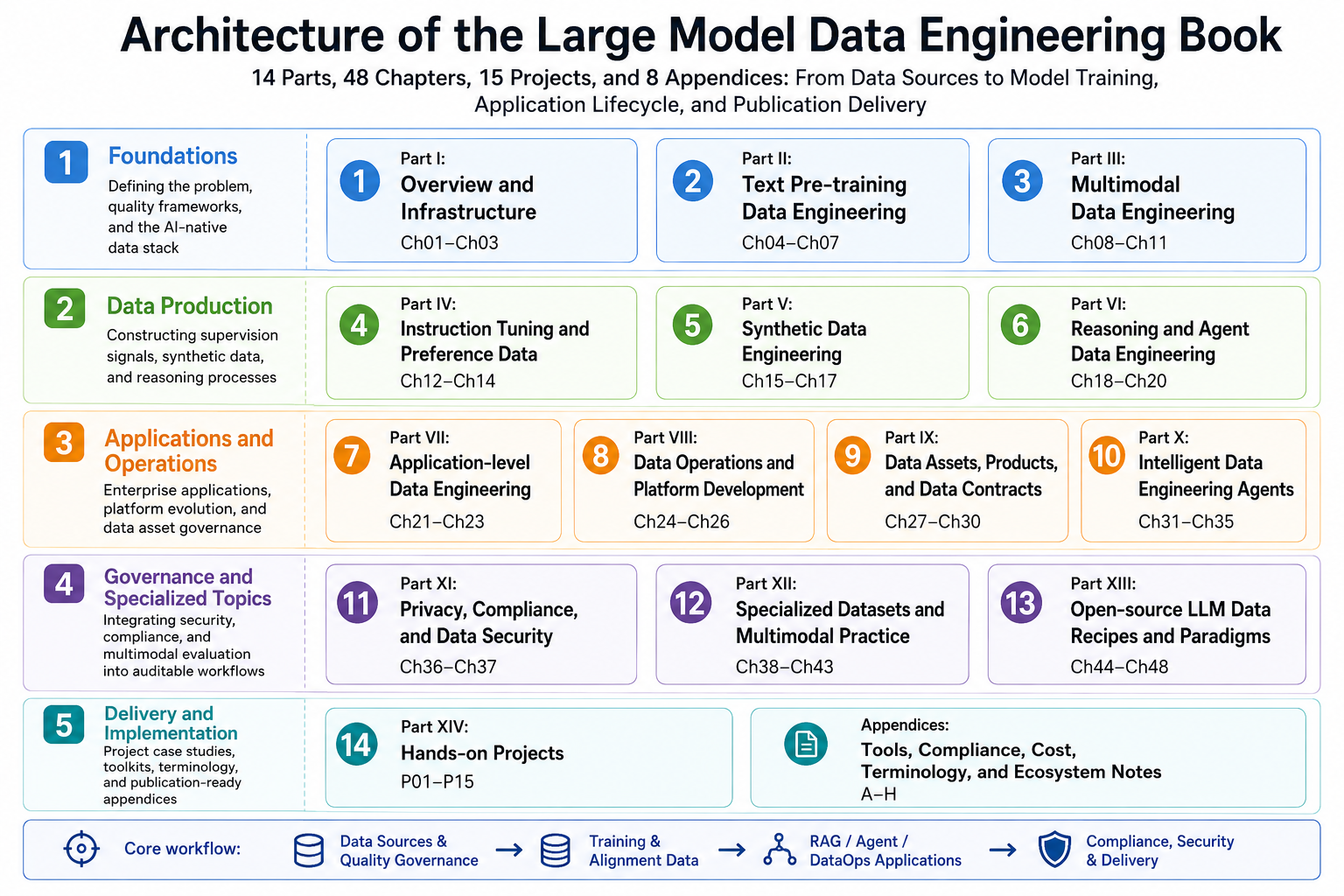
Book architecture. Source: original illustration by the authors. The figure organizes the fourteen parts, forty-eight chapters, fifteen projects, and eight appendices around the data lifecycle, with layers for foundations, collection and processing, cross-cutting capabilities, model alignment, application governance, security and compliance, specialized practice, and project delivery.
The book's core contributions appear in four areas.
First, it establishes a unified framework for large-model data engineering. The book does not treat pre-training corpora, SFT, preference data, multimodal data, RAG, agents, DataOps, and compliance governance as separate topics. Instead, it places them inside one data lifecycle.
Second, it moves data engineering from script-level experience toward deliverable methods. The chapters emphasize data objects, schemas, quality signals, figure and table sources, references, version records, and acceptance metrics, so readers can judge whether a data task is reviewable, reproducible, and maintainable.
Third, it brings open-source model recipes and specialized dataset cases into one narrative. Part 12 provides specialized dataset cases, Part 13 abstracts data recipes for open-source models, and Part 14 validates earlier methods through project cases, forming a closed loop from method and evidence to engineering review.
Fourth, it provides delivery templates for courses, research, and industrial projects. The appendices on tools, compliance, cost, and delivery checklists support project initiation, experiment reproduction, publication review, and team collaboration.
2. Target Readers¶
This book primarily serves four groups of readers.
Graduate students, PhD students, and lab members can use the book to build the data engineering capabilities required for dataset construction, model reproduction, paper experiments, and public release.
Data engineers, algorithm engineers, and platform teams can use the book to organize the engineering chain from data sources, cleaning, alignment, and training packaging to DataOps, evaluation write-back, and data assetization.
Course instructors, teaching assistants, and training organizers can use the book to organize lab courses, course projects, and team bootcamps, while using the appendix templates to reduce uncertainty in reproduction and grading.
Project managers, compliance owners, and collaboration leads can use the book to identify version, permission, figure-source, citation-evidence, cost-budget, and delivery risks in data projects.
3. Organization Logic of the Book¶
The book follows the sequence "data raw material -> training signals -> application systems -> platform governance -> specialized validation -> recipe abstraction -> project review."
Parts 1 to 3 form the foundation layer. They discuss the data lifecycle, infrastructure, text data, multimodal images, video, audio, OCR, and cross-modal alignment. This layer establishes shared terminology and the quality framework for the whole book.
Parts 4 to 6 form the training-signal layer. They cover instruction fine-tuning, preference data, QA data, synthetic data, distillation, reasoning chains, tool use, and agent interaction data. This layer answers how data is transformed from raw material into trainable supervision signals.
Parts 7 to 11 form the systems and governance layer. They cover RAG, multimodal retrieval, online feedback, DataOps, version tracking, data products, internal data markets, Data Engineering Agents, privacy compliance, and federated learning. This layer places data engineering inside real systems, organizational collaboration, and risk boundaries.
Part 12 is the specialized-dataset and multimodal data-engineering validation layer. It follows text corpora, image-text candidate pools, visual documents and tables, visual reasoning, speech and audio, and reasoning traces to test how earlier methods apply to concrete data objects.
Part 13 is the open-source model data-recipe layer. Around paradigms such as pre-training, post-training, RL/reasoning, VLM, and T2I/T2V, it abstracts long-term transferable data organization methods instead of remaining at the level of experience around one hot model.
Part 14 is the project case-study layer. Fifteen projects correspond to key capabilities from the first thirteen parts. The project chapters use case-study writing and focus on scenario constraints, architecture decisions, sample schemas, acceptance metrics, cost risks, failure modes, and reproduction resources.
Appendices A-H provide templates and notes for tools, compliance, cost, engineering conversion, debugging, terminology, the DataGallery open-source ecosystem, and MindSpore overview. They support publication delivery, course reproduction, and team project management.
4. Suggested Reading Paths¶
For readers focused on research and paper experiments, start with Part 1, Part 2, or Part 3, then enter Parts 4 to 6 according to the task. When a project needs public datasets, benchmarks, or reproducible experiments, focus on Part 12 and the appendices.
For industrial platform and data teams, start with Part 1, Part 7, Part 8, and Part 9, then read Part 10, Part 11, and the platform and compliance projects in Part 14.
For readers focused on open-source model reproduction and training recipes, start with Part 13 to establish recipe coordinates, then return to Parts 4 to 6 and use Part 14 projects P11-P15 for case comparison.
For course and teaching organizers, start with Part 1, Part 8, Part 12, Part 14, and the appendices. This path makes it easier to form lab exercises, grading criteria, data-permission notes, and cost budgets.
For project management and delivery review, prioritize Part 1, Part 8, Part 9, Part 11, Part 12, and the publication-management files. This path is better suited to checking structure, permissions, citations, figures and tables, costs, and delivery boundaries.
5. Figures, References, and Companion Resources¶
Figures and tables in this book explain processes, compare structures, support decisions, and assist quality checks. During publication delivery, every figure or table should have a number, title, first in-text reference, source note, alt text, and permission status. Generative AI images whose publishability cannot be confirmed should be redrawn as human diagrams or code-generated figures.
References support external facts, method sources, open-source model recipes, and tool choices. Each chapter's references should be directly connected to the chapter's argument, rather than stacked as a generic reading list.
Companion resources include project code, check scripts, sample data, run instructions, cost templates, and delivery checklists. The main text keeps key structures and short code snippets, while long scripts, notebooks, large files, and intermediate artifacts should be placed in the companion repository or documented in appendices.
6. Version Notes and Citation Suggestions¶
This delivery version uses the Chinese mainline as the authority. When citing the book, record the language, manuscript version, chapter number, project number, and access date. When citing figures, tables, appendix templates, or project artifacts, also include the file location and version note.
Version changes can be divided into three categories. Minor revisions include typos, awkward sentences, and local wording improvements. Medium revisions include navigation, references, figure/table numbering, and chapter metadata adjustments. Major revisions include chapter structure, project count, appendix scope, and substantial rewrites. Course reproduction, paper writing, and project delivery should prioritize structurally frozen versions.
7. Front-Matter Summary¶
The role of this front-matter guide is not to repeat the table of contents. It explains why the book is organized in its current structure, how different readers can enter it, how main chapters and projects support one another, and how versions, figures, references, and companion resources should be understood during publication delivery.
The reading focus of the book should shift from "learning more topics" to "building deliverable data engineering judgment." When readers can use the book's framework to examine the data sources, schemas, quality signals, experiment metrics, compliance boundaries, and reproduction materials of a real project, this front-matter guide has fulfilled its role as the publication entry point.