第43章:推理轨迹数据工程:长链压缩、隐式计算与监督掩码¶
摘要¶
本章以 Latent-Switch-69K 为案例,讨论推理轨迹数据如何从显式 Long-CoT 转向可压缩、可监督、可迁移的隐式计算记录。章节重点关注 teacher trace、latent budget、student sequence、supervision mask、压缩边界和质量控制,说明推理轨迹不是普通文本字段,而是连接推理模型、后训练、RL 数据工程和推理飞轮的关键数据资产。章节还结合 Latent-Switch MindSpore 数据管线,说明已蒸馏记录如何被转换为 mindspore.dataset.GeneratorDataset 可消费的训练 batch。
关键词¶
推理轨迹;Long-CoT;Latent-Switch-69K;隐式计算;监督掩码;推理数据工程
Latent-Switch-69K:推理轨迹压缩与隐式计算槽位¶
学习目标¶
通过本章学习,读者应能够:
- 理解 Long-CoT 在 token 成本、显式过程监督与推理效率上的工程约束,以及为何需要被压缩。
- 掌握 solution intuition、compressed CoT、latent placeholder 与 answer mask 在 latent-then-explicit 样本中的角色。
- 设计 latent budget、student sequence 与 supervision masks 之间的 mask 不变量与一致性检查。
- 评估推理数据压缩中的答案一致性、验证充分性、压缩边界与领域偏置等风险。
- 将 latent-switch 的隐藏规划与显式验证分离思想迁移到数学、代码与复杂指令等自有数据场景。
43.1 开篇问题场景:Long-CoT 为什么还需要被压缩¶
第18章到第20章已经讨论 Chain-of-Thought、工具调用轨迹和 Agent 交互数据的基本形态。对推理模型而言,长思维链具有明确吸引力:模型把中间步骤写出来,训练者就能检查它是否在按某种可解释的路径解题,推理时也更容易通过自洽采样、验证器或过程奖励模型发现错误。然而,当 Long-CoT 从研究样例变成训练语料时,问题会立刻变得工程化。
第一,长 CoT 的 token 成本很高。数学、代码和科学问题中的推导往往占据输出的大部分长度,真正的最终答案只占很小一段。如果所有中间推理都以可见文本形式进入训练和推理,模型需要在大量重复、展开、试探和自我修正的文字上消耗上下文窗口、训练显存和推理时间。第二,长 CoT 并不天然等于高质量推理。有些轨迹只是把简单结论拆得很细,有些轨迹包含错误分支,有些轨迹会在最终答案正确的情况下写出冗余甚至不一致的中间解释。第三,普通 SFT 很难区分“应该被模型内化的高层解题意图”和“必须显式写给用户看的验证过程”。如果把全部 CoT 当作普通目标 token,模型学到的往往是长篇展开的写作习惯,而不是更有效的推理调度方式。
Latent-Switch-69K 正是在这个问题背景下出现的。它不是一个简单的“更短 CoT 数据集”,也不是把 Long-CoT 样本做摘要后直接用于 SFT。它服务的是 LaTER 这类 latent-then-explicit reasoning 系统,而 Latent-Switch MindSpore 则把其中的数据加载、span 物化和 mask 构造落到 MindSpore 数据管线中:模型先经过一段有边界的 latent reasoning 区间,在连续隐状态中完成高层规划和压缩思考,然后切换回可见文本,用较短的显式 CoT 做符号验证,最后生成答案。数据工程目标因此发生了变化:样本不仅要回答“答案是什么”,也要回答“哪些内容适合成为隐藏规划预算,哪些内容仍需要作为可见验证监督”。
图43-1展示了相应的流程或结构。

图43-1:Latent-Switch-69K 将 Dolci-Think-SFT-32B 的推理轨迹蒸馏为 solution intuition、压缩 CoT、latent budget、student sequence 和 mask 对齐后的 SFT 记录。
本章承接第五篇的合成数据工程和第六篇的推理数据工程。第15章到第17章讨论如何生成、蒸馏和质检高质量训练样本,第18章讨论显式 CoT 的组织方式,第19章和第20章讨论工具与 Agent 轨迹中“中间状态”的记录方式。Latent-Switch-69K 则把这些线索推进到一个更细的层次:中间推理不一定都要以自然语言存储,数据集也可以显式为隐藏计算预留槽位。向后看,它会自然连接到第45章的后训练数据配方、第46章的 RL 推理数据工程,以及第十四篇 P06、P10、P12 中的推理飞轮项目。
43.2 数据集概览:规模、难度与领域构成¶
Latent-Switch-69K 数据集的最终训练 split 包含 69,745 条样本。每条保留样本包含一个用户问题、一个蒸馏出的 solution intuition、一段缩短后的显式 CoT、最终答案、latent-step 元数据,以及用于决定不同 token 区间监督方式的 mask。这个结构决定了它与普通 CoT/SFT 数据的差异:普通 SFT 记录通常只需要 prompt 和 assistant output,普通 CoT 数据通常只需要把 reasoning 和 answer 写在 <think> 或自然语言段落中;Latent-Switch-69K 还需要记录一个用于隐藏规划的预算,并把这个预算渲染成 student sequence 中的 latent placeholder。
难度分布上,数据集并没有追求完全均匀。中等难度样本占主要部分,共 45,650 条,占 65.5%;困难样本 17,428 条,占 25.0%;简单样本 6,667 条,占 9.5%。这种分布对 latent-switch 训练有明确意义。中等难度问题通常需要真实推理,不是模板化问答,但又不至于让蒸馏过程过度不稳定。困难样本提供更长、更复杂的推理链,让模型接触更高预算的隐式规划场景。简单样本则帮助模型保留短回答和直接验证的能力,避免所有样本都被塑造成长推理任务。
表43-1汇总了该数据集的规模、难度分布、压缩率和 latent steps 统计。
表43-1:Latent-Switch-69K 的规模、难度与领域构成概览。
| 统计项 | 数值 | 占比 / 说明 |
|---|---|---|
| Total examples | 69,745 | 100.0% |
| Easy | 6,667 | 9.5% |
| Medium | 45,650 | 65.5% |
| Hard | 17,428 | 25.0% |
| Compression ratio mean | 0.612 | distilled CoT length / original CoT length |
| Compression ratio median | 0.569 | 中位样本保留约 56.9% 的显式推理长度 |
| Latent steps mean | 41.49 | 每条样本平均 latent placeholder 数量 |
| Latent steps median | 40.00 | 中位样本约 40 个 latent steps |
领域构成上,Latent-Switch-69K 明显偏向 reasoning-intensive 任务。数学问题约占 37%,代码问题约占 34%,science-oriented questions 约占 5%,剩余部分主要来自 instruction-following 和 general knowledge prompts。这个比例不是偶然的。latent-then-explicit reasoning 最需要解决的是“有高层解题计划,但不希望把所有推导都展开”的任务;数学和代码恰好具有强验证性、强步骤性和较高 token 成本。科学问题提供概念推理和多条件判断场景,而通用指令与知识类样本让模型不至于只学习到竞赛数学或代码补全的表达模式。
图43-2展示了相应的流程或结构。
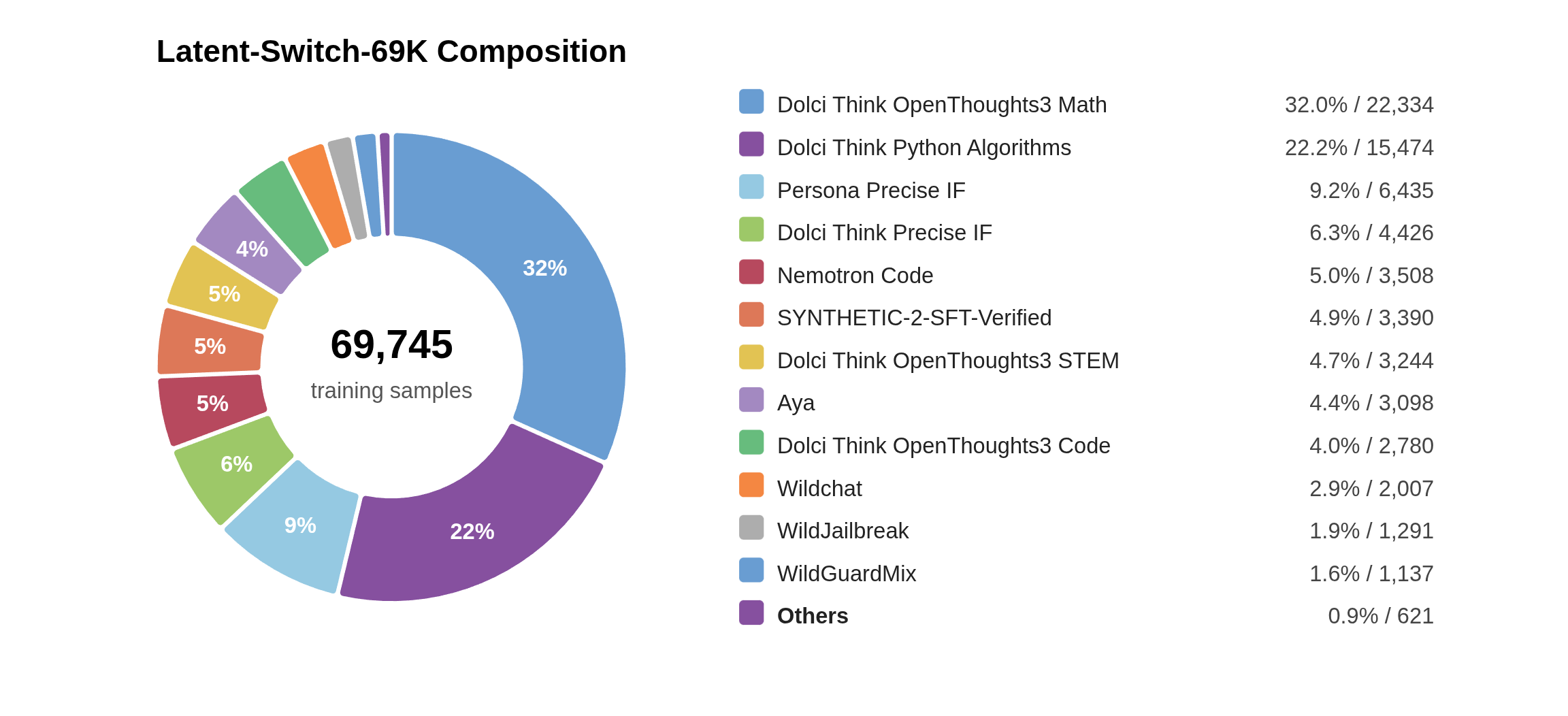
图43-2:最终训练集包含 69,745 条样本,来源中数学、代码和精确指令类数据占比较高。
从数据工程角度看,这里有三类统计必须同时保留。第一类是规模统计,说明训练集足够大,可以作为一个专门的 latent reasoning 监督语料,而不是少量 prompt 模板。第二类是难度统计,说明数据并非随机堆叠,而是服务于 curriculum 和 latent budget 的稳定性。第三类是领域统计,说明该数据集更适合训练和评估数学、代码、科学、复杂指令等推理任务,不应被误读为覆盖所有对话场景的通用 SFT 数据。
需要特别说明的是,本章对 Latent-Switch-69K、Dolci-Think-SFT-32B、Latent-Switch MindSpore 和 OpenAI-compatible API 的讨论,均用于说明推理轨迹数据工程方法。实际复用时,团队应分别核查原始数据集许可、模型服务条款、teacher 输出留存策略、隐私数据处理要求和机构内部审查流程;不应仅凭本章示例代码将第三方数据或 API 输出直接并入生产训练集。若业务数据包含用户输入、代码仓库、日志或内部文档,还应在 source trace 阶段记录脱敏、授权、访问时间和数据版本,以便后续审计。
Latent-Switch-69K 中保留有以下字段:dataset_name、source_dataset、record_id、difficulty、domain、source_cot_length、distilled_cot_length、compression_ratio、solution_intuition_length、n_latent_steps、assistant_cot、assistant_answer、mask_schema_version。这些字段看似偏工程,但它们决定了后续能否解释一次训练结果是来自更短 CoT、latent budget 调整,还是来自领域比例变化。
进一步看,Latent-Switch-69K 的字段可以分成四组。第一组是来源字段,用于说明样本从哪里来、原始问题属于哪个任务族、是否来自数学、代码、科学或通用指令数据。来源字段的作用不是装饰,它决定了后续配比、去重和责任追踪。比如当模型在代码任务上变强、但在开放问答上变啰嗦时,工程师需要回到来源字段检查是不是代码样本权重过高,或者 instruction-following 样本被压缩得过短。
第二组是推理内容字段,包括 source reasoning trace、solution intuition、assistant_cot 和 assistant_answer。source trace 是蒸馏前的参考,不一定进入最终 student sequence;solution intuition 是高层计划;assistant_cot 是压缩后的显式验证链;assistant_answer 是最终答案。四者之间需要保持可追溯关系。理想情况下,审计者可以从一条训练样本反查:原始长 CoT 中哪些信息被提炼成 intuition,哪些信息留在压缩 CoT 中,答案是否和原始问题的可验证目标一致。
第三组是长度与预算字段,包括 source CoT length、distilled CoT length、insight length、compression ratio 和 n_latent_steps。这些字段直接服务于成本控制和预算诊断。如果某个数据版本的平均压缩率突然下降到 0.3,表面上看 token 成本更低,但它可能意味着显式验证链被压得太短。如果 n_latent_steps 均值突然升高,模型训练时的有效序列长度和推理时的隐藏计算成本也会随之变化。没有这些长度字段,团队很难在“效率提升”和“监督损失”之间做定量判断。
第四组是监督字段,包括 prompt mask、latent internal mask、latent boundary mask、CoT mask、answer mask 和 teacher-KL mask。它们决定同一条 token 序列在训练时被怎样解释。普通数据集的 schema 往往只关心文本字段是否存在,Latent-Switch-69K 则必须把 mask 也视为数据资产。原因很简单:同一段文本如果 mask 不同,就对应不同训练任务。一个 latent placeholder 如果被 CE 拟合,就变成普通 token;如果被 mask 掉并替换为 recurrent latent state,它才是隐藏计算槽位。
43.3 蒸馏与记录形成:从 teacher trace 到压缩推理记录¶
Latent-Switch-69K 的构建起点是 Dolci-Think-SFT-32B 中采样得到的推理轨迹。原始轨迹可以理解为 source reasoning traces:它们包含问题、一个或多个 assistant 输出、可能的 ground truth 或可抽取答案,以及来源和元数据。构建过程并不是直接筛选短答案,而是先把长轨迹拆解为两个互补目标:高层问题求解意图和较短的显式验证链。
下面的教学化示例展示了最简单的 source trace 抽取方式:从 Hugging Face 读取 Dolci-Think-SFT-32B,使用固定随机种子打乱并选取一批记录,再把对话整理为后续蒸馏需要的最小字段。在 Latent-Switch MindSpore 的职责边界里,这一步和后续 teacher API 调用都属于上游数据准备;MindSpore 仓库接收的是已经带有 stage1.correct_insight、stage2.distilled_cot 和 stage2.answer 的蒸馏结果。
代码清单43-1给出了Python 实现片段。
from datasets import load_dataset
def first_message(messages, role):
return next(
(item["content"] for item in messages if item.get("role") == role),
"",
)
def last_message(messages, role):
return next(
(item["content"] for item in reversed(messages) if item.get("role") == role),
"",
)
dataset = load_dataset("allenai/Dolci-Think-SFT-32B", split="train")
sample_size = min(2000, len(dataset))
sampled = dataset.shuffle(seed=42).select(range(sample_size))
source_traces = []
for row in sampled:
messages = row.get("messages", [])
source_traces.append(
{
"record_id": row.get("id"),
"source_dataset": row.get("source", row.get("dataset", "unknown")),
"problem": first_message(messages, "user"),
"source_cot": last_message(messages, "assistant"),
}
)
代码清单43-1:Python 实现片段。
第一阶段是提取 solution intuition。数据构建提示要求 teacher 只抽取关键洞见,不要写成短 CoT,也不要直接给最终答案。这个字段应该描述“解决这道题的高层计划”,例如应该建立什么方程、应该枚举哪类状态、代码题应该使用什么数据结构、科学题应该抓住哪条因果关系。它的颗粒度介于标签和完整推导之间:比领域标签更具体,但比逐步推理更压缩。这样做的核心价值是把 Long-CoT 中可被内化的 planning signal 提取出来,为后续 latent budget 提供依据。
第二阶段是生成压缩显式 CoT。teacher 在原始问题和 solution intuition 的条件下继续解题,输出较短的推理过程和最终答案。由于 teacher 已经拿到高层计划,它不需要重新展开全部探索过程,也不需要重复原始轨迹中的无效分支。保留样本因此包含四个主要内容:problem、intuition、compressed CoT、final answer。与普通摘要不同,compressed CoT 的目标不是“把原文变短”,而是留下足够的可见验证路径,让模型在 latent reasoning 之后仍能用文本完成符号检查。
下面的最小实现使用 OpenAI-compatible API 串联两个阶段。第一阶段只要求返回 JSON 格式的 correct_insight;第二阶段以问题和该 intuition 为条件继续生成,并把 API 返回的隐藏 reasoning 内容记录为 distilled_cot,把可见内容记录为最终答案。密钥、API 地址和 teacher model 均从环境变量读取。
代码清单43-2给出了Python 实现片段。
import asyncio
import json
import os
from openai import AsyncOpenAI
client_kwargs = {"api_key": os.environ["OPENAI_API_KEY"]}
if os.getenv("OPENAI_BASE_URL"):
client_kwargs["base_url"] = os.environ["OPENAI_BASE_URL"]
client = AsyncOpenAI(**client_kwargs)
teacher_model = os.environ["TEACHER_MODEL"]
async def call_teacher(system_prompt, user_prompt):
response = await client.chat.completions.create(
model=teacher_model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
extra_body={"thinking": {"type": "enabled"}},
)
message = response.choices[0].message
reasoning = getattr(message, "reasoning_content", None)
content = message.content or ""
# Some compatible APIs place reasoning inside the visible content.
if not reasoning and "<think>" in content and "</think>" in content:
reasoning, content = content.split("<think>", 1)[1].split("</think>", 1)
return (reasoning or "").strip(), content.strip()
async def distill_one(problem, source_cot):
_, insight_json = await call_teacher(
"Return valid JSON with one field named correct_insight. "
"Give only the high-level solution plan, without the final answer "
"or a complete chain of thought.",
f"Problem:\n{problem}\n\nReference reasoning:\n{source_cot}",
)
intuition = json.loads(insight_json)["correct_insight"]
distilled_cot, answer = await call_teacher(
"Continue from the supplied solution intuition. Keep the reasoning "
"compact, verify the key steps, and give the final answer.",
f"Problem:\n{problem}\n\nSolution intuition:\n{intuition}",
)
return {
"problem": problem,
"solution_intuition": intuition,
"distilled_cot": distilled_cot,
"answer": answer,
}
record = asyncio.run(
distill_one(source_traces[0]["problem"], source_traces[0]["source_cot"])
)
代码清单43-2:Python 实现片段。
图43-3展示了相应的流程或结构。

图43-3:source trace 中的大量可见推理被拆成两类信号:solution intuition 用于估计 latent budget,压缩 CoT 用于显式验证和答案监督。
压缩率定义为:
最终语料的压缩率均值为 0.612,中位数为 0.569。这说明蒸馏后的可见 CoT 通常只保留原始推理长度的 57% 到 61% 左右。注意,这个数字不应被解释为“删除了四成推理信息”。更准确的理解是:一部分细节被压缩进 solution intuition 所代表的高层计划,并进一步映射到 latent placeholder 预算;另一部分必要推导仍保留在 <think> 中,用于显式验证和监督模型的可见推理风格。
图43-4展示了相应的流程或结构。

图43-4:本图展示了 source CoT length、distilled CoT length、insight length、ground truth length 和 compression ratio 的分布。
样本保留标准应围绕三个问题展开。第一,source trace 是否有足够可信的最终答案。如果原始答案无法抽取、明显和 ground truth 不一致,或 teacher 后续无法稳定复现答案,样本就不适合进入最终集。第二,solution intuition 是否只表达高层计划。如果 intuition 中直接泄露答案或写成完整 CoT,它就不再适合作为 latent budget 的代理。第三,compressed CoT 是否仍能连接问题和答案。如果压缩过度,显式推理会变成几个跳跃句,模型虽然能模仿答案,却学不到从隐式规划切换到显式验证的边界。
这套蒸馏过程给数据工程团队一个重要提示:推理数据压缩不能只看 token 数。更可靠的压缩必须同时检查 intent preservation、answer consistency 和 verification sufficiency。也就是说,压缩后的样本既要保留问题求解意图,又要保留足够的可见验证路径,还要在最终答案上保持一致。
把这个流程落到工程系统中,可以拆成六个可审计阶段。第一阶段是 source trace 抽取,把 Dolci-Think-SFT-32B 中的 prompt、assistant outputs、ground truth、dataset source 和 metadata 统一成内部记录。这个阶段最重要的是保留原始上下文,而不是过早改写。因为后续如果发现 teacher 输出异常,工程师需要回到 source trace 判断错误来自原始轨迹、提示模板,还是答案抽取。
第二阶段是 high-level intuition distillation。提示词明确要求 teacher 返回 JSON,并限制 correct_insight 只能描述粗粒度计划,不提供最终答案,不写成完整 CoT。这个约束很关键,因为 intuition 的角色不是训练模型“照着这段文字说”,而是估计应该给模型多少隐藏规划空间。若 intuition 已经包含详细推导,latent budget 就会从“压缩规划复杂度”变成“复制一段不可见 CoT 的长度”,这会削弱数据设计的清晰性。
第三阶段是 compact explicit CoT generation。teacher 在原问题和 intuition 的条件下生成较短推理链,这等于把 source trace 中可公开验证的部分重新整理出来。这里需要避免两个极端:一端是 CoT 仍然过长,几乎没有压缩;另一端是只剩结论,缺少验证。较好的样本通常会留下关键等式、关键分支、关键代码不变量或最终选择依据,而删除重复铺垫、自我怀疑和无效试探。
第四阶段是 answer validation。数学题可以检查抽取答案和 ground truth 是否一致,选择题可以检查选项格式,代码题可以尽量通过测试或静态规则检查,开放问答至少要做 teacher consistency 或抽样人工复核。Latent-switch 训练比普通摘要任务更依赖答案一致性,因为答案 token 是最终监督的核心位置,错误答案会和 latent 预算、显式 CoT 一起被模型学习。
第五阶段是 sequence rendering。系统把 problem、latent placeholder、compressed CoT 和 answer 渲染为 chat-style student sequence。这个阶段需要 tokenizer contract:<latent_think>、</latent_think>、<think>、</think> 必须被稳定识别,不能在不同 tokenizer 或不同 special-token 注册方式下被拆成不可预测片段。否则,span 检查和 mask 构造都会不可靠。
第六阶段是 mask materialization。数据加载器根据 token ids 重新定位边界,构造 labels、loss weights 和各种 mask。这个阶段不宜只依赖原始字符串中的字符偏移,因为 tokenizer 改变会让字符偏移失效。更稳妥的方式是基于 token id 中的 special token 位置构造 span,并在每条样本上校验边界出现次数、顺序、答案区间和 teacher-reference 区间是否有效。
43.4 Latent budget 与 student sequence:样本如何被渲染¶
Latent-Switch-69K 的关键字段之一是 n_latent_steps。它决定了 student sequence 中 <latent_think> 和 </latent_think> 之间放置多少个 latent placeholder。论文和代码中采用的基本启发式是:如果保留的 solution intuition 含有 \(L\) 个 token,则 latent budget 约为 \(L/2\),再受最大 latent 长度和 tokenizer 约束裁剪。最终数据中 latent steps 的均值为 41.49,中位数为 40.00。
这个预算规则有两个含义。第一,latent steps 不是随意加的 padding,而是与被压缩的高层推理内容相关。intuition 越长,说明这道题的高层规划可能越复杂,模型需要更多隐藏计算槽位。第二,latent steps 也不是越多越好。过长的 latent 区间会增加训练和推理成本,也可能让模型在隐藏状态中漂移。Latent-Switch-69K 的最终样本中,latent-step 分布集中在 40 步附近;MindSpore 数据管线则在 SFTBuildConfig 中用 latent_min、latent_max 和 256 步硬上限约束这一预算。
在 student sequence 中,一条样本可以抽象写成:
其中 \((l_1,\dots,l_m)\) 是 latent placeholder positions,\((t_1,\dots,t_n)\) 是蒸馏后的显式 CoT tokens,\((a_1,\dots,a_r)\) 是最终答案 tokens。代码实现中,latent placeholder 可以由重复的 latent_pad_token 填充;但训练时这些位置不会被当作普通语言目标。模型前向过程中,placeholder 的输入 embedding 会被 latent projector 产生的 recurrent latent states 替换。换言之,这些位置在序列里有 token 边界和长度,但语义上是隐藏计算槽位。
下面的示例对应 Latent-Switch MindSpore records.py 中 build_sft_record 的真实调用方式:上游蒸馏产物以 stage1 和 stage2 字段进入,SFTBuildConfig 控制压缩率过滤、latent budget、loss weight 和占位 token。tokens.py 中的 validate_tokenizer_contract 会先检查 <latent_think>、</latent_think>、<think>、</think>、<|im_start|>、<|im_end|> 和 <|endoftext|> 是否能被稳定编码。
代码清单43-3给出了 Python 实现片段。
import os
from transformers import AutoTokenizer
from latent_switch_mindspore.records import SFTBuildConfig, build_sft_record
from latent_switch_mindspore.tokens import validate_tokenizer_contract
tokenizer = AutoTokenizer.from_pretrained(os.environ["STUDENT_TOKENIZER"])
validate_tokenizer_contract(tokenizer)
distilled_row = {
"uid": record.get("record_id", "demo-row"),
"question": record["problem"],
"stage1": {"correct_insight": record["solution_intuition"]},
"stage2": {
"distilled_cot": record["distilled_cot"],
"answer": record["answer"],
"validation": {"is_correct": True},
},
"token_stats": {"compression_ratio_vs_primary_output": 0.612},
}
config = SFTBuildConfig(
latent_min=1,
latent_max=128,
latent_pad_token="<|endoftext|>",
cot_loss_weight=0.0,
answer_loss_weight=1.0,
)
sft_record, reason = build_sft_record(distilled_row, tokenizer, config)
if reason != "ok":
raise ValueError(f"sample filtered during SFT build: {reason}")
代码清单43-3:Python 实现片段。
生产预处理还会依据压缩率和字段完整性过滤样本,并记录 CoT、answer 的 loss weight。更重要的是,渲染后的记录仍需交给 dataset.py 中的 materialize_sample 或 LatentSwitchSFTSource 重新定位 special-token spans 和构造 supervision masks;仅仅拼出这段字符串,并不意味着样本已经可以安全训练。
如果运行环境已安装 MindSpore,最终可以把构造好的 JSONL 直接包装为 mindspore.dataset.GeneratorDataset。下面的示例展示了最小加载方式,batch 中会包含 input_ids、labels、teacher_kl_mask、latent_positions 等训练侧需要的列。
代码清单43-4给出了Python 实现片段。
import os
from transformers import AutoTokenizer
from latent_switch_mindspore import create_mindspore_dataset
tokenizer = AutoTokenizer.from_pretrained(os.environ["STUDENT_TOKENIZER"], use_fast=True)
dataset = create_mindspore_dataset(
"data/sft_train.jsonl",
tokenizer=tokenizer,
batch_size=2,
max_length=4096,
shuffle=False,
)
for batch in dataset.create_dict_iterator(output_numpy=True, num_epochs=1):
print(batch["input_ids"].shape)
print(batch["teacher_kl_mask"].shape)
break
代码清单43-4:Python 实现片段。
下面是一个教学化的简化样本序列示例。它只用于说明 schema 和 mask 关系,不是数据集中某条真实训练样本。
代码清单43-5给出了隐式推理轨迹样本。
<|im_start|>user
Target Question:
某数列满足 a_1 = 2, a_{n+1} = 3a_n + 1。求 a_4。
<|im_end|>
<|im_start|>assistant
<latent_think>
<|endoftext|><|endoftext|><|endoftext|><|endoftext|>
</latent_think>
<think>
用递推式逐步计算即可。先由 a_1 得到 a_2,再得到 a_3 和 a_4。
a_2 = 3 * 2 + 1 = 7;
a_3 = 3 * 7 + 1 = 22;
a_4 = 3 * 22 + 1 = 67。
</think>
最终答案是 67。
<|im_end|>
代码清单43-5:隐式推理轨迹样本。
这条示例里,<latent_think> 和 </latent_think> 是结构边界;中间四个 <|endoftext|> 只是占位符,真实样本中的数量由 n_latent_steps 决定;<think> 到 </think> 之间是可见压缩 CoT;之后是答案。对于训练来说,最重要的不是这段文本看起来像不像自然对话,而是每个 token 区间是否能被稳定定位。Latent-Switch MindSpore 中的 build_spans 会检查一条样本中恰好包含一个 <latent_think>、一个 </latent_think>、一个 <think> 和一个 </think>,并保证它们满足:
代码清单43-6给出了隐式边界顺序约束示例。
代码清单43-6:隐式边界顺序约束示例。
这个顺序约束关键。如果边界 token 缺失、重复或顺序错乱,mask 就会错位,latent placeholder 可能被误当作普通答案 token,或者 answer 区间被截断。对于普通 SFT 数据,边界错一处也许只是格式问题;对于 latent-switch 数据,边界错位会直接改变训练目标。
在实际数据仓库中,student sequence 不应只作为一个长字符串保存。更稳妥的做法是同时保存结构化字段和渲染后文本。结构化字段包括 messages、assistant_cot、assistant_answer、n_latent_steps、latent_pad_token、state_align_reference_messages 等;渲染后文本则用于快速查看和兼容普通训练框架。LatentSwitchSFTSource 会优先使用结构化字段构造 token ids,materialize_sample 再生成 labels、loss weights 和各类 mask。这个设计反映了一个经验:latent-special-token 边界太重要,不应完全依赖已经拼好的文本。
latent_pad_token 也值得单独说明。它在序列中承担的是“占位”而非语义内容。若 tokenizer 已经注册该 token,加载器可以直接重复其 id;若没有注册,就只能把字符串重复后再编码,这会带来长度不确定性。对于一个普通 padding token,这种差异也许还能接受;对于 latent budget,它会改变 \(m\) 的实际 token 数,进而改变 hidden rollout 的步数。因此,发布数据集时应明确 tokenizer 版本、special token 注册方式和 latent pad token 的语义。
teacher-reference conversation 是另一条容易被忽视的序列。它不是 student sequence 的副本,而是省略 latent placeholder 后的参考对话。teacher 输入中包含原始问题和 solution intuition,assistant continuation 则是压缩 CoT 和答案。这个设计让 teacher KL 聚焦在可见推理质量和答案分布上,而不是要求 teacher 理解 student 的 latent 内部槽位。也就是说,student sequence 负责训练 latent-then-explicit 格式,teacher reference 负责提供显式验证部分的分布参考,两者服务于不同监督目标。
43.5 Supervision masks:哪些 token 参与 loss¶
Latent-Switch-69K 的监督设计可以概括为一句话:prompt tokens 和 latent interior placeholders 不参与普通 token-level CE,结构边界、显式 CoT、答案和结束 token 参与有针对性的监督,teacher KL 只对选定的显式 CoT 与答案位置生效。
在代码实现中,一条样本会构造多个 mask:prompt_mask、latent_internal_mask、latent_boundary_mask、cot_mask、answer_mask、teacher_kl_mask。这些 mask 不是为了可视化方便,而是直接决定不同 objective 的作用位置。普通 labels 初始化为 student token ids,然后对 prompt 区间和 latent interior 区间置为 -100,表示这些位置被 cross-entropy 忽略。
可以用下面的简化规则表示 CE label:
其中 \(\mathcal{S}_{prompt}\) 表示用户 prompt 与 assistant prefix 之前的上下文位置,\(\mathcal{S}_{lat}^{int}\) 表示 <latent_think> 和 </latent_think> 之间的内部 placeholder 位置。被置为 -100 的 token 不被普通 CE 直接拟合。这样做避免了一个错误目标:要求模型在 latent 内部位置预测某个固定文本 token。对 latent-switch 数据来说,latent 内部位置的价值不是输出 <|endoftext|>,而是为模型执行若干步隐藏状态更新预留槽位;MindSpore 数据管线会把这些位置显式写入 latent_internal_mask、latent_positions 和 latent_slot_mask。
图43-5展示了相应的流程或结构。

图43-5:prompt 与 latent interior 被普通 CE mask 掉;latent 边界、显式 CoT、答案和结束 token 由不同权重和 mask 控制。
latent_boundary_mask 标出 <latent_think> 和 </latent_think> 两个边界位置。边界 token 本身仍然需要监督,因为模型必须学会什么时候进入 latent 区间,什么时候从 latent 区间退出。如果不监督边界,模型可能无法稳定切换到 <think>,或者在推理时生成不完整的结构。
cot_mask 覆盖 <think> 到 answer_start 之前的区间。论文训练目标中,内部显式 CoT tokens 可以使用不同权重,例如用 \(\lambda_{CoT}\) 降低显式 reasoning 对总 CE 的支配程度。这样做符合数据集目标:显式 CoT 仍然重要,因为它承担验证和可解释输出;但训练不应退化为“越像长 CoT 越好”。模型还需要优先学会结构边界和最终答案行为。
answer_mask 覆盖 </think> 之后、<|im_end|> 之前的答案区间。答案 token 通常应保持较强监督,因为最终答案是任务正确性的主要承载位置。对于数学题,它可能是一个 boxed answer;对于选择题,它可能是 A、B、C、D;对于代码题,它可能是一段函数实现。无论 latent 区间如何设计,答案一致性都必须被严格维护。
teacher_kl_mask 则用于 teacher-distribution supervision。每条样本还会构造一个 teacher-reference conversation:它不包含 student 的 latent placeholder,而是把原始问题和 distilled solution intuition 合并为 teacher 输入,让 teacher 在缩短后的 <think> ... </think> 与答案位置提供分布参考。这样做的好处是,teacher 不需要模拟 continuous latent placeholders;它只监督显式推理和答案的 token 分布质量。
表43-2列出了主要 token 区间、对应 mask 以及训练含义。
表43-2:Supervision masks 与训练目标对应关系。
| 区间 | 示例 token | 普通 CE label | 主要 mask | 工程含义 |
|---|---|---|---|---|
| Prompt 与 assistant prefix | user question <\|im_start\|>assistant |
-100 |
prompt_mask |
作为条件,不作为输出目标 |
| Latent 起始边界 | <latent_think> |
supervised | latent_boundary_mask |
学会进入 latent reasoning |
| Latent 内部槽位 | l_1 ... l_m |
-100 |
latent_internal_mask |
隐藏计算槽位,不拟合占位文本 |
| Latent 结束边界 | </latent_think> |
supervised | latent_boundary_mask |
学会停止 latent reasoning |
| 显式 reasoning | <think> ... </think> |
weighted supervised | cot_mask、teacher_kl_mask |
可见验证链,可降低权重 |
| 最终答案 | answer tokens | supervised | answer_mask、teacher_kl_mask |
任务正确性核心监督 |
结束 token <\|im_end\|> |
supervised | end-token weight | answer_mask |
保证聊天格式闭合 |
这套 mask 设计解释了为什么 Latent-Switch-69K 不能被普通数据加载器随意重编码。普通聊天数据加载器通常只关心 prompt 和 response 的分界,而 latent-switch 数据加载器必须知道 latent_start、latent_end、think_start、think_end、answer_start 和 im_end 的精确位置。只要 tokenizer 特殊 token 注册不一致,或者 string re-encoding 改变了边界 token 的位置,mask 就会失真。
更细地说,mask 还承担了训练目标之间的解耦。CE 目标负责让模型学会输出结构边界、显式推理和答案;latent internal mask 保护隐藏计算槽位,避免模型把它们当成普通文本学习;teacher KL 目标让显式 CoT 和答案更接近 teacher 的分布;halt 或 boundary 相关监督则帮助模型在合适位置结束 latent reasoning。
对于数据工程师来说,最实用的检查不是重新推导损失函数,而是确认每条样本的 mask 是否满足几条不变量。第一,prompt 区间所有 labels 都应为 -100。第二,latent interior 区间所有 labels 都应为 -100,但 latent boundary token 不应被当作普通 prompt mask。第三,cot_mask 应覆盖 <think> 到 </think> 相关位置,且 answer_start 必须在 think_end 之后。第四,answer_mask 不应包含 <|im_end|>,因为结束 token 可以单独监督。第五,teacher KL mask 不应覆盖 latent interior,因为 teacher reference 本身不含这些 placeholder。
这些不变量应在数据构造和训练加载两个阶段都检查一次。构造阶段检查可以阻止坏样本入库;训练加载阶段检查可以发现 tokenizer、max_length、截断策略或配置变更带来的新问题。尤其是 max_length 截断,一旦截掉 answer 区间,样本就会只剩结构和推理,没有最终答案监督。代码中因此会在截断后重新构造 spans,并检查 answer_start 是否仍小于 im_end。
还有一个细节是显式 CoT 的权重。Latent-Switch-69K 不是要删除显式推理,而是要降低对完整长 CoT 的依赖。若 CoT 权重过高,模型会更倾向于把能力用在复现可见推理文字上;若 CoT 权重过低,模型可能只学会结构和答案,显式验证链变弱。数据侧至少要保留可配置的 cot_loss_weight 或等价字段,使训练者能够在不同任务上调整“可见验证”与“最终答案”的平衡。
43.6 质量控制:压缩、边界与偏置的五类风险¶
Latent-Switch-69K 的质量控制不只是过滤脏文本。由于它同时包含压缩推理、latent 预算和多种 mask,风险也分成多层。
表43-3给出了推理轨迹压缩、边界对齐和领域偏置等常见风险的检查口径。
表43-3:压缩、边界与偏置的五类质量风险及修复动作。
| 风险类型 | 典型症状 | 影响 | 修复动作 |
|---|---|---|---|
| 压缩过度 | compressed CoT 只有结论,没有可见验证链 | 模型学不到从 latent 规划切换到显式验证的过程 | 增加 verification sufficiency 检查;拒绝跳步样本 |
| 推理断裂 | solution intuition 与 compressed CoT 使用不同解题路线 | latent budget 对应的高层计划无法支撑后续 CoT | 检查 intuition-CoT entailment;要求 teacher 重新生成 |
| 答案不一致 | source、teacher continuation、final answer 不一致 | 训练目标在答案位置冲突 | 用 ground truth、verifier 或答案抽取规则复核 |
| 边界错位 | <latent_think>、<think> 缺失、重复或顺序错误 |
mask 错位,latent placeholder 被错误监督 | 在数据加载前做 span validation;错误样本隔离 |
| 领域偏置 | 数学和代码占比过高,通用指令覆盖不足 | 模型迁移到非推理任务时风格偏窄 | 记录 domain mix;按训练目标调整采样权重 |
| latent budget 异常 | n_latent_steps 为 0、过大或与 intuition 长度不匹配 |
隐式规划预算失真,推理成本不可控 | 对预算设上下限;监控均值、中位数和长尾 |
| teacher KL 错位 | KL mask 与 teacher reference token 不对齐 | teacher 分布监督作用到错误位置 | 保留 teacher span 校验;记录 top-k 分布版本 |
第一类风险是压缩过度。压缩率均值 0.612 和中位数 0.569 表明语料确实显著缩短了可见 CoT,但工程上不能把压缩率越低越好作为目标。如果一个样本从 1,000 个推理 token 压缩到 50 个 token,却失去关键等式、状态转移或代码不变量,那么它虽然节省 token,却破坏了监督质量。更稳妥的指标是组合式的:压缩后长度下降、答案仍一致、可见推理仍能解释最终答案。
第二类风险是推理断裂。solution intuition 是 latent budget 的来源,如果 intuition 描述的是一种路线,而 compressed CoT 实际使用另一种路线,模型就会收到不一致信号。比如 intuition 说“用动态规划”,compressed CoT 却写成贪心证明;或 intuition 说“先建立方程”,后文却直接枚举。此时 latent placeholder 的数量仍然可能合理,但它对应的高层计划已经失配。数据管线需要检查 intuition 与 CoT 的语义一致性。
第三类风险是答案不一致。推理数据中最常见的问题之一是中间链路看起来合理,但最终答案和 ground truth 不同。对 Latent-Switch-69K 来说,答案不一致更严重,因为 teacher-reference、student sequence 和 answer_mask 都会围绕最终答案构建。如果错误答案进入训练,模型不仅会学到错误结论,还可能学到错误的 latent-to-explicit 切换模式。数学和选择题可用规则验证器或答案抽取器,代码题可用单元测试,开放问答则至少需要 teacher check 或人工抽检。
第四类风险是边界与 mask 错位。<latent_think>、</latent_think>、<think>、</think> 都是结构 token,而不是普通文本装饰。数据加载器会检查它们出现次数和顺序,并据此计算 span。如果一条样本多了一个 </think>,普通渲染可能仍然能显示,但训练 mask 会发生错位。质量控制应把 span validation 放在数据入库前,而不是等训练报错。
第五类风险是领域偏置。Latent-Switch-69K 的 math 约 37%、code 约 34%、science 约 5%,这使它适合 reasoning-heavy 训练,但也意味着它不是通用助手语料的完整替代品。如果把它和普通 SFT 数据混合,应明确训练目的:是强化数学代码推理、压缩可见 CoT,还是改善所有用户问题的回答效率。不同目标对应不同采样权重和评估集。
质量控制还需要保留审计信息。建议每个数据版本至少输出四份报告:长度与压缩率报告、difficulty/domain 分布报告、span 与 mask 校验报告、答案一致性与失败样本报告。对于 latent reasoning 数据,光有最终 parquet 或 jsonl 不够;没有这些报告,训练后很难判断模型变化来自数据质量提升,还是来自无意的分布漂移。
为了让这些报告真正可用,可以为 Latent-Switch-69K 建立一套发布前验收清单。长度层面,检查 source CoT、distilled CoT、intuition、answer 和 total sequence 的分布,重点关注过短和过长样本。过短样本可能没有足够监督,过长样本可能在训练时频繁截断。压缩层面,检查压缩率的均值、中位数、分位数和极端值,确认不是某个来源数据集导致异常。
结构层面,逐条检查四个边界 token 的出现次数和顺序。任何缺失、重复、嵌套或顺序错误都应直接隔离。mask 层面,抽样渲染 token 区间,把 prompt、latent internal、latent boundary、CoT、answer 和 im_end 用不同颜色展示,确认人工理解与程序 mask 一致。对于一类新数据源,建议至少人工查看几十条样本,尤其是长数学证明、代码函数、选择题和开放问答。
语义层面,检查 intuition 是否含有最终答案,compressed CoT 是否能支持答案,answer 是否与 ground truth 或 verifier 一致。对于代码任务,应尽量区分“解释中的思路正确”和“最终代码可运行”两个层面;对于数学任务,应区分“最终数值正确”和“推导链可验证”两个层面。latent-switch 数据的目标是高层规划加显式验证,因此这两个层面都不能完全放弃。
分布层面,检查 difficulty、domain、source dataset、语言、答案格式和 token 长度的联合分布。单独看每个字段可能都正常,但组合后可能出现偏置。例如 hard 样本几乎都来自数学,code 样本几乎都使用某一种 Python 模板,instruction 样本压缩率明显低于数学样本。这些偏置不一定都要消除,但必须记录,因为后续训练和评估会受到它们影响。
版本层面,每次发布都应给出数据版本号、构建脚本版本、teacher 模型版本、tokenizer 版本、special-token contract、过滤规则和统计报告。Latent-Switch-69K 这种数据集的可复查性来自“文本加结构加配置”的组合。如果只保存最终文本,几年后很难解释为什么某个样本有 38 个 latent steps,为什么某个 CoT 被降权,为什么某些 teacher KL 位置被跳过。
43.7 与前后章节的回链:从推理数据到推理飞轮¶
把 Latent-Switch-69K 放回全书结构中,它的价值不在于介绍一个孤立数据集,而在于展示一种新的推理数据接口。
对第五篇来说,它延续了合成数据和蒸馏数据的核心思想。第15章强调从数据合成任务定义出发设计样本,第16章讨论蒸馏如何把强模型行为迁移到训练语料,第17章讨论质量评估和过滤。Latent-Switch-69K 把这些原则具体化为:从 teacher trace 中提取高层 solution intuition,用压缩 CoT 保留显式验证,用 mask 把不同监督目标分配到不同 token 区间。
对第六篇来说,它提供了 CoT 数据工程的下一步。第18章中的 CoT 样本通常把推理过程直接作为文本监督;第19章的工具数据强调动作、观察和结果;第20章的 Agent 数据强调状态和轨迹。Latent-Switch-69K 则说明,推理状态也可以部分存放在不可见的 latent slots 中。它不是放弃可解释性,而是把可见解释压缩到必要验证链,把探索性规划迁移到隐藏计算区间。
对第十三篇来说,它是后训练和 RL 推理数据配方的前置样板。第45章会讨论 SFT、偏好对齐和在线持续优化的数据层级;第46章会讨论 RL reasoning、verifier、候选组和奖励信号。Latent-Switch-69K 在 SFT 阶段就提前引入了结构化推理预算和 mask schema,使后续 RL 阶段可以围绕“latent budget 是否合适”“显式验证是否充分”“答案是否可验证”继续优化。
对第十四篇项目来说,它可以和 P06、P10、P12 分别形成接口。P06 的 PRM 数据关注过程步骤的评分,Latent-Switch-69K 提供了压缩显式 reasoning 和 answer 区间,适合进一步抽取可评分的 verification steps。P10 的 LLM 数据飞轮关注线上反馈和持续迭代,latent-switch 数据可以作为一种降低推理 token 成本的候选数据资产。P12 的 R1 reasoning flywheel 关注多路采样、verifier 和拒绝采样,Latent-Switch-69K 则提供了一个冷启动思路:先用蒸馏数据教模型如何在 latent planning 和 explicit verification 之间切换,再用验证器和 RL 数据进一步调整预算和答案正确性。
最后,本章的工程结论可以压缩为四点。
- Latent reasoning 数据不是普通 CoT 数据的短版本。它必须记录隐藏规划预算、显式验证链和最终答案之间的关系。
<latent_think>与<think>是两类不同语义的结构区间。前者提供隐式计算槽位,后者提供可见推理监督。- Mask 是数据 schema 的一部分,不是训练代码的附属细节。prompt、latent interior、boundary、CoT、answer 和 teacher-KL 位置必须在数据构造时就能被稳定还原。
- 数据压缩的目标不是删掉推理,而是把高层意图、隐藏计算和显式验证重新分配到更合适的通道中。
如果一个团队只复用 Latent-Switch-69K 的文本输出,而忽略 n_latent_steps、latent boundary 和 supervision masks,它得到的只是一个较短的 CoT SFT 数据集。只有把压缩率、latent placeholder、student sequence 和 mask 作为同一个数据工程对象管理,这个数据集才真正体现出 latent-then-explicit reasoning 的设计思想。
43.8 复用建议:把 Latent-Switch 思路迁移到自有数据¶
如果团队希望在自己的数学、代码或业务推理数据上复用 Latent-Switch-69K 的思路,不建议第一步就改模型结构。更稳妥的路线是先把数据 schema 做出来。团队可以从现有 Long-CoT 样本中抽取一小批高质量问题,人工或用 teacher 模型生成 solution intuition,再生成压缩 CoT 和最终答案。随后,按 intuition 长度分配一个保守的 latent budget,例如从 \(L/3\)、\(L/2\) 和固定 32 steps 三种方案中选择一到两个版本做对照。这样做的价值在于,团队可以先观察数据是否能被稳定渲染、mask 是否正确、答案是否一致,而不必马上进入昂贵训练。
第二步是建立小规模验收集。这个验收集不需要很大,但要覆盖短题、长题、数学、代码、选择题、开放问答和格式约束题。每个样本都应该能回答三个问题:高层 intuition 是否足够表达解题计划,压缩 CoT 是否足够支撑答案,latent steps 是否与题目复杂度大致匹配。若这三点在人工抽检中经常失败,说明问题不在训练算法,而在数据构造规则还没有稳定。
第三步是把 latent-switch 数据和普通 SFT 数据分开管理。普通 SFT 数据可以只记录 prompt 和 response,latent-switch 数据则必须记录结构化字段、特殊 token contract、mask schema 和构建版本。混合训练时,也应在 manifest 中写清楚每类数据的采样权重和用途。否则,当模型出现回答变短、推理解释变弱或格式边界不稳定时,团队很难定位是 Latent-Switch 数据本身的问题,还是混合比例、tokenizer 或训练配置的问题。
第四步是谨慎解释效果。若模型使用更少 visible tokens 得到相近答案,不一定说明 latent reasoning 已经学好;它也可能只是学会直接回答。真正的验收应同时查看答案正确率、显式验证链质量、格式闭合率、latent 边界稳定性和不同预算下的 token 成本。只有这些指标一起改善,才能说明数据集确实在支持“隐式规划加显式验证”的目标。
这也是本章反复强调 schema、mask 和质量报告的原因:latent reasoning 能否落地,首先取决于数据是否把隐藏规划的接口定义清楚,并在数据构造、训练加载和评估复盘三个阶段保持同一套可检查口径。
43.9 小结¶
Latent-Switch-69K 展示了推理数据工程的一种重要转向:从“收集更长、更详细的 CoT”转向“设计更有效的推理监督结构”。它从 Dolci-Think-SFT-32B 的推理轨迹出发,通过 teacher distillation 提取 solution intuition 和 compressed CoT,把 intuition 长度映射为 latent budget,再渲染为 <latent_think>、placeholder、<think>、answer tokens 组成的 student sequence。最终,prompt 与 latent interior 被普通 CE mask 掉,边界、显式推理、答案和结束 token 获得各自的监督,teacher KL 只对选定可见位置生效。
这种设计让数据集不再只是文本集合,而是包含结构、预算、mask 和质量报告的训练接口。对后续推理模型和 RL 数据工程而言,Latent-Switch-69K 的价值正是在这里:它把“少写一些推理”变成了一个可训练、可检查、可迭代的数据工程问题。
本章小结¶
Latent-Switch-69K 展示了推理轨迹数据工程的核心问题:如何在保留可学习推理信号的同时压缩显式链路,并通过监督 mask、latent budget 和质量门禁控制训练目标。它为后续推理模型、强化学习和项目级推理飞轮提供了从样本格式到评测复盘的连接点。
参考文献¶
Wei J, Wang X, Schuurmans D, Bosma M, Xia F, Chi E, Le Q V, Zhou D (2022) Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. arXiv:2201.11903.
Lightman H, Kosaraju V, Burda Y, Edwards H, Baker B, Lee T, Leike J, Schulman J, Sutskever I, Cobbe K (2023) Let's Verify Step by Step. arXiv:2305.20050.
Yao S, Zhao J, Yu D, Du N, Shafran I, Narasimhan K, Cao Y (2023) ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629.
DeepSeek-AI (2025) DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948.
Hendrycks D, Burns C, Kadavath S, Arora A, Basart S, Tang E, Song D, Steinhardt J (2021) Measuring Mathematical Problem Solving With the MATH Dataset. NeurIPS 2021. arXiv:2103.03874.