第41章:视觉推理数据工程:图表证据、医学图像与工具调用轨迹¶
摘要¶
本章讨论视觉数据如何从对象识别走向证据组织和可执行推理,有多图表信息图推理与医学图像工具调用两个专项案例。多图表信息图强调跨子图表证据聚合、数值关系和多步推理链路,MedImage-ToolVQA 强调 ROI、mask、bbox 与工具调用轨迹。两类任务都要求数据集同时记录视觉证据、问题结构、推理过程和人工复核边界。
关键词¶
视觉推理;图表问答;医学图像;工具调用;ROI;多模态评测
案例A:多图表信息图:跨图表证据聚合与多步推理¶
案例A:学习目标¶
通过本章学习,读者应能够:
- 区分传统单图表 VQA 的一图一问闭环范式与真实复合信息图推理在数据设计上的本质差异。
- 解释复合信息图为何天然要求跨图表数据聚合、多步骤串行运算与视觉上下文联合推理三类核心任务。
- 掌握以 354 份原生信息图、1917 条链式子问题为基础的样本组织方式,理解整图单文件、保留原生多子图布局的标注取舍。
- 识别 23 种子图表类型与 13 类设问题型随机组合所带来的跨格式数据读取与多步推理难度。
- 分析图例误读、跨图表数据混淆与前置计算错误逐级传导等典型模型失效模式及其在评测协议中的体现。
案例A.1:问题场景:单图表 VQA 的局限性与复合信息图推理的现实需求¶
案例A.1.1 传统单图表视觉问答任务边界约束¶
现有主流图表视觉问答数据集,如 ChartQA (Masry et al. 2022)、FigureQA (Kahou et al. 2017)、PlotQA (Methani et al. 2020) 等,在数据设计层面普遍遵循一图一问、单图闭环范式:单张样本图像只包含独立单一图表(单柱状图、单折线图、单饼图等),全部作答所需数据、图例、统计数值均被收拢在同一张图表内,模型仅需要通过定位图表坐标,读取标注数字,而后完成加减运算或分类判断即可 (Kafle et al. 2018; Zhu et al. 2025)。
从任务难度分层来看,单图表 VQA 任务基本止步于单步信息抽取,任务需求集中在极值查找、单类求和、单一占比计算,不存在跨视图数据联动需求 (Masry et al. 2025; Xie et al. 2026)。在实验室标准化数据集环境下,图表样式经过人工规整优化:图例排版规整、坐标轴标注无歧义、数据分区边界清晰、无附加备注文本与补充说明,数据环境经过降噪处理,和互联网、商业出版物原生信息图的制作规范存在本质区别。
从模型落地短板来看,基于单图表数据集训练的 VQA 模型形成能力偏科:模型擅长局部像素级数值识别,但缺失跨区域信息关联能力。现实世界中,企业年报信息图、民生统计科普图、行业市场调研报告、医疗卫生数据看板极少采用单一图表排版,创作者习惯于通过多子图分区排布实现 “分模块拆解指标、全视图汇总结论” 的可视化表达,不同子图分别承载分类统计、时序变化、地域分布、风险对比等差异化信息,最终结论必须整合多张子图数据才能得出,单图表训练范式无法匹配该类落地场景。
案例A.1.2 真实复合信息图的推理特征定义¶
复合信息图是多子图嵌套式可视化载体,整图为统一图片文件,内部切割为多个物理分区,每个分区承载独立类型子图表,辅以全局图例、分区注释、侧边文字说明、补充警示标注,也是多图表信息图推理数据集的样本底层形态 (Mathew et al. 2021)。对比单图表,真实复合信息图推理天然附带三类核心刚需,也是本数据集锚定的三大核心任务,本小节先从落地场景解释任务由来,第二章做标准化定义:
- 跨图表数据聚合需求。信息图创作者会拆分统计维度:例如鲨鱼袭击统计案例中,一张子图标注全美各县历史累计鲨鱼袭击总数、两张子图统计近十年各州袭击总量、一张子图罗列意外致死诱因对比数据,不同数据分散在多个独立子视图,想要完成复杂推理的问题,必须聚合多张图表数据,无法依托单张子图完成。
- 多步骤串行数值计算需求。现实问答往往是链式推导:先通过第一个问题锁定目标地域(佛罗里达州沃卢西亚县),再依托该地域所属州调取第二个子图全州统计数据,继而依托多州数据做差值运算,计算步骤具备先后依赖关系,前序答案是后序计算的输入参数,对应多步计算任务属性。
- 视觉 + 上下文联合推理需求。信息图存在大量非数值类标注:物种备注、年份标注、图例符号(高风险袭击 / 非高风险袭击图标区分)、地域简写符号,部分关键信息不体现在坐标轴数字中,藏于图例、脚注、侧边说明文字内,需要模型结合视觉符号与自然语言上下文综合推理,即视觉与上下文推理任务。
案例A.1.3 现有基准数据集缺口与本数据集研发意义¶
当前全球公开的多模态图表推理基准数据集存在明显供给缺口:人工合成仿真图表数据集较多,基于网页、报刊、科普出版物抓取的原生真实复合信息图样本稀缺,多数数据集为了降低标注难度,人为拆分多子图信息图为多张独立图片,破坏原图的空间关联与上下文逻辑 (Foroutan et al. 2025)。在此背景下,多图表信息图推理数据集立足原生真实信息图抓取,保留原图多子图同屏布局、图例全局共用、分区备注穿插的原生结构,与上述依赖网页抓取的构建方式不同,我们利用多模态大模型进行自动化地合成图表以及问答对,填补真实场景跨图表推理评测基准空白。
从算法研发视角,该数据集的落地可以倒逼 VQA 模型跳出 “单图读取” 固有架构,推动多模态模型新增子图区域分割、跨视图信息记忆存储、多轮计算链路推理三项能力,贴合金融数据分析、市场资讯解读、公共卫生数据研判等产业落地场景。
自建数据集采用 huggingface 链接:https://huggingface.co/datasets/xychen-zh/multi-chart-infographic-reasoning ,以及相似数据集https://huggingface.co/datasets/ustc-lab/ChartQwen。 推荐使用 MindSpore 体系,github 链接:https://github.com/xychen-zh/multi-chart-infographic-reasoning-mindspore。
案例A.2:数据集概览:样本规模、领域覆盖与图表类型体系¶
本章基于原始数据集文档,对数据集进行了系统分析,从样本规模、领域覆盖范围、子图表类型分布以及问答体系结构四个维度展开全面梳理,准确呈现了包含 354 张原始图表和 1917 个子问题的数据集整体特征与基础统计信息。
案例A.2.1 数据集基础量化指标¶
-
图像样本总量:数据集收录 354 份经过筛选的真实世界复合信息图。受限于互联网高质量原生多子图信息图资源稀缺的客观现状,文档明确标注当前样本体量偏小,项目团队预留后续迭代扩容规划,未来将持续扩充原图样本池。所有图像均为完整一体化信息图,整图单文件存储,内部内嵌多个独立子图,不做人工切分拆图处理,完整保留原图排版布局、图例共享规则、文本注释位置,最大限度还原人类阅读信息图时的视觉浏览逻辑。
-
问答样本总量:全数据集配套 1917 条具备逻辑关联性的多阶子问题,单张复合信息图配套多条前后依赖的链式子问题,问题和答案(大模型辅助生成后人工标注核验);额外针对每张信息图追加 1 道无法依托图内现有信息作答的无效问题,用于测试模型拒答能力与鲁棒性,规避模型强行编造数据作答的过拟合缺陷。 从单图平均配比测算:单张信息图平均配套 5.41 条有效推理子问题 + 1 道不可作答测试题,问答密度贴合真实场景人类分步提问习惯。
案例A.2.2 全维度领域覆盖分布(28 大细分领域)¶
为保障数据集评测结果具备算法通用化验证能力,样本素材跨行业抓取,一共覆盖 28 个细分垂直领域,全面覆盖民生、产业、科研、文娱、经济四大板块,细分领域清单如下:动物,商业,职业与就业,家居与园艺,计算机与互联网,工业,法律法务,生活方式,教育,能源,娱乐,环境,金融理财,饮食,健康美妆,孕产与育儿,市场营销,政治与历史,人文社会,房地产,购物,科学,社交媒体,体育,科技,交通以及旅行。
多领域的设计,可以规避数据集领域单一带来的模型过拟合问题,防止模型仅在单一主题样本上拟合最优,在陌生行业信息图上推理失效;多样化领域下图表表达习惯、图例规范、专业缩写各不相同,进一步拔高视觉上下文推理任务难度,贴近落地场景多变性。
图41-1展示了相应的流程或结构。
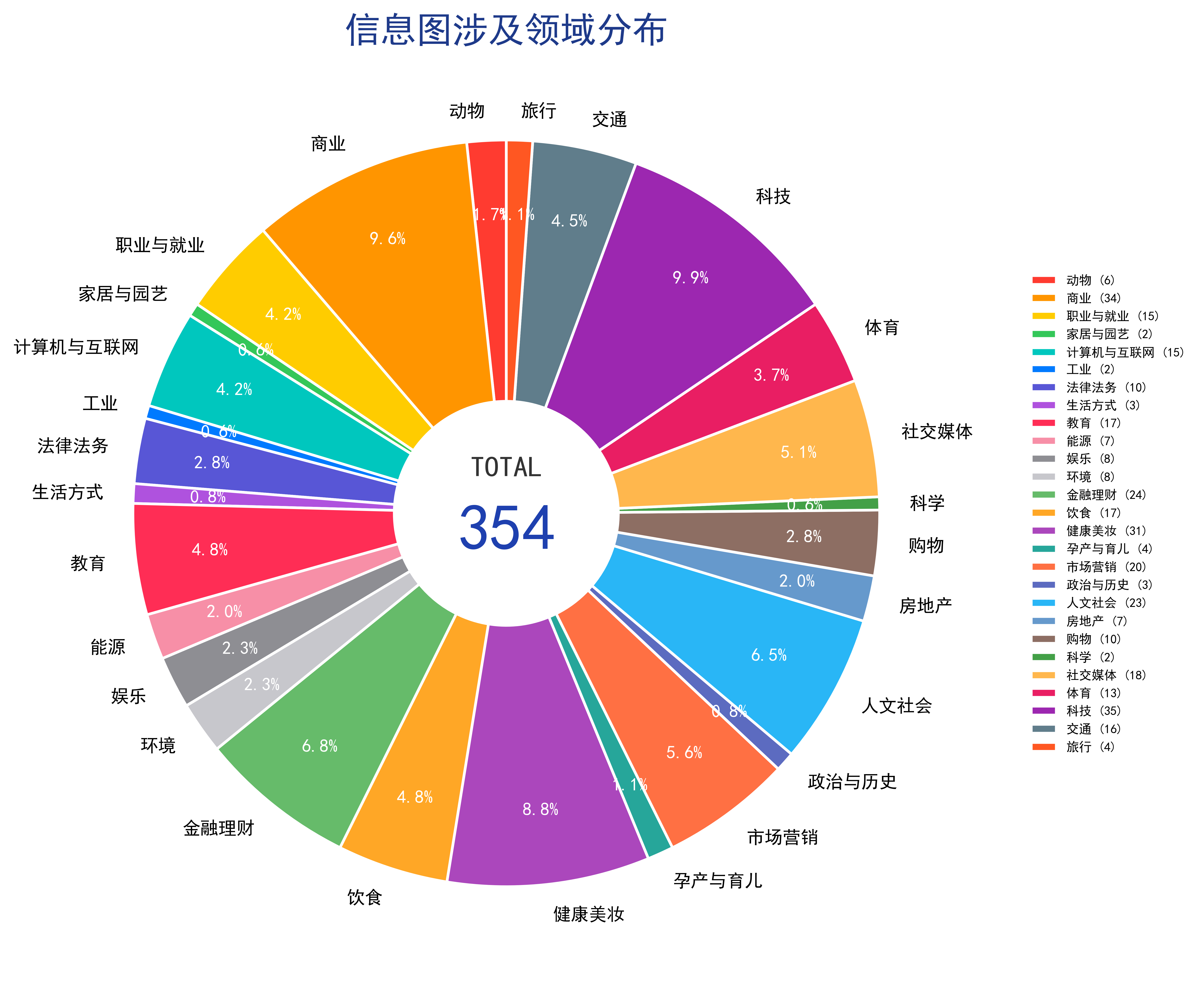
图 41-1:多图表信息图推理数据集领域覆盖分布。该数据集具体包含28个细分领域。
案例A.2.3 子图表全类型清单与布局特征¶
该数据集包含 20 余种常见可视化图表类型,包括:柱状图、地图图、表格图、卡片图、环形图、饼图、气泡图、排名图、堆叠柱状图、折线图、分组柱状图、象形图、树形图、排名卡片图、和弦图、树状图、径向图、径向柱状图、瓦片图、甘特图、散点图、3D 柱状图以及时间轴图表。
单张复合信息图内部采用随机组合排布逻辑:无固定子图搭配规则,创作者原生排版是什么组合,数据集即保留什么组合,出现 “地图 + 表格 + 堆叠柱状 + 象形图”“饼图 + 排名卡片 + 折线时序图” 等任意混搭形式,也是跨图表聚合任务的天然来源。不同图表数据存储逻辑差异化:表格以行列结构化存储数值、地图依托地理分区标注指标、象形图以图标数量表征统计量、时序折线按年份排布变化数据,模型需要适配多格式数据读取规则,再跨格式汇总数据。
图41-2展示了相应的流程或结构。
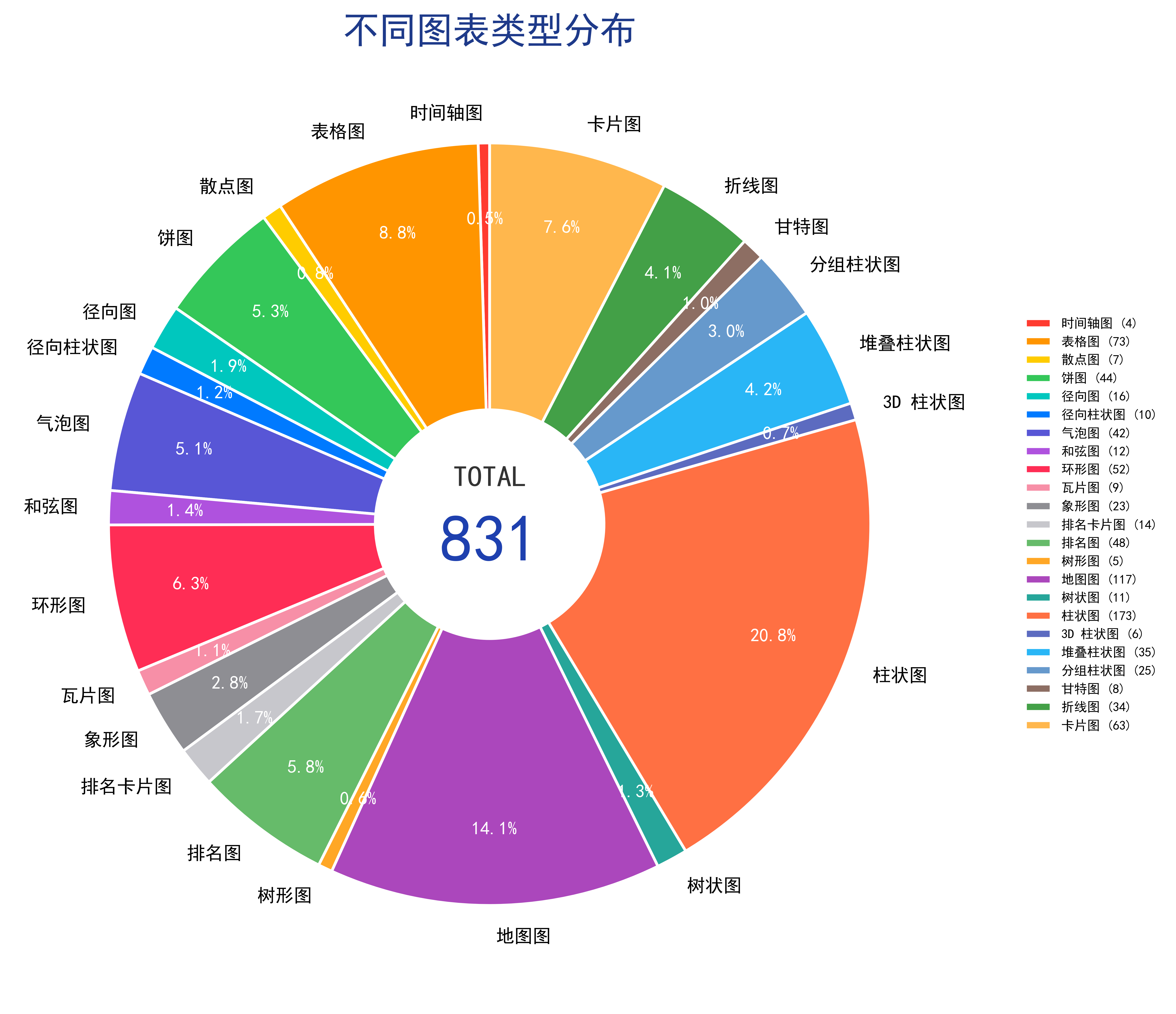
图 41-2:多图表信息图推理数据集子图表类型分布。该数据集具体包含23个子图表类型。
案例A.2.4 子问题全题型清单与组合特征¶
数据集配套子问题脱离单一抽取题型限制,囊括 17 类主流推理设问类型,涵盖数值、分类、求和、均值、中位数、极值、计数、排名、占比、趋势、差值、异常值、假设、可视化、条件、计算及其他类型。
单张信息图内部采用题型随机组合设计逻辑:无固定题型搭配规则,每组问题随机选配多种推理类型,形成 “极值提取 + 差值运算 + 条件推理”、“数值统计 + 占比计算 + 视觉推理” 等多元混搭设问形式,是多步跨图推理任务的设计根基。不同题型推理逻辑差异化:提取类侧重图表定点读数、计算类依托多源数值列式运算、条件类结合图例与限定条件筛选数据、视觉类依靠符号与图文上下文推导结论,模型需要适配多类型推理范式,再串联多步骤完成综合作答。
图41-3展示了相应的流程或结构。
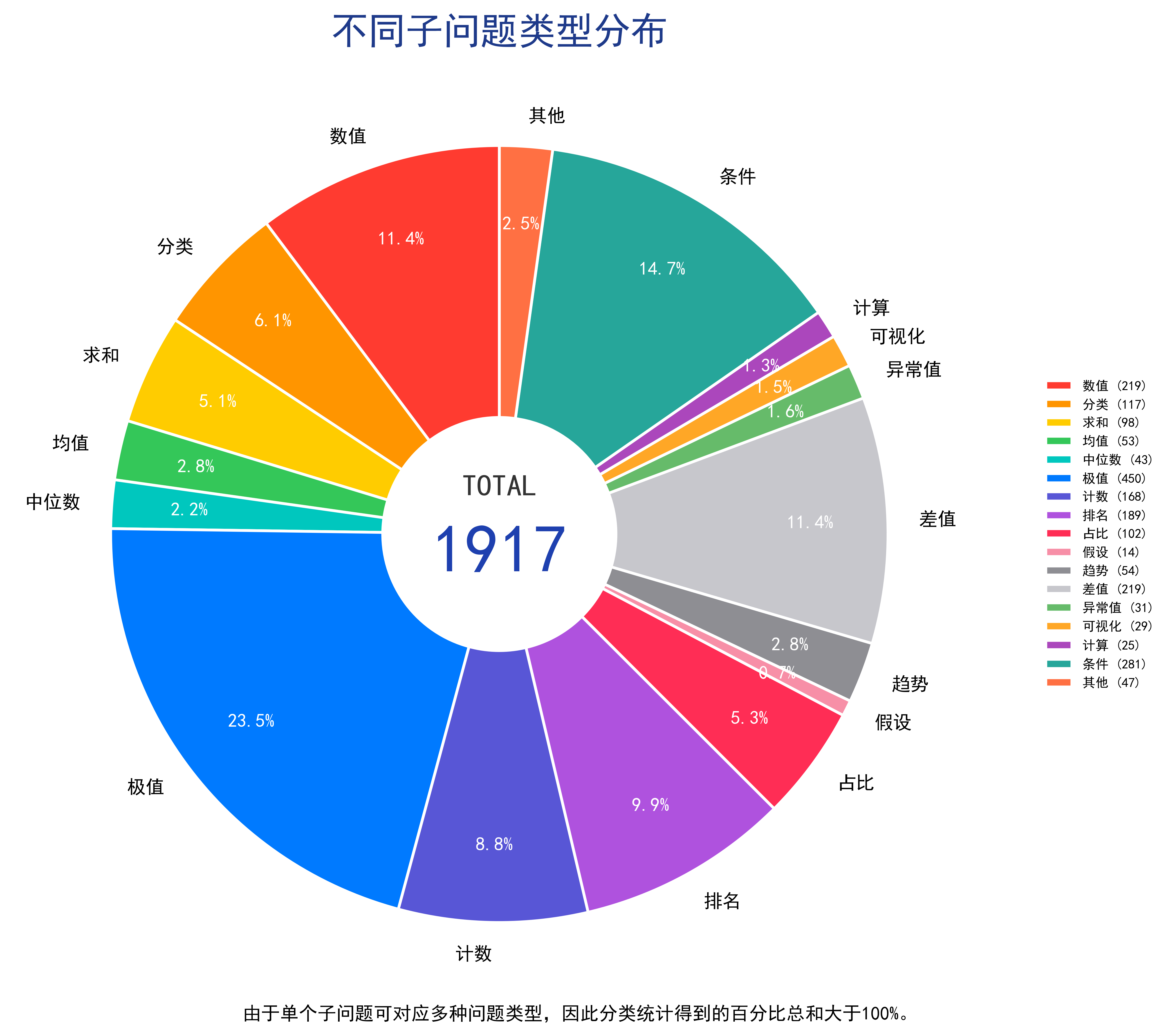
图 41-3:多图表信息图推理数据集子问题类型分布。该数据集具体包含13个子问题类型。
案例A.2.5 三大核心任务标准化定义¶
- 跨图表数据聚合:将分散在整图不同物理分区、不同类型子图表内的异构数据,按照问题限定的筛选条件完成归类、汇总、合并,打破子图物理分割边界,建立跨视图数据关联。例如鲨鱼案例中,各县历史袭击数(Radial Chart)、各州十年累计袭击数(Map Chart and Tabular Chart)、意外致死数据(Bar Chart)分属三个分区,聚合两类分区数据才能完成州际差值计算。该任务是本数据集区别于传统 ChartQA 最核心的标志。
- 多步骤串行运算:子问题按照前后依赖链式排布,前序问题输出答案作为后序问题的计算输入参数,需要依次执行查找、提取、加减、求差、平均、占比等串行算术操作,单条最终答案无法一步算出。鲨鱼样本子问题完整呈现该特征:问题 1 极值查找锁定县域→问题 2 依托县域所属州调取全州总量→问题 3 双州数值做差值运算,三步环环相扣。
- 视觉与上下文推理:综合图例符号、图标标记、页面注释、自然语言正文信息完成非数值类推理,关键信息不直接以数字形式展示在坐标轴中。如样本中 2018 马萨诸塞州致命鲨鱼袭击物种答案(大白鲨),数据来源是图标图例标注(致命袭击图标 + 鲨鱼物种备注),无法通过纯数字读取获得,必须结合视觉符号 + 文本备注综合推导。
案例A.3:样本结构:以鲨鱼袭击案例具象拆解信息图 - 子图 - 问题链 - 推理链路¶
本章依托数据集附带的鲨鱼袭击真实标注样例,从子图分区、链式子问题、证据点位、分步推理路径等维度具象化解析样本结构,落地诠释跨图表推理落地逻辑。
案例A.3.1 单张复合信息图的子图分层结构¶
图 41-4 展示了鲨鱼袭击信息图被拆分后的四个子图区域,便于读者观察跨图表推理所依赖的局部证据。

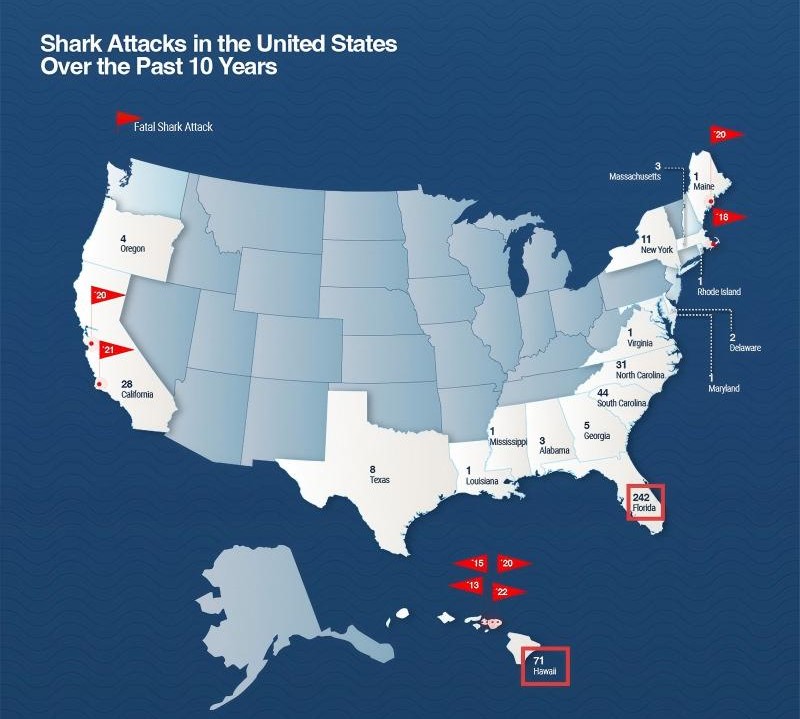

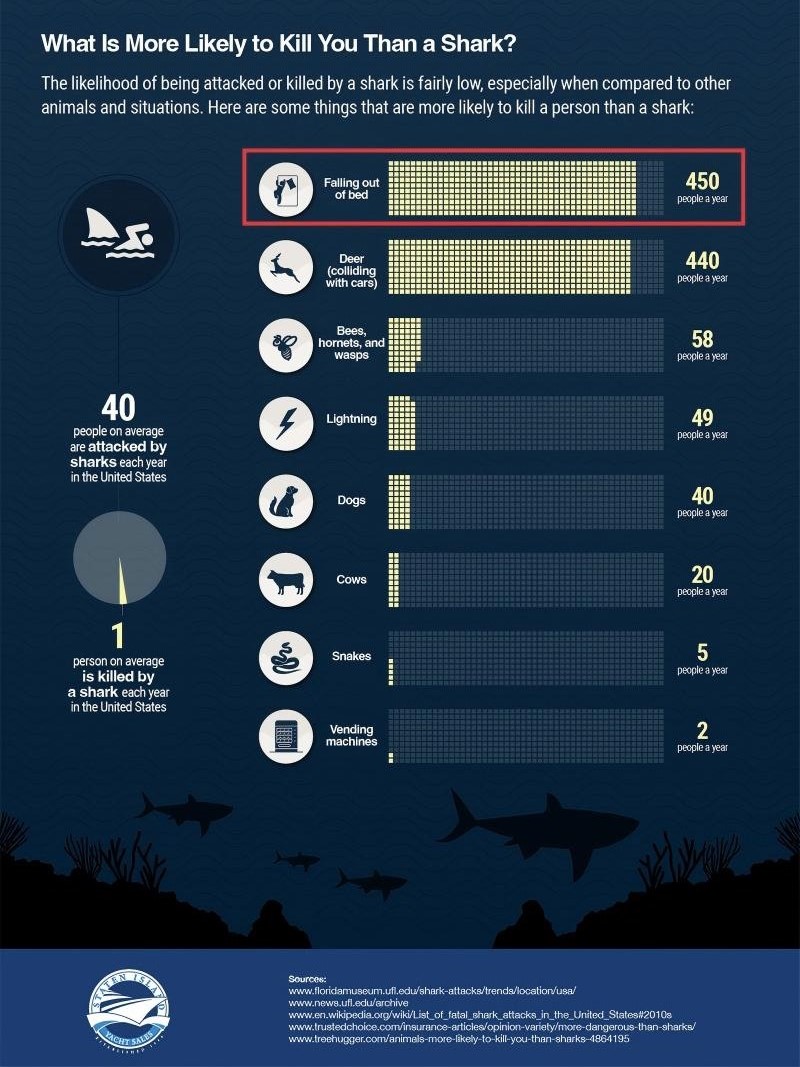
图 41-4:多图表信息图样本(鲨鱼袭击)。该信息图包含四个独立子图,内容涉及美国历史累计鲨鱼袭击县域排行榜、美国近 10 年各州鲨鱼袭击汇总统计、全美年均意外死亡人数统计。原图纵向幅面远大于横向幅面,直接呈现可读性不佳,故拆解为多张子图横向排布展示。
案例原图为一张一体化科普信息图,内部被天然划分为四大独立子图分区,四个子图分属不同图表类型、不同统计口径、不同数据维度,同框排布、共用页面标题与侧边注释:
- 子图 A(Radial Chart):美国历史累计鲨鱼袭击县域排行榜;关键数据:沃卢西亚(佛罗里达州)累计 343 起,为全美县域极值。该子图用于回答极值类问题(子问题 1)。
- 子图 B(Map Chart):美国近 10 年各州鲨鱼袭击汇总统计;关键数据:佛罗里达州 242 起、夏威夷 71 起;支撑子问题 2、子问题 3 数值来源。
- 子图 C(Tabular Chart):美国近 10 年各州鲨鱼袭击汇总统计;关键数据:2018年发生在马萨诸塞州的致命鲨鱼袭击品种为大白鲨;支撑子问题 4 数值来源。
- 子图 D(Bar Chart):全美年均意外死亡人数统计;关键数据:坠床年均致死 450 人、猫无致死案例;支撑子问题 5、子问题 6 作答。
案例A.3.2 链式子问题全链路拆解¶
本案例单图配套 5 道逻辑递进有效子问题 + 1 道不可作答附加题,5 个子问题依次覆盖极值、计数、差值、条件筛选等推理题型,问题前后强依赖,完整复刻人类分步提问逻辑,逐条拆分推理逻辑与证据来源:
表41-1列出了相关字段与出版复核口径。
表41-1:关键要点与工程复核口径。
| 序号 | 问题类型 | 问题原文 | 答案 | 数据来源子图 | 前置依赖关系 |
|---|---|---|---|---|---|
| Q1 | 极值 | 美国哪个郡县历史鲨鱼袭击记录数量最高? | Volusia,FL | 子图 A | 无前置,首步基础信息抽取 |
| Q2 | 计数 | Q1 锁定县域所属州近 10 年鲨鱼袭击合计总数? | 242 | 子图 B | 必须以 Q1 答案(佛罗里达州)作为筛选关键词 |
| Q3 | 差值 | 近十年佛罗里达比夏威夷鲨鱼袭击多多少起? | 171 | 子图 B(FL=242、HI=71,242-71=171) | Q2 确定佛罗里达数值后,再提取夏威夷数据做运算 |
| Q4 | 条件推理 | 2018 年马萨诸塞州高风险鲨鱼袭击涉事物种? | Presumed Great White | 子图 C | 无数值运算,依托符号与文本上下文推理 |
| Q5 | 计数 | 每年坠床意外致死人数? | 450 | 子图 D | 切换第四张子图数据源 |
| Q6 | 计数 | 每年被猫致死人数? | None | 子图 D | 同子图局部数据读取 |
从链路可以直观看到:Q1→Q2→Q3 构成三段式跨子图多步计算链路,Q4 属于纯视觉上下文推理,Q5/Q6 为第三张子图内部数据提取,整组问题完整覆盖数据集定义的三大核心任务。
案例A.3.3 跨图表证据定位规则与推理路径复盘¶
案例A.3.3.1 跨图表证据定位¶
• 关键词联动定位:Q1 输出 “佛罗里达州沃卢西亚”,关键词【佛罗里达】作为检索标签,从子图 B 海量州名中筛选对应数值,实现跨 A→B 子图跳转;
• 分区语义定位:问题关键词 “致死、2018、马萨诸塞” 匹配全局侧边时间轴注释文本,跳出三大数值子图,从非图表文本区提取答案;
• 主题分区定位:关键词 “坠床、猫致死” 匹配子图 D 标题【比鲨鱼更容易致死的意外】,直接锁定对应图。
案例A.3.3.2 完整链式推理路径复盘¶
完整链路:子图 A(县域极值)→关键词提取所属州→跳转子图 B(全州十年数据)→同表提取夏威夷数据→差值运算(Q1-Q2-Q3 闭环);侧边注释(Q4 物种)→子图 C(意外致死 Q5、Q6)。
整条链路中,模型需要完成:子图区域划分、关键词跨图检索、数值存储、多步减法运算、图例文本释义等操作,考核模型的综合能力。
案例A.3.4 不可作答题目设计目的¶
按照数据集统一规范,本张鲨鱼信息图额外附带 1 道无图内依据的不可作答问题,例如 “每年多少人出现意外是因为猫?”,原图中并没有这方面的数据,模型无法作答。该设计用于检验模型幻觉抑制能力,避免大模型无依据编造数字,提升评测鲁棒性。
案例A.4:数据集全流程构建流水线¶
本数据集从原始素材到最终标注数据集落地分为四大标准化工序:原始信息图爬取筛选→多子图区域人工划分→链式问题分层设计→答案人工核验标注。全流程无自动生成图表,保障样本真实度,此外利用大模型辅助生成问答,并依托人工完成校验。
图41-5展示了相应的流程或结构。
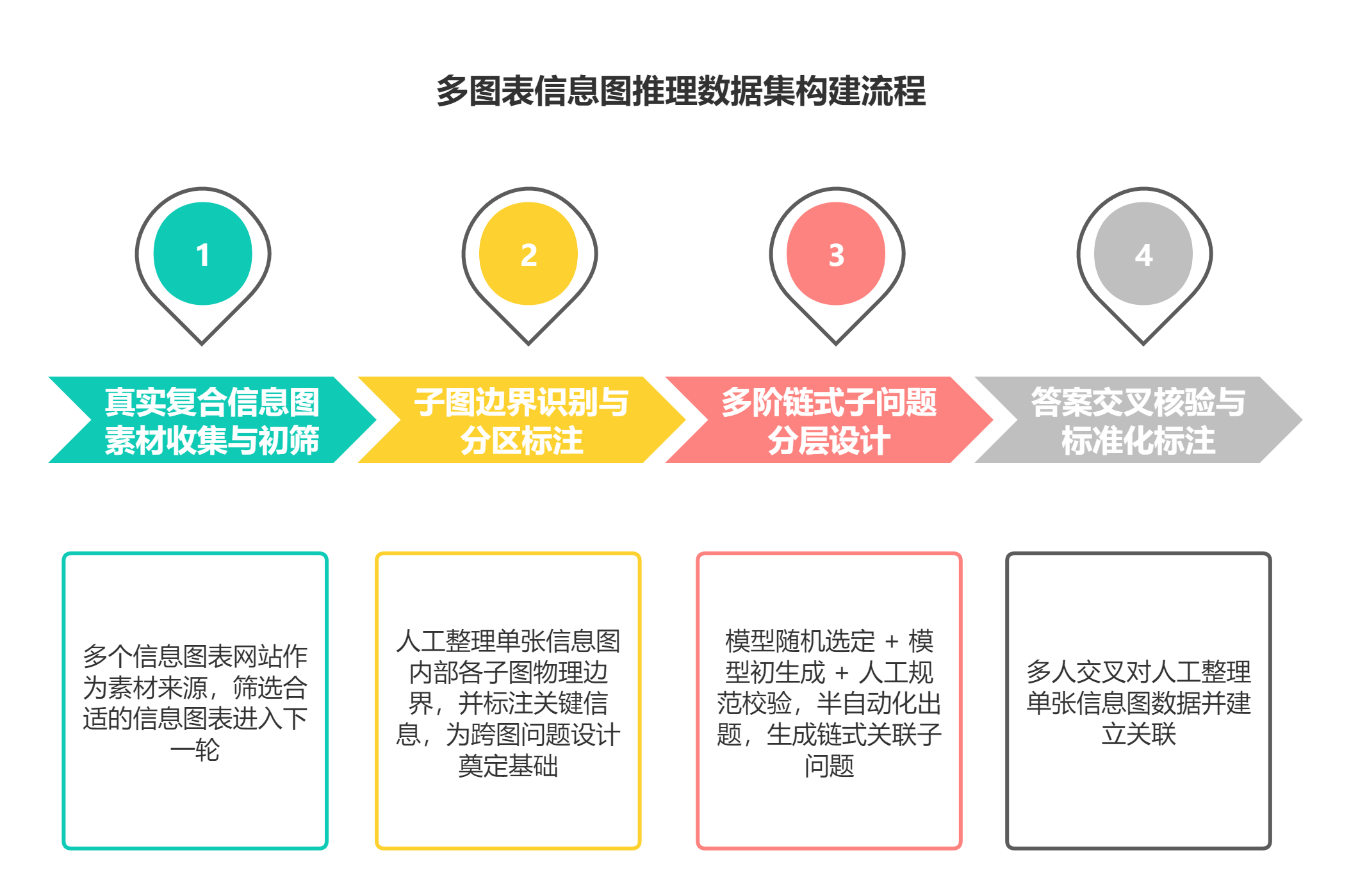
图 41-5:多图标信息图推理数据集四阶段构建流水线图。该流水线包括原始信息图爬取筛选、多子图区域人工划分、链式问题分层设计、答案人工核验标注四大工序。
案例A.4.1 第一步:真实复合信息图素材收集与初筛¶
素材来源:多个真实信息图表网站,包含bee infographic、best infographics、Centers for Disease Control and Prevention、cool infographics、infographic website。
筛选规则:①整图包含≥2 种不同类型子图,满足复合信息图定义;②跨子图存在统计关联指标,具备设计跨图问答的基础条件;③图例、注释、分类标签完整,剔除模糊残缺、关键信息被裁切的劣质图片;④跨 28 大领域均衡抽样,避免单一主题素材扎堆。初筛后保留 354 张有效原图进入下一环节。
案例A.4.2 第二步:子图边界识别与分区标注¶
人工框选单张信息图内部各子图物理边界,区分不同子图(柱状、饼图、表格等);同步标记每个子图的图表类型、统计周期、统计维度(地域 / 时间 / 分类),为后续问题设计划定数据边界,明确哪些数据跨分区分布、可以用于跨图表聚合类问题设计。该步骤是跨图问题能够落地的前置基础。
案例A.4.3 第三步:多阶链式子问题分层设计¶
针对单张复合信息图,采用类型随机选定 + 模型初生成 + 人工精修校验的半自动化出题方案:标注人员先从极值提取、计数统计、差值运算、条件推理、趋势分析、异常判定等全题型池内,随机选取三类目标题型;再依托大模型,以选定题型为约束、以原图多子图分布结构为依据,批量生成一组具备前后关联的链式候选子问题,强制候选题目覆盖预先选定的三类题型。模型初稿生成完成后,由标注人员逐张对照原图图文、图例与分区数据人工审改:优化问题自然语言表述、修正跨图表逻辑漏洞、剔除脱离图表内容的无效设问,同时逐条读图核算、校准标准答案。全样本经该流程迭代打磨后,最终累计产出 1917 条逻辑通顺、答案有据可依的有效子问题,每张配图包含 1 道无图表信息支撑的不可作答题目用于鲁棒性测试。
案例A.4.4 第四步:答案交叉核验与标准化标注¶
采用双人交叉校验标注机制:标注员 A 完成子问题设计和并提供答案,标注员 B 根据子问题独立读图计算复核答案,针对计算错误、图例误读答案进行二次修正;答案格式统一标准化:数值类统一阿拉伯数字、文本类规范专有名词缩写,规避标注歧义。
案例A.5:数据集评测协议:多维度量化评测指标¶
区别于传统 ChartQA 仅采用 “答案字符匹配正确率” 单一指标,本数据集针对多步链式推理特性,设计分层评测协议,从局部到全链路全方位量化模型推理性能,核心评测指标:
案例A.5.1 单步子问题独立正确率¶
定义:不考虑问题前后依赖,单独统计每条子问题最终输出答案与标准答案匹配率。仅考核模型单题读数、计算能力,是基础性能指标。局限:无法体现链式推理的链路连贯性,部分模型可以蒙对最终答案,但中间跨图调取环节出错。
案例A.5.2 全链路链式正确率¶
定义:针对一套前后关联的问题链,全部子问题答案 100% 正确才算整条链路命中,任意前置子问题出错即判定整条链路失败。该指标是本数据集最关键评测维度,精准考核多步推理、跨图联动稳定性,直接反映模型连续推理过程中错误传播程度。例如 Q1 县域识别错误,即便 Q2、Q3 计算公式无误,整条链路直接判定错误。
案例A.5.3 跨图表证据定位准确率¶
新增专属评测指标,统计模型能否精准定位答案对应的子图分区 / 图例区域,考核模型子图分割、跨图检索能力。例如需要从子图 A 取关键词、子图 B 取数值,若模型错误从子图 C 调取数据,即判定证据定位失败。该指标专门对标 Cross-chart aggregation 跨图表聚合任务。
案例A.6:评测难点与模型典型失败模式¶
依托数据集标注规则与样本特征,总结算法落地评测难点与对应的高频失败案例,也是现有 VQA 模型在该数据集上的主要失分点。
案例A.6.1 核心评测技术难点¶
- 图例多义性解读难点:全局图例共用、图标符号替代文字释义,同一图标在不同子图含义存在异化,需要上下文辅助释义,是视觉与文本推理最大难点;
- 跨子图数据筛选难点:同名地域、分类名词分散在不同子图,需要关键词精准匹配筛选,极易出现跨分区数据错配;
- 统计口径区分难点:不同子图统计周期(历史累计 / 近十年 / 年均)不统一,忽略时间口径直接混用数值是高频错误;
- 多步计算错误传导难点:链式问题前置步骤出错,后续所有计算全部失效,错误沿推理链路逐层传播;
- 不可作答问题鲁棒性难点:大模型固有幻觉问题,面对无信息支撑题目强行编造答案,难以精准识别 “无法回答” 场景。
案例A.6.2 模型典型失败模式¶
- 图例误读失效:混淆高风险袭击 / 非高风险袭击图标含义,无法通过符号推导鲨鱼物种,Q4 作答错误
- 跨图表分区混淆:Q1 佛罗里达县域数据取自 A 子图,模型错误使用 C 子图意外数据带入 Q2 计算
- 统计口径遗漏:混淆 “历史累计袭击数” 与 “近十年袭击数”,混用两类不同统计周期数值
- 前置错误逐级传播:Q1 错把夏威夷郡县判定为极值,后续 Q2、Q3 全链条数值全部错误
- 答案幻觉失效:针对无信息支撑的不可作答题目,模型凭空编造数字作答,鲁棒性不达标
案例A.7:数据集现存约束与后续迭代规划¶
该项目当前仅停留在数据集标注阶段,无配套落地基线算法、无已训练基准模型。
案例A.7.1 当前硬性局限¶
- 样本体量约束:受全球高质量原生复合信息图稀缺限制,现有 354 张原图规模偏小,难以支撑超大规模预训练,官方标注后续持续扩充样本库;
- 无基准算法基线:全数据集仅完成数据标注工作,学界、项目方均未发布针对性跨图表推理算法,暂无公开 SOTA 指标可供对标参考;
- 部分信息图原生瑕疵:少量网络原生信息图存在模糊标注、简写不规范问题,小幅提升识别难度,属于素材原生客观缺陷。
案例A.7.2 未来迭代方向¶
- 素材扩容:持续抓取各领域权威出版物信息图,扩充原图与配套子问题总量;
- 基线落地:基于该数据集开发专属跨图表多步推理基线模型,形成公开评测基准;
- 题型拓展:新增占比换算、多条件嵌套筛选、单位换算类高阶问题,持续拔高推理难度。
案例A:小结¶
多图表信息图推理数据集立足于真实世界复合信息图原生形态,跳出单图表问答固有范式,通过跨图表聚合、多步串行计算、视觉上下文推理三大任务重构图表 VQA 评测体系;354 张多子图原图 + 1917 条链式子问题的样本架构,搭配分层评测指标,精准还原人类阅读复合型数据可视化内容的认知逻辑。鲨鱼袭击链式问答案例直观验证:真实信息图推理是多分区数据调取、分步计算、符号释义的复合任务,现有单图优化型 VQA 模型存在明显能力短板。受制于研发进度,数据集目前仅完成标注落地、暂无配套算法,但其填补真实多子图信息图推理基准空白的价值突出,能够成为后续跨模态图表深度推理算法迭代的标准化评测底座,推动图表问答技术从实验室标准化仿真数据走向产业真实落地场景。
案例B:MedImage-ToolVQA:医学图像局部证据与工具调用轨迹¶
MedImage-ToolVQA 采用 MindSpore 体系实现。项目链接:https://github.com/blackkiring/MedImage-ToolVQA-Mindspore。
案例B:学习目标¶
通过本章学习,读者应能够:
- 解释医学图像 VQA 在证据尺度、专业语义、安全边界与评测对象四方面相较普通 VQA 的本质差异。
- 理解将医学图像问答从答案监督扩展为工具行为监督的动机,及其在可审计性与强化学习接口上的价值。
- 掌握以 BiomedParse 区域级信息为基础、由原图、ROI、mask、bbox、目标描述与工具观察图像组成的样本结构。
- 区分 Zoom-in、分割等工具的角色边界,并解释工具调用、参数生成与观察消费如何组织为多轮训练轨迹。
- 评估工具轨迹引入的噪声风险,并结合医学隐私、合规与安全边界设计质量控制与人工复核规则。
案例B.1:医学图像 VQA 与普通 VQA 的差异¶
普通 VQA 的典型问题是“图中有几个人”“桌上是什么物体”“左侧车辆是什么颜色”。这类问题当然也可能很难,但它们通常依赖对象识别、空间关系和常识推断。医学图像 VQA 面对的对象则更隐蔽。许多关键差异并不表现为清晰的物体,而表现为灰度变化、边界模糊、纹理改变、局部密度差异或结构比例异常。对于模型而言,医学图像的难点不只是“识别一个东西”,而是“在有限视觉证据中判断局部表现是否足以支持某个选项”。
这种差异首先体现在证据尺度上。自然图像中的主体通常占据较大比例,而医学图像中的关键区域可能很小。一个肺结节、视网膜微出血点或病理切片中的局部核异型性,往往只占整幅图像的几个像素块。如果模型只能在压缩后的全图表示上回答问题,很容易忽略这些局部线索。即使视觉编码器保留了部分局部特征,语言侧的回答也未必会稳定使用它们。
第二个差异是证据语义需要专业上下文。医学图像里的局部区域并不总能靠日常词汇描述。一个亮点可能是钙化,也可能是伪影;一片边缘不清的区域可能提示炎症,也可能只是成像质量问题。判断它们需要结合解剖位置、模态类型和题目语境。因此,数据不能只让模型“看见局部”,还要让模型理解这个局部为什么与问题相关。
第三个差异是安全边界。普通 VQA 的错误通常表现为描述不准或答案错选;医学图像 VQA 的错误则更容易被读者误解为诊断判断。即便在研究数据集中,问题和答案也必须明确处在训练与评测语境下,而不能面向患者给出建议。这使得医学图像数据工程必须同时处理准确性、可追踪性、隐私和误用风险。
第四个差异是评测对象的变化。普通 VQA 往往只评测最终答案是否正确;医学图像工具调用数据还需要评测取证过程是否合理。模型答对了题,但工具调用区域完全不相关——这样的轨迹并不能说明模型学会了医学图像取证。反过来,模型可能选择了合理的局部区域,却在最终选项上出错,这同样提供了有价值的失败归因线索。数据工程需要把这两类信号分开记录。
从这些差异可以看出,医学图像 VQA 的数据组织必须比普通 VQA 更细。它需要保存全图、局部区域、工具观察、问题、答案和行为轨迹之间的关系。唯有如此,模型训练才有机会从“语言上会答题”进入“视觉上会取证”。
案例B.2:从答案监督到工具行为监督¶
传统 VQA 数据的监督目标很明确:给定图像和问题,输出答案。这种形式简单、稳定,便于评测。但它有一个不足:推理过程被压缩到不可见的模型内部。我们不知道模型是否真的看了图,不知道它关注了图中的哪个区域,也不知道它是否因为局部证据而做出选择。对于医学图像任务而言,这种不可见性会带来明显风险。
工具行为监督试图补上这一层。它不是要求模型直接暴露完整思维过程,而是把可执行的行为节点写进样本结构。例如:模型先判断需要局部放大,调用 Zoom-in;工具返回一张局部 crop;模型再根据局部 crop 继续判断。这里的训练信号不再只有最终答案,而是包括了工具选择、参数生成、观察消费和答案生成。
这种监督方式有三个好处。第一,它让模型学习一种更接近真实工作的视觉取证流程——医学图像分析很少是一次性全图扫视就结束的过程,局部复查、边界确认和区域对照都很常见。第二,它让训练数据具备更好的可审计性:工具调用参数、观察图像和最终答案之间的关系可以被检查,错误也更容易定位。第三,它为后续强化学习提供了环境接口——只要工具调用和观察返回被结构化,模型就可以在规则奖励或环境反馈中进一步优化工具策略。
当然,工具行为监督也不是万能的。它会引入新的数据噪声:工具可能分割错误,bbox 可能偏离目标,模型可能为了迎合格式而过度调用工具。数据工程必须承认这些风险,并通过校验和复核降低其影响。工具调用数据的目标不是制造“看起来更复杂”的样本,而是让每个工具动作都能解释它解决了哪类视觉不确定性。
因此,MedImage-ToolVQA 的基本思想可以概括为一句话:将医学图像问答中原本隐含的局部取证过程,显式转化为可训练、可检查、可评测的多轮样本。它保留答案监督,但不满足于答案监督;它引入工具轨迹,但不把工具调用当成形式装饰。
案例B.3:数据对象与规模概览¶
MedImage-ToolVQA 面向的是医学图像多选问答。样本以 BiomedParse 提供的区域级视觉信息为基础 (Zhao et al. 2025),包含原始医学图像、目标区域、mask、bbox、目标描述、问题、候选选项、正确答案,以及可能由工具返回的局部观察图像。最终整理后的训练数据共有 24,992 条记录,任务形态以多选医学图像 VQA 为主。
在这些记录中,多图样本占有重要比例。统计显示:19,945 条记录包含 3 张原始或工具相关图像,2,471 条包含 1 张图像,1,383 条包含 4 张图像,1,193 条包含 2 张图像。这一分布说明,数据集中相当多的样本并非单纯的“原图加问题”,而是保存了工具链产生的观察图像——局部 crop、mask overlay 或分割结果会作为新的视觉证据进入轨迹。
表41-2列出了相关字段与出版复核口径。
表41-2:指标、计算方式与解释。
| 指标 | 数值 | 数据工程含义 |
|---|---|---|
| 总记录数 | 24,992 | 可用于训练与评测的医学图像工具调用样本规模 |
| 区域来源 | BiomedParse | 以 ROI、mask、bbox 和目标描述组织局部证据 |
| 问题形式 | 多选医学图像 VQA | 便于答案校验和规则奖励设计 |
raw_images = 3 |
19,945 | 最常见的工具增强轨迹形态 |
raw_images = 1 |
2,471 | 直接视觉推理或单图样本 |
raw_images = 4 |
1,383 | 可能包含额外工具观察或多步轨迹 |
raw_images = 2 |
1,193 | 原图加单个工具观察的形态 |
| 答案 A | 9,986 | 正确选项分布,需要关注选项偏置 |
| 答案 B | 7,177 | 正确选项分布,需要关注选项偏置 |
| 答案 C | 5,473 | 正确选项分布,需要关注选项偏置 |
| 答案 D/E | 2,356 | 长尾选项,评测时不宜只看总体准确率 |
这张表不应被理解为单纯的规模展示。它真正提示的是三个工程问题。第一,答案选项并不完全均衡,训练和评测都需要关注选项偏置。第二,多图记录占比较高,说明工具观察已成为数据结构的一部分。第三,区域级来源决定了样本质量高度依赖 ROI、mask 和 bbox 的准确性——如果区域本身不可靠,后续问题生成和工具轨迹都会受到影响。
我们可以把 MedImage-ToolVQA 看作一种“介于 VQA 数据集和 Agent 轨迹数据之间”的数据对象。它仍有图像、问题和答案,因此属于 VQA;但它又记录工具动作和观察结果,因此也属于 Tool-Use 数据。它的价值不只是提供更多医学题,而是提供一种将视觉证据、工具行动和答案监督放入同一条轨迹的组织方式。
案例B.4:ROI、mask 与 bbox:局部证据如何进入样本¶
医学图像工具调用数据的第一步,是让“局部证据”具备可操作的表示。自然语言可以说“右肺上叶靠近胸膜处有一个小结节”,但模型和工具需要更明确的接口。ROI、mask 和 bbox 就承担了这个接口角色。
ROI 是感兴趣区域,表示样本希望模型关注的局部范围。bbox 用四个坐标描述该范围的矩形边界,适合裁剪和粗定位。mask 提供更细的像素级区域,适合分割、overlay 和边界复核。目标描述则将视觉区域转化为医学语义,例如“肺部结节”“肝脏病灶”“血管结构”或“组织切片中的局部异常”。这四类信息结合起来,构成医学图像工具调用样本的证据基础。
如果只有 bbox,数据可以完成局部放大,但未必能表达精细边界。如果只有 mask,数据可以表达区域形状,却不一定便于模型生成工具调用参数。如果只有目标描述,模型可能知道语义对象,却无法验证其位置。因此,在构建医学图像工具调用数据时,bbox、mask 和 description 通常需要共同出现,分别服务于裁剪、分割和语义定位。
ROI 的另一个作用是防止问题退化为纯文本医学题。一个医学多选题如果不依赖具体图像区域,模型凭一般医学知识就能回答。例如,“肺结节通常出现在什么器官中”并不是有效的图像问题;“图像中局部结节的边界和密度更接近哪种描述”才需要视觉证据。ROI、mask 和 bbox 使数据构建者可以检查问题是否真的与局部区域相关。
但局部证据也会带来一个常见陷阱:定位泄漏。如果问题直接写成“方框中的区域是什么”或“mask 标记处显示什么”,模型就不需要学习主动定位,也不需要学习工具调用——它只是在遵循文本里已经暴露的提示。因此,问题生成阶段必须避免将 bbox、mask 或 ROI 以显性方式写入题干。好的问题应当暗示需要局部观察,而不直接告诉模型标注位置。
在这个意义上,局部证据既是训练资源,也是约束条件。它帮助我们构建样本,也帮助我们过滤样本。一个合格的 MedImage-ToolVQA 样本,应当让问题与 ROI 有明确关系,但不让问题泄漏 ROI 的标注方式;让工具轨迹能够利用 bbox 或 mask,但不让模型将这些标注当作题干中已经给出的答案。
案例B.4.1 问题与选项设计:让题目真正依赖图像¶
医学图像工具调用数据的质量,很大程度上取决于问题本身是否设计得合理。工具轨迹再完整,如果题目不需要局部视觉证据,模型也不会真正学会取证。一个好的医学图像 VQA 问题,应当同时满足三个条件:与图像中的具体区域相关;不直接泄漏区域标注;选项差异能够通过视觉证据来区分。
第一点是区域相关性。题目不能只问一般医学知识,也不能只问图像模态或器官名称这类过于宽泛的信息。以肺部影像为例,“肺结节通常有哪些影像表现”更像知识问答;“图像中目标区域的边界和密度更符合哪种描述”才更接近图像问答。前者训练的是医学知识回忆,后者训练的是视觉证据判断。对工具调用数据而言,后者才有机会让模型学会局部观察的价值。
第二点是避免定位泄漏。构建者手里有 bbox 和 mask,很容易在题目中写出“框选区域”“标注处”“mask 内”这类表达。这些题目看似清楚,实则破坏了工具调用数据的目标——模型已被题干告知要看哪里,后续工具调用只是照着题干执行,而非根据问题和全图自主判断关注区域。更合适的做法是让题目自然指向某个医学现象,而非指向标注机制。例如可以说“图像中局部异常的形态更接近哪一项”,而不应说“红框内异常的形态更接近哪一项”。
第三点是选项可区分性。多选题的选项不能只是同义改写,也不能全部依赖外部医学常识。选项之间应当围绕可观察的视觉特征形成差异,例如边界清晰与否、分布局灶还是弥漫、密度或信号强度是否异常、是否更像伪影或正常结构。这样,模型才需要通过图像证据来排除选项。若选项设计不佳,即使题干与图像有关,训练信号也会变弱。
在实际构建中,题目设计还要考虑难度梯度。如果所有题目都很简单,模型会倾向于直接回答;如果所有题目都很难,工具轨迹可能变得过长且不稳定。更合理的混合方式是保留一部分全图可答样本、一部分需要局部放大的样本、一部分需要分割或边界确认的样本。这样,模型才能学到工具调用的条件,而非只学到固定格式。
还需要注意的是,医学图像问题不应鼓励模型作出超出数据任务范围的临床判断。多选题可以要求模型在给定选项中选择最符合图像表现的一项,但题干和解释不应扩展为“患者应当如何治疗”或“可以确诊为某疾病”。这种边界对医学数据尤其重要,因为读者和使用者很容易把视觉判断误读为诊断建议。
因此,问题与选项设计可以看作 MedImage-ToolVQA 的第一道质量门槛。它决定样本是否值得进入后续工具轨迹合成。若题目本身没有图像依赖性,后续再精细的工具调用也只是形式上的复杂化;若题目合理,工具轨迹才可能成为真正的行为监督。
案例B.4.2 观察图像的生命周期¶
工具调用数据中的观察图像并不是普通附图。它们从原始图像中派生出来,又在训练轨迹中作为新的输入返回给模型。这个过程可以理解为观察图像的生命周期:从区域证据出发,生成局部观察,进入多轮对话,最后成为可审计的训练元数据。
第一步是观察图像生成。局部 crop 通常由 bbox 决定,mask overlay 由原图与分割结果叠加而成,语义分割图则来自文本驱动或 bbox 驱动的工具输出。这里需要明确一点:观察图像不应只追求视觉上好看,而应追求证据上可用——它要保留足够局部细节,同时尽量避免把无关背景放大成误导信息。
第二步是观察图像绑定。工具返回的新图像必须和原始图像、工具参数及对话轮次对应起来。若图像索引错乱,模型就可能把某一次工具返回误认为另一张图像;若 bbox 与观察图之间没有记录关系,后续审计也无法判断工具是否真的看了目标区域。因此,多图样本中的图像顺序和引用方式必须稳定。
第三步是观察图像消费。数据样本不能只在工具调用后机械地插入一张图,还要让后续回答体现对观察图的使用。模型应当基于观察图确认或修正判断,而不是继续凭原图和题干作答。对于教学型样本,解释可以明确写出“局部观察显示了什么,因此排除哪些选项”;对于训练型样本,也至少应让最终答案与观察证据保持一致。
第四步是观察图像审计。派生图像同样需要脱敏、质量检查和版本记录。局部放大图可能把原图中的角标或编号放大;mask overlay 可能因颜色或透明度设置影响读者判断;分割图可能错误覆盖邻近结构。这些问题若不记录,模型训练中的视觉证据就会变得不可靠。
观察图像生命周期的关键,是不要把工具返回结果当成一次性中间产物。对于工具调用数据来说,它既是训练输入,也是审计对象;既服务模型学习,也服务数据质量解释。只有把这一层关系维护好,多图轨迹才不会退化为“原图旁边多放几张图”。
案例B.5:数据构建的概念流程¶
MedImage-ToolVQA 的构建流程可以概括为六个阶段:区域样本整理、问题生成、质量校验、工具观察生成、轨迹合成和训练封装。每个阶段都不是孤立步骤,而是在维护同一条证据链。为了让读者看到这些阶段如何进入 MindSpore 工程实现,下面不再使用抽象伪代码,而是把 merge、make_vqa、verify、makereasoning 和 make_sft 写成一组以 MindRecord、mindspore.dataset 和 vllm-mindspore 为核心的示例入口。其中,vllm-mindspore 的官方代码库采用 AtomGit 地址 https://atomgit.com/mindspore/vllm-mindspore。示例省略了具体路径、脱敏规则和异常处理细节,但保留了数据对象、质量门禁和训练封装之间的关系。
案例B.5.1 区域样本合并:写入 MindRecord¶
merge 的重点是把来自不同解析工具或中间结果的区域证据统一成 MindSpore 可读取的数据资产。这里不展开完整工程代码,只保留核心数据契约:按 image_id 和 region_id 去重,保留 bbox、mask、目标描述和来源信息,并写入 MindRecord。
代码清单41-1给出了Python 实现片段。
from mindspore.mindrecord import FileWriter
schema = {
"image_id": {"type": "string"},
"region_id": {"type": "string"},
"bbox": {"type": "int32", "shape": [-1]},
"mask_path": {"type": "string"},
"target_desc": {"type": "string"},
"source": {"type": "string"},
}
writer = FileWriter("region_pool.mindrecord", shard_num=4, overwrite=True)
writer.add_schema(schema, "region evidence schema")
writer.write_raw_data(deduplicate_regions(raw_regions, keys=["image_id", "region_id"]))
writer.commit()
代码清单41-1:Python 实现片段。
案例B.5.2 LLM 服务:使用 vllm-mindspore¶
make_vqa 和 makereasoning 需要调用本地部署的大模型。MindSpore 体系下可以通过 vllm-mindspore 提供 OpenAI 兼容服务;其官方代码库采用 AtomGit 地址 https://atomgit.com/mindspore/vllm-mindspore。
代码清单41-2给出了命令行运行示例。
代码清单41-2:命令行运行示例。
代码清单41-3给出了Python 实现片段。
代码清单41-3:Python 实现片段。
案例B.5.3 问题生成:从 MindDataset 读取区域证据¶
make_vqa 从 MindDataset 读取区域证据,生成问题、候选选项和标准答案。构造 prompt 时需要隐藏 bbox、mask 路径和区域编号,避免把标注机制泄漏到题干中。
代码清单41-4给出了Python 实现片段。
import mindspore.dataset as ds
dataset = ds.MindDataset("region_pool.mindrecord", shuffle=False)
for row in dataset.create_dict_iterator(output_numpy=True):
prompt = build_vqa_prompt(row, hide_fields=["bbox", "mask_path", "region_id"])
reply = client.chat.completions.create(
model="Qwen/Qwen3-vl-8B",
messages=[{"role": "user", "content": prompt}],
temperature=0.2,
)
write_jsonl("vqa_candidates.jsonl", parse_vqa(reply.choices[0].message.content, row))
代码清单41-4:Python 实现片段。
案例B.5.4 质量校验:形成自动门禁结果¶
verify 不直接改写样本答案,而是给样本附加质量门禁结果。只有字段完整、图像依赖明确、区域一致且工具 JSON 合法的样本,才进入后续轨迹合成。
代码清单41-5给出了Python 实现片段。
gates = {
"complete": has_required_fields(sample),
"image_dependent": requires_visual_evidence(sample),
"region_consistent": align_question_answer_roi(sample),
"tool_json_valid": validate_tool_schema(sample),
}
sample["review_status"] = "pass" if all(gates.values()) else "revise"
sample["quality_gates"] = gates
代码清单41-5:Python 实现片段。
案例B.5.5 轨迹合成:把工具观察写回对话¶
makereasoning 的核心不是生成更长的解释,而是把工具调用和工具返回图像变成下一轮上下文。若样本不需要局部证据,则保留直接视觉推理路径。
代码清单41-6给出了Python 实现片段。
observation = run_visual_tool(sample) if needs_local_evidence(sample) else None
prompt = build_reasoning_prompt(sample, observation)
reply = client.chat.completions.create(
model="Qwen/Qwen3-vl-8B",
messages=[{"role": "user", "content": prompt}],
temperature=0.1,
)
sample["trajectory"] = build_tool_trajectory(sample, observation, reply)
代码清单41-6:Python 实现片段。
案例B.5.6 SFT 封装:训练记录继续写入 MindRecord¶
make_sft 将多轮消息、图像引用、答案和质量标签写入训练用 MindRecord。SFT 训练侧再通过 mindspore.dataset.MindDataset 加载,并按 batch 进入模型微调流程。
代码清单41-7给出了Python 实现片段。
schema = {
"messages": {"type": "string"},
"images": {"type": "string"},
"answer": {"type": "string"},
"quality": {"type": "string"},
}
writer = FileWriter("tool_sft.mindrecord", shard_num=8, overwrite=True)
writer.add_schema(schema, "tool-use SFT schema")
writer.write_raw_data(pack_sft_records(tool_trajectories))
writer.commit()
train_ds = ds.MindDataset("tool_sft.mindrecord").shuffle(4096).batch(8)
代码清单41-7:Python 实现片段。
图41-6展示了相应的流程或结构。

图41-6:MedImage-ToolVQA 数据构建概念流程。流程的重点不是脚本顺序,而是证据链和行为链如何在各阶段被保留下来。
第一阶段是区域样本整理。来自医学图像解析工具的区域级结果需要被合并、去重和规范化。对于同一张医学图像,可能存在多个候选区域;同一个区域也可能在不同中间结果中重复出现。数据工程需要按区域标识进行去重,而非简单按图像去重,否则会误删同图中的多个病灶或结构。
第二阶段是问题生成。构建器根据原图、目标区域、mask、bbox 和目标描述生成医学多选题。问题应当像普通医学图像 VQA 一样自然,不应暴露“框内”“mask 中”这类标注信息。候选选项需要能够区分局部视觉特征,不能只是泛泛的医学概念列表。
第三阶段是质量校验。系统需要检查问题结构、选项质量、答案一致性和区域 grounding。这里的 grounding 并不是传统目标检测意义上的“框是否准”,而是问题、答案和目标区域之间是否存在合理关系。若问题与 ROI 无关,即使答案文本正确,也不适合作为工具调用训练样本。这一阶段还承担一项重要任务:识别不依赖图像也能回答的题目,防止样本退化为纯文本医学问答。
第四阶段是工具观察生成。对于需要工具增强的样本,构建流程会生成局部 crop、mask overlay 或分割观察图。这些图像不是装饰,而是后续多轮轨迹中的新输入。模型在训练时会看到工具调用之后出现的观察图,从而学习如何消费工具返回结果。
第五阶段是轨迹合成。经过校验的样本被组织成多轮结构:模型先观察原图和问题,决定是否调用工具;工具返回观察图;模型继续推理并输出答案。约 90% 的样本采用工具增强路径,约 10% 保留为直接视觉推理样本。保留直接样本是必要的,因为并非所有问题都应调用工具。若训练数据暗示“每题都必须调用工具”,模型会学到低效甚至错误的行为策略。
第六阶段是训练封装。轨迹会被整理为 SFT 对话记录和可用于 RL 的环境输入。SFT 强调格式和示范,RL 强调策略优化和奖励反馈。二者使用相近的样本基础,但训练目标不同,封装方式也不同。训练封装的关键不是简单拼接文本,而是将 assistant 的工具调用、user 侧的观察图像和最终答案拆成可训练的多轮结构。
这个流程最重要的原则是:证据不能在中间丢失。问题来自哪张图、对应哪个区域、工具观察如何生成、答案如何校验,都需要被追踪。否则,最终数据虽然表面上有工具调用,实际上却无法证明这些工具动作是否与医学图像证据有关。
案例B.6:三类工具的角色与边界¶
MedImage-ToolVQA 中涉及三类视觉工具:Zoom-in、BiomedParse 和 SAM2。它们分别对应医学图像分析中三种常见需求:看得更近、按医学语义定位、按几何提示获取更精细分割。
Zoom-in 的功能最直观:根据 bbox 裁剪局部区域,让模型获得更高分辨率的局部观察。它适合处理全图中较小、细节不足的区域。例如,肺部小结节在全图中可能只占很小范围,放大后才能更清楚地观察边界和密度。Zoom-in 的风险也很明显:bbox 若偏移,裁剪图就可能错过关键证据;裁剪过窄,又可能丢失周围解剖上下文。
BiomedParse 更偏医学语义分割。它接受目标图像和文本描述(例如“lung nodule”或“liver lesion”),返回与医学语义相关的分割结果。这类工具的优势是能将自然语言目标与医学图像区域联系起来,适合需要语义定位的场景。风险在于,医学图像模态差异很大,文本描述若不准确,工具可能返回错误区域,或将相似结构误分割为目标。
SAM2 是 bbox prompt 驱动的通用分割工具 (Ravi et al. 2025)。它不依赖医学语义,而是根据几何提示在图像中生成更精细的 mask。对于已有候选框但需要更明确边界的样本,SAM2 可以提供补充观察。它的主要风险是过度依赖 bbox 质量:bbox 若覆盖背景或相邻结构,分割结果也会受到影响。
表41-3列出了相关字段与出版复核口径。
表41-3:风险、控制措施与复核口径。
| 工具 | 主要输入 | 返回结果 | 适合解决的问题 | 需要控制的风险 |
|---|---|---|---|---|
Zoom-in |
图像索引、bbox 坐标 | 局部 crop 图 | 局部太小、全图分辨率不足、需要观察细节 | bbox 偏移、过度裁剪、上下文丢失 |
BiomedParse |
图像索引、医学语义描述 | 医学结构或病灶分割图 | 需要按医学概念定位结构或病灶 | 描述不准、模态泛化不足、误分割 |
SAM2 |
图像索引、bbox 坐标 | bbox prompt 对应的 mask | 已有候选框,需要边界细化 | bbox 质量依赖强、可能包入背景 |
这三类工具共同构成了一个有限但有代表性的行动空间。模型不需要拥有无限工具,而需要在有限工具中做出合理选择。对于数据工程来说,工具数量并非越多越好——工具越多,调用格式、错误模式和质量校验都会变复杂。更稳妥的做法是先选择少量边界清晰、输入输出可验证的工具,让模型学会基本的取证闭环。
工具边界还需要在系统提示和数据说明中清楚表达:Zoom-in 是裁剪工具,不是诊断工具;BiomedParse 是医学图像分割工具,不是病理结论生成器;SAM2 是通用分割工具,不理解临床语境。只有把这些边界写清楚,模型训练才不容易把“获取视觉证据”误学成“替代专业判断”。Segment Anything 与 MedSAM 等工作也提醒我们,promptable segmentation 的工程能力需要与医学场景解释的边界分开理解 (Kirillov et al. 2023; Ma et al. 2024)。
案例B.7:工具调用轨迹如何组织成多轮样本¶
工具调用轨迹的核心是多轮结构。它不是把工具调用写在同一段文本中,而是将工具动作和工具观察分开,让模型在训练时经历一个“行动—观察—继续判断”的过程 (Yao et al. 2023)。
图41-7展示了相应的流程或结构。

图41-7:工具调用多轮轨迹结构。工具观察以新的图像输入形式返回,模型必须基于观察图继续推理,而非仅生成一个形式正确的调用。
一个简化的轨迹可以分成四步。第一步,用户给出原始图像、问题和候选选项。第二步,助手根据全图和问题判断需要局部证据,输出结构化工具调用。第三步,工具环境返回新的观察图像,通常以用户消息或环境消息的形式插入对话。第四步,助手结合原图和观察图继续判断,输出答案。
下面是一个教学型示例。它不对应具体病例,只用于说明结构。
代码清单41-8给出了视觉推理提示词示例。
User:
<image>
Question:
图像中目标区域的影像表现更接近以下哪一种描述?
Options:
A. 边界较清楚的局灶性异常
B. 弥漫性背景改变
C. 与正常解剖结构一致
D. 主要由成像伪影造成
Assistant:
<think>
题目要求判断局部表现。全图能够提示大致位置,但局部边界和密度仍不够清楚,
需要先放大疑似区域,再比较选项。
</think>
<tool_call>
{"name":"Zoom-in","arguments":{"target_image":1,"bbox_2d":[132,184,278,336]}}
</tool_call>
User:
<image>
工具返回了局部放大观察图,请继续根据新观察判断。
Assistant:
<think>
局部观察图显示目标区域与周围背景存在可分辨差异,边界较清楚,
不符合弥漫性改变,也不宜仅解释为伪影。
</think>
<answer>A</answer>
代码清单41-8:视觉推理提示词示例。
这个样例展示了工具轨迹的几个关键点。首先,工具调用参数必须结构化,不能只写“请放大一下”。其次,工具返回必须成为新的多模态输入,而非在文本里简单描述“已经放大”。再次,最终答案应当消费观察结果,说明局部观察如何改变或支持判断。最后,轨迹中不应出现诊断性断言,而应围绕题目选项和视觉证据展开。
多轮轨迹还可以包含多次工具调用。例如,模型先用 Zoom-in 观察局部区域,再用 SAM2 获取更精细边界;或者先用 BiomedParse 按语义定位病灶,再用局部观察确认其外观。多工具轨迹的价值在于呈现递进式取证,但这也要求更严格的校验——每多一次工具调用,就多一个参数错误、观察错配或过度调用的风险。
因此,MedImage-ToolVQA 中保留一部分直接视觉推理样本是合理的。直接样本告诉模型:工具不是必须动作,而是按需动作。一个成熟的医学图像 Agent 不应为了展示工具能力而调用工具,而应在全图信息不足、局部细节关键、区域边界需要确认时调用工具。这种“按需”才是工具行为监督真正想训练的策略。
案例B.7.1 一个样本的三层读法¶
为了理解工具调用样本,读者可以把每条记录分成三层来读。第一层是题目层:图像、问题、选项和答案,回答“这是一道什么题”。第二层是证据层:ROI、bbox、mask、局部观察图和目标描述,回答“这道题为什么需要图像,以及证据大致在哪里”。第三层是行为层:模型在多轮对话中如何调用工具、如何接收观察、如何继续判断,回答“模型应该怎样行动”。
如果只读题目层,MedImage-ToolVQA 与普通 VQA 的区别并不明显。读者看到的仍然是一张医学图像和一道多选题。这也是许多数据集介绍容易停留在表面的原因:只展示题目和答案,看不出数据范式的变化。真正的差异要到证据层和行为层才会显现。证据层说明问题并非凭空生成,而是来自可追踪的局部区域;行为层说明模型不是一次性回答,而是在工具空间内进行取证。
三层读法也有助于排查样本质量。若题目层合理,但证据层缺失,那么样本可能只是普通 VQA;若证据层存在,但行为层没有使用工具观察,那么样本可能只是附带标注的 VQA;若行为层完整,但题目层本身文本可答,那么工具调用又会变成形式化动作。只有三层同时成立,样本才真正体现医学图像工具调用数据的价值。
从训练角度看,三层分别对应不同损失或评测关注点。题目层决定最终答案监督;证据层决定图像 grounding 和区域一致性;行为层决定 Tool-Use 格式和行动策略。一个训练系统可以只使用其中一部分,但使用越少,模型学到的能力就越窄。例如只使用题目层,可以训练医学 VQA;加入证据层,可以训练或评测局部 grounding;再加入行为层,才进入医学图像 Agent 的取证轨迹学习。
从数据治理角度看,三层也对应不同责任人。医学内容专家更适合审查题目和答案是否合理;视觉数据工程师更适合审查 ROI、mask 和观察图是否一致;Agent 或训练工程师更适合审查工具格式、轨迹结构和奖励接口是否稳定。把这些层次分清楚,能减少协作中的模糊责任。否则,一个样本出错时,团队很容易只说“这条数据不好”,却说不清到底是题目不好、区域不好,还是轨迹不好。
案例B.7.2 工具轨迹与普通 CoT 的区别¶
工具调用轨迹有时会被误解为一种更复杂的 CoT(Chain-of-Thought)数据。二者确实都涉及中间过程,但训练含义并不相同。普通 CoT 主要在文本空间中展开:模型生成一段推理说明,再输出答案。工具轨迹则包含外部行动和环境反馈:模型输出工具调用,环境返回新的观察,模型再基于观察继续判断。它不只是“想得更详细”,而是“看到了新的东西”。
这一差异在医学图像中尤其重要。若模型只生成一段文字推理,它可能写出“需要观察局部区域”,但实际上并没有获得新的局部图像——推理可能语言上合理,却没有改变视觉输入。工具轨迹则要求模型真正调用放大或分割工具,并把返回图像纳入后续上下文。此时,中间步骤不再只是语言解释,而成为改变可见证据的动作。
普通 CoT 的质量主要取决于推理文本是否连贯、是否支持答案。工具轨迹还要额外检查动作是否可执行、工具参数是否正确、观察结果是否与动作对应。比如模型说“我将放大右上区域”,但 bbox 实际指向左下区域;或者工具返回了局部图,模型却继续引用原图中的其他区域。这些错误在普通 CoT 中不一定存在,但在工具轨迹中必须被识别。
这也解释了为什么工具调用数据不能只把轨迹写成一整段 assistant 消息。如果工具调用和观察返回都被压缩在同一段文本里,模型就不会经历环境反馈。多轮结构的意义在于让模型在时间上先行动,再接收结果,再继续判断——这样的结构更接近真实 Agent,也更便于后续接入工具环境。
当然,工具轨迹并不排斥简短的解释。模型在调用工具前可以说明为什么需要局部证据,在观察返回后可以说明观察如何影响选项比较。但这些解释应服务于动作和证据,不应喧宾夺主。对于医学图像场景,过长、过自信或过度诊断化的推理说明反而可能带来风险。更稳妥的写法是围绕问题选项和视觉证据进行有限说明。
因此,可以把工具轨迹理解为一种“带外部观察的过程监督”。它比普通答案监督更细,比纯文本 CoT 更可执行,也比完全黑箱的工具策略更可审计。MedImage-ToolVQA 的数据工程价值,正体现在这种过程监督的组织方式上。
案例B.8:SFT 数据与 RL 数据的不同关注点¶
工具轨迹可以同时服务 SFT 和 RL,但两者关注点不同。SFT 更像行为示范,目标是让模型学会格式、顺序和基本策略。RL 更像策略优化,目标是让模型在奖励反馈下选择更有效的行为。
在 SFT 阶段,数据最重要的是清晰和稳定。模型需要看到足够多格式正确的工具调用,理解 <tool_call> 内部应是可以解析的 JSON,理解工具返回后会出现新的图像观察,理解最终答案应写在固定位置。SFT 数据若格式混乱,后续 RL 环境就很难解析模型动作;若观察图插入位置不稳定,模型也难以学会“工具返回后继续推理”的节奏。
在医学图像场景中,SFT 多轮记录还应显式保存一个影像诊断相关 schema。这里的“诊断”不是要求模型给出临床结论,而是把训练题目中的医学影像任务、候选标签、证据区域和安全边界结构化。图41-8给出了一组来自 VQA-RAD 测试集的胸片样例:同一条记录不仅保存原始图像,还保存 bbox 坐标、框选可视化图和由工具返回的局部观察图。

图41-8:SFT schema 中的真实图像与 bbox 证据。bbox 是训练记录中的结构化字段,同时也应能被还原为可复查的可视化证据。
图像来源:VQA-RAD test split,Hugging Face 数据集 flaviagiammarino/vqa-rad,许可证为 CC0-1.0;本图为工具调用示例中的重采样派生图,用于说明 schema 中原图、bbox overlay 与局部 crop 的对应关系。
下面以这张胸部 X 线样例为基础,给出一条多轮 SFT 记录的写法。
代码清单41-9给出了 JSON 数据示例。
{
"sample_id": "medimage_toolvqa_xray_chest_000184",
"task_type": "medical_image_vqa_with_tool_use",
"image_context": {
"modality": "X-ray",
"body_part": "chest",
"view_or_series": "frontal chest radiograph",
"image_role": "original_image",
"figure_ref": "ch41_aux_sft_schema_real_chest_xray.png",
"source_dataset": "VQA-RAD",
"source_split": "test",
"source_url": "https://huggingface.co/datasets/flaviagiammarino/vqa-rad",
"license": "CC0-1.0",
"derivation": "resized tool-observation example",
"deidentification": "metadata_removed"
},
"diagnosis_schema": {
"clinical_scope": "training_and_evaluation_only",
"diagnostic_task": "chest_xray_focal_opacity_characterization",
"target_finding": "focal opacity candidate",
"anatomical_location": "right lung field",
"candidate_labels": [
{"choice": "A", "label": "focal opacity with relatively clear boundary"},
{"choice": "B", "label": "diffuse bilateral background opacity"},
{"choice": "C", "label": "linear or band-like opacity"},
{"choice": "D", "label": "imaging artifact without focal opacity"}
],
"gold_choice": "A",
"answer_boundary": "select_from_candidates_only",
"not_for_clinical_diagnosis": true
},
"visual_evidence": {
"roi_id": "roi_000184_01",
"bbox_2d": [593, 199, 839, 524],
"bbox_overlay_ref": "ch41_aux_sft_schema_bbox_overlay.png",
"crop_ref": "ch41_aux_sft_schema_zoom_roi.png",
"target_description": "right lung field focal opacity candidate",
"evidence_requirements": [
"verify focality",
"compare boundary clarity",
"exclude diffuse background opacity or artifact"
]
},
"messages": [
{
"role": "user",
"content": [
{"type": "image", "image_id": "image_000184_chest_xray"},
{
"type": "text",
"text": "该胸部 X 线图像中目标区域的影像表现更接近哪一项?\nA. 边界相对清楚的局灶性高密度影\nB. 弥漫性双肺背景性密度增高\nC. 线样或条带状影\nD. 无局灶性高密度影的成像伪影"
}
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "全图提示右侧肺野存在需要复查的局部区域,但边界和密度细节不足,需要先调用工具放大目标区域。"},
{
"type": "tool_call",
"name": "Zoom-in",
"arguments": {"target_image": 1, "bbox_2d": [593, 199, 839, 524]}
}
]
},
{
"role": "user",
"content": [
{"type": "image", "image_id": "image_000184_zoom_roi_01", "source_tool": "Zoom-in", "figure_ref": "ch41_aux_sft_schema_zoom_roi.png"},
{"type": "text", "text": "工具返回了目标区域的局部放大图,请基于新观察继续作答。"}
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "局部观察支持局灶性高密度影表现,边界相对清楚,不符合弥漫性背景改变或单纯线样影。"},
{"type": "answer", "choice": "A"}
]
}
],
"quality_control": {
"image_dependency": "required",
"tool_use_label": "necessary",
"schema_valid": true,
"review_status": "passed_with_nonclinical_scope"
}
}
代码清单41-9:JSON 数据示例。
这个 schema 的重点不是让模型学习“胸片异常应当如何诊断”,而是让训练记录能够同时回答五个工程问题:这是什么医学影像任务,候选标签边界在哪里,视觉证据来自哪一个 ROI,工具调用是否可执行,最终答案是否只落在题目允许的候选范围内。若缺少 diagnosis_schema,SFT 样本虽然仍可训练格式,却很难在后续质检、分层评测和人工复核中区分“医学标签错误”“区域证据错误”和“工具行为错误”。
在 RL 阶段,数据需要进一步暴露奖励和环境接口。模型输出工具调用后,环境可以判断工具名是否合法、参数是否符合 schema、bbox 是否越界、图像索引是否存在。模型输出答案后,规则奖励可以比较最终选项是否正确。更复杂的奖励还可以考虑工具调用是否必要、是否过度调用、是否使用了观察图等行为指标。
二者的关系可以理解为:SFT 先教模型“怎样做一个合法动作”,RL 再尝试优化“什么时候做这个动作更合适”。跳过 SFT,模型可能连工具格式都不稳定;只有 SFT 而没有后续策略反馈,模型可能学会表面轨迹,却不能在复杂问题中改进工具选择。
不过,RL 并不会自动解决数据问题。如果 SFT 样本中大量工具调用本来就不必要,RL 的初始策略会受影响;如果奖励只看最终答案,模型可能学会少用工具或乱用工具,只要偶尔答对即可。因此,医学图像工具调用数据中的奖励设计应尽量与数据质量控制相配合——答案正确是必要条件,但不是唯一目标。工具调用合法性、证据相关性和安全边界也应成为评测的一部分。
案例B.9:常见失败模式¶
工具调用数据看起来比普通 VQA 更丰富,但也更容易产生新的失败模式。理解这些失败模式,有助于读者把本章内容从“构建流程”提升到“数据治理”。
第一类失败是文本可答。题目看似来自医学图像,实际答案只依赖医学常识。例如题干问“肺部影像中常见结节位于哪个器官”,模型不看图也能回答。这类样本会削弱图像依赖性,甚至让模型学会忽略视觉输入。过滤文本可答题是医学 VQA 数据工程的基本门槛。
第二类失败是定位泄漏。题干直接说“标注框内”“mask 区域”“红色轮廓处”,使模型无需自主判断关注区域。这样的样本会让工具调用退化为表面格式而非取证策略。定位泄漏尤其容易出现在从标注数据自动生成问题时,因此需要文本规则和人工抽检共同控制。
第三类失败是 ROI 不相关。问题、答案和目标区域之间没有强关系,可能因区域标注错误,也可能因问题生成时偏离了目标描述。ROI 不相关的样本比格式错误更隐蔽,因为它们在表面上可能结构完整、答案看似合理。解决这类问题需要同时检查图像、目标区域、描述和答案。
第四类失败是工具调用无效。模型或合成器生成的工具参数可能不合法,例如 bbox 越界、图像索引不存在、工具名拼写不一致、参数字段缺失。这类错误会直接影响训练和环境交互。对于工具调用数据,schema 校验不是附加步骤,而是必要步骤。
第五类失败是观察未被消费。模型调用了工具,工具也返回了观察图,但后续回答没有体现对观察结果的使用。这种轨迹在格式上完整,行为上却不完整——它会训练模型把工具调用当作固定模板,而非证据获取动作。
第六类失败是过度调用。模型对本来可由全图直接回答的问题也调用工具,或者连续调用多个工具但没有新增信息。过度调用会增加推理成本,也可能在实际系统中带来延迟和错误累积。因此,训练集中必须保留一定比例的直接视觉推理样本,并在评测中区分“必要工具调用”和“形式化工具调用”。
表41-4列出了相关字段与出版复核口径。
表41-4:风险、控制措施与复核口径。
| 失败模式 | 表现 | 风险 | 治理方式 |
|---|---|---|---|
| 文本可答 | 不看图也能答题 | 模型忽略视觉输入 | no-image 校验、题目重写或过滤 |
| 定位泄漏 | 题干暴露 bbox/mask | 模型不学习主动定位 | 文本规则、人工抽检、生成约束 |
| ROI 不相关 | 区域与问题目标不一致 | 工具轨迹失去证据意义 | 图像、区域、描述、答案联合校验 |
| 工具调用无效 | JSON 错误、bbox 越界、索引不存在 | 环境无法执行或返回错误观察 | schema 校验、参数边界检查 |
| 观察未消费 | 调用工具后仍凭原题作答 | 工具行为退化为模板 | 轨迹审计、回炉合成 |
| 过度调用 | 简单问题也调用工具 | 推理成本上升、策略僵化 | 保留直接样本、加入必要性评估 |
这些失败模式说明,工具调用数据的质量并不只取决于答案是否正确。一个工具轨迹样本至少要同时通过三类检查:题目是否需要视觉证据,工具动作是否合理有效,最终答案是否正确消费了观察结果。缺少任何一类检查,数据都可能变成格式复杂但监督价值有限的样本。
案例B.10:质量控制与人工复核¶
医学图像工具调用数据的质量控制应当分层进行,而非等到最终数据封装后再一次性检查。更合理的方式,是在问题生成、区域校验、工具观察生成、轨迹合成和训练封装各阶段分别设置门禁。
图41-9展示了相应的流程或结构。

图41-9:质量控制与人工复核门禁。医学图像工具调用数据需要同时检查答案、证据和行为,自动校验与人工复核应形成互补。
结构校验是第一层。问题、选项、答案、图像引用、区域字段和工具参数都必须完整且可解析。对于工具调用样本,工具名应来自白名单,参数字段应符合工具 schema,bbox 坐标应在图像范围内。结构校验相对机械,但能排除大量后续无法训练或无法执行的样本。
图像依赖校验是第二层。数据构建者需要判断问题是否真的需要图像,可以通过无图回答检查、教师模型判定或人工抽检来识别文本可答样本。医学领域知识很强,许多问题稍不注意就会退化成常识题。图像依赖校验的目的,是确保模型必须观察具体图像才能做出合理判断。
区域一致性校验是第三层。问题与答案必须和目标区域相关,工具观察也应来自同一证据链。区域一致性不是只看 bbox 是否存在,而是看题干所问、选项差异、目标描述和局部图像是否共同指向同一视觉对象。
工具有效性校验是第四层。即使问题和区域都合理,工具调用仍可能失败。系统需要检查工具参数是否可执行、观察图是否生成、观察图与原区域是否对应、后续轨迹是否正确引用观察图。对工具调用数据来说,这一步相当于把“行为正确性”纳入质量控制。
人工复核是第五层。不是所有样本都需要专家逐条审核,但高风险或低置信样本应进入人工复核队列。复核队列可由四类触发条件建立:一是自动校验分数低或多项规则冲突的样本;二是 bbox、mask 与题目目标存在弱一致性的样本;三是涉及疑似恶性病变、急危重症、儿童影像、罕见病表现等高风险医学主题的样本;四是工具调用次数异常、观察图缺失或观察未被消费的轨迹样本。这样做的目的不是把所有判断都交给人工,而是把自动系统最不稳定的部分集中暴露出来。
复核员角色也需要区分。医学内容复核员应关注题目、选项和答案是否越界或误导;视觉证据复核员应关注 ROI、mask、bbox 和观察图是否对应;工具轨迹复核员应关注工具名、参数 schema、多轮顺序和观察消费是否稳定。对于高风险医学样本,至少应有具备相应医学背景的复核者参与;对于普通格式和流程问题,可由数据工程或训练工程角色先行筛查。
复核结果不宜只写成“通过/不通过”。更可维护的分类是四类:通过 表示样本可进入训练集;修改 表示题干、选项、区域说明或轨迹需要回炉重写;降级 表示样本不再作为工具增强轨迹使用,但可保留为直接 VQA 或教学示例;废弃 表示证据链断裂、医学风险过高或无法修复。每一类结果都应回写到数据版本记录中,保留复核原因、处理动作和后续归属。这样,人工复核不只是一次性把关,还会反过来改进题目生成、工具参数约束和质量过滤规则。
质量控制还需要记录通过率和失败原因。只知道最终剩下多少样本是不够的,团队还应记录有多少样本因文本可答被过滤、有多少因定位泄漏被重写、有多少因工具参数无效被丢弃、有多少进入人工复核。这样的统计能帮助后续训练结果解释,也能在数据集版本更新时快速定位问题。
案例B.10.1 评测协议:不只检查答案是否正确¶
医学图像工具调用数据的评测,不能只保留普通 VQA 的准确率指标。准确率仍然重要,但它只覆盖最终答案,不覆盖工具行为。一个模型可能答对,却把工具调用到无关区域;也可能调用了合理工具,却因为选项混淆而答错。这两种情况对数据工程和模型改进的意义完全不同。如果评测只看最终选项,许多过程性问题会被隐藏。
更合理的评测应至少分成四层。第一层是答案层,检查模型是否选对答案。这一层可以使用规则匹配,因为多选题答案通常以 A、B、C、D 等形式呈现。第二层是格式层,检查模型是否输出合法工具调用,包括工具名、JSON 结构、参数类型和必填字段。第三层是行为层,检查工具调用是否必要、是否指向合理区域、是否出现过度调用。第四层是证据层,检查模型在得到观察图后是否真正使用了新证据,而不是忽略观察结果直接输出答案。
答案层指标最容易计算,也最容易误导。医学多选题中,如果选项分布不均衡,模型可能通过偏向高频选项获得表面不错的准确率。因此,除总体准确率外,还应统计分选项准确率、不同工具类型样本的准确率、直接样本与工具增强样本的准确率,这样才能发现模型是否只在某些类型上表现稳定。
格式层指标主要服务工程稳定性。工具调用一旦格式错误,环境就无法执行。常见问题包括 JSON 不可解析、工具名大小写不一致、bbox 不是四个数、图像索引不是整数、字段名与 schema 不匹配。格式层指标不一定反映医学能力,但它决定系统能否运行。对于 Tool-Use 数据来说,格式稳定性是进一步评测的前提。
行为层指标更接近本章主题。它关心模型是否在适当时机调用工具。若一个样本设计上可以直接根据全图回答,模型却频繁调用工具,说明策略可能过度保守;若一个样本明显需要局部取证,模型却直接回答,说明模型可能没有学会识别证据不足。行为层评测可以通过样本标签、人工抽检或规则启发式完成,不要求一次性做到完全自动化。
证据层指标最难,但也最有价值。它需要判断模型在观察图返回后,是否根据新视觉证据更新了判断。简单做法是检查回答文本中是否引用了局部观察;更严格的做法是比较有无观察图时的模型输出差异;再进一步,可以让评审模型或人工标注员判断模型解释是否与观察图一致。证据层评测不宜完全依赖语言表面,因为模型可能生成看似合理的解释,却没有真正对应图像。
除了自动指标,医学图像工具调用数据还需要抽样审计。抽样审计不应只抽最终预测错误的样本,也应抽预测正确但工具行为异常的样本。因为过程错误可能暂时没有影响答案,却会在更复杂或更高风险场景中放大。一个较稳妥的审计样本池可以包括:工具调用次数异常的样本、bbox 接近边界的样本、答案置信度低的样本、自动评测与人工判断冲突的样本、以及涉及高风险医学主题的样本。
因此,MedImage-ToolVQA 的评测协议可以概括为“答案正确只是第一层,行为合理才是完整目标”。这与本书前面关于 Agent 数据的讨论是一致的:当模型被训练为会行动的系统时,评测就必须覆盖行动本身。否则,数据集虽然引入了工具,却仍然只在评测单步问答。
案例B.10.2 数据卡与版本说明:把数据集写成可维护资产¶
专项数据集如果只停留在样本文件层面,很难被后续团队稳定复用。尤其是医学图像工具调用数据,它同时包含图像、区域证据、工具轨迹、答案和安全边界,更需要配套的数据卡与版本说明。数据卡不是附加说明,而是数据集可维护性的组成部分 (Gebru et al. 2021)。
一份面向 MedImage-ToolVQA 的数据卡,至少应说明六类信息。第一是任务定义:数据用于医学图像多选 VQA 与工具调用行为训练,不用于直接临床诊断。第二是数据组成:图像模态、区域来源、样本规模、答案分布、多图观察分布、直接样本与工具增强样本比例。第三是构建流程:区域整理、问题生成、质量校验、观察图生成、轨迹合成、训练封装。第四是工具说明:每个工具的输入输出、适用场景和限制。第五是质量控制:过滤规则、校验维度、人工复核策略和已知失败模式。第六是合规边界:脱敏方式、授权范围、禁止用途和风险提示。
版本说明则回答另一个问题:当数据集被更新时,使用者如何理解变化。对普通文本数据来说,版本变化可能主要是增删样本或修正标注;对工具调用数据来说,变化还可能来自工具 schema 调整、bbox 规范调整、观察图生成方式变化、轨迹模板变化、奖励字段变化。任何一类变化都可能影响训练结果,因此需要明确记录。
例如,若某个版本改变了 crop padding 策略,局部观察图的视觉内容就会变化;若某个版本调整了工具参数命名,工具调用格式就会变化;若某个版本重新过滤了文本可答样本,数据难度和图像依赖性也会变化。没有版本说明,模型训练结果的差异很难归因。
数据卡还应区分“已知能力”和“未覆盖能力”。MedImage-ToolVQA 可以训练模型在给定工具空间内进行局部取证,但这并不意味着模型已具备完整临床推理能力,也不意味着所有医学模态都覆盖充分。若数据主要来自某些图像类型或区域来源,就应如实说明覆盖范围。中立的数据说明比夸大的能力描述更有价值,因为它能帮助使用者判断适用边界。
对于教学和研究使用,数据卡还可以提供建议实验,比如比较直接 VQA 样本与工具增强样本的训练差异、比较有无观察图时模型答案的变化、比较只做 SFT 与加入 RL 后工具调用率的变化。这些实验不需要写成结果承诺,而可以作为读者理解数据机制的入口。
从长期维护角度看,MedImage-ToolVQA 这类数据更像“训练资产”而非“一次性数据文件”。它的价值来自样本、工具、评测和说明之间的组合。只有将数据卡、版本记录、质量统计和风险边界一起维护,后续团队才可能在不重新摸索全部细节的情况下接手使用。
案例B.11:医学隐私与合规边界¶
医学图像数据涉及个人隐私和敏感健康信息。即使图像本身不显示姓名,metadata、影像角标、检查编号、时间戳、机构名称和报告片段也可能泄露身份。进入训练或公开说明前,数据应经过脱敏处理,包括删除直接标识、处理图像中嵌入的文字、控制路径和文件名中的敏感信息,以及记录数据来源和使用授权。
在工具调用数据中,隐私风险还会因多图记录而增加。原图、局部 crop、mask overlay 和分割图都可能包含可识别信息。局部 crop 有时会放大原图角落的文字或标记;overlay 图可能保留原始图像背景;工具观察图也可能被误认为新的独立样本。因此,脱敏不能只对原图做一次,而应覆盖所有派生图像。
合规边界还包括用途说明。MedImage-ToolVQA 的样本用于研究、训练和评测医学图像工具调用行为,不应被描述为临床诊断系统。书稿、数据卡和模型卡都应明确说明:模型输出不能替代专业医疗判断,涉及真实应用时必须由具备资质的人员复核 (Mitchell et al. 2019)。这一点不仅是法律或伦理要求,也是避免误读数据能力的必要说明。
工具边界同样重要。Zoom-in 仅是裁剪图像,BiomedParse 和 SAM2 仅是分割或定位工具,它们不应被写成会自动判断疾病性质的工具。训练数据中的语言也要避免让工具调用看起来像“确认诊断”。更合适的表达是“获取局部视觉证据”“观察区域边界”“辅助比较选项”。
此外,还需要警惕模型在工具轨迹中生成过度自信的表述。医学图像问题常常存在不确定性,训练样本不应把有限视觉证据包装成绝对结论。对于多选题,可以要求模型在答案范围内作答,但正文解释和数据说明应避免将选项答案扩展为临床建议。
案例B.12:与多模态 Agent 数据工程的关系¶
MedImage-ToolVQA 的意义不只在医学图像领域。它提供了一个更一般的数据工程范式:当模型需要调用工具获取新证据时,训练数据应当记录“行动—观察—更新”的闭环。这个闭环同样适用于多模态 RAG、文档理解、表格问答、图表推理和机器人感知任务。
与传统多模态指令数据相比,工具调用数据更强调环境反馈。传统样本通常把所有输入一次性交给模型,让模型生成答案。工具调用样本则允许模型在中间步骤改变可见信息:调用放大工具后,它看到局部图;调用分割工具后,它看到 mask;调用检索工具后,它看到外部证据。数据工程因此要从“静态样本设计”转向“轨迹样本设计”。
轨迹样本设计有几个基本原则。第一,动作空间要有限且清晰——工具名、参数和返回结果都应可验证。第二,观察结果要真实进入后续上下文,不能只作为注释存在。第三,奖励和质量控制要覆盖行为过程,而不只是最终答案。第四,高风险领域必须加入安全边界和人工复核。
这些原则也解释了为什么 MedImage-ToolVQA 适合放在专项数据集与数据工程实践这一篇中讨论。它不是一个单纯的医学数据集介绍,而是一个将多模态数据、工具使用、Agent 轨迹和合规治理连接起来的案例。它向前连接图文对齐、视觉 grounding 和多轮 Tool-Use,向后支撑 VLM 数据配方与 Agent Tool-Use 项目。
对于读者而言,本章真正需要带走的不是某个具体工具名,而是一种思考方式:当模型面对的问题需要主动获取证据时,数据集就不能只记录问题和答案。它还需要记录证据从哪里来、动作如何产生、观察如何返回、答案如何被更新,以及整个过程如何被校验。
案例B.12.1 从本章迁移到其他工具增强数据¶
虽然本章讨论的是医学图像,但这里的方法并不局限于医学场景。只要任务需要模型主动获取额外证据,都可以借用相似的数据组织思路。文档问答中的局部页面放大、图表问答中的子图定位、遥感图像中的区域检索、工业质检中的缺陷放大,都存在类似问题:模型不能只回答问题,还要知道什么时候需要进一步观察。
迁移时需要保留三件事。第一是证据对象。医学图像里的证据对象是 ROI、mask 和 bbox;文档场景里可能是页面区域、表格单元格和 OCR 坐标;图表场景里可能是坐标轴、图例和某个曲线段。不同场景的证据对象不同,但都需要被结构化表示。
第二是工具边界。医学图像工具是放大、语义分割和几何分割;文档工具可能是 OCR、表格解析和页面检索;图表工具可能是数值读取、子图裁剪和坐标映射。无论工具是什么,都应明确输入、输出、失败条件和禁止用途。工具越模糊,训练数据越容易把动作写成泛泛的解释。
第三是观察消费。工具返回结果必须改变后续可见信息,并被模型用于下一步判断。如果工具调用只是轨迹中的形式片段,而观察结果没有进入上下文,那么它对训练行为策略的帮助有限。读者在迁移本章方法时,最应检查的不是工具名是否足够丰富,而是“工具返回的新证据是否真正改变了模型的可见世界”。
因此,MedImage-ToolVQA 可以被视为一种模板:先定义证据对象,再定义工具动作,然后把动作返回的观察显式写进多轮样本。这个模板的具体字段会随场景变化,但核心逻辑稳定。它帮助数据工程团队从静态样本设计转向轨迹样本设计,也帮助评测从单一答案正确率扩展到行动合理性。
案例B.12.2 与本书其他章节的关系¶
如果把本章放回全书结构中,它连接了几条主线。第三篇讨论图文对、多模态清洗和跨模态对齐,提供了医学图像进入模型前所需的视觉数据基础。没有图像质量控制、分辨率处理和局部 grounding,后续工具调用轨迹就缺少可靠输入。
第六篇讨论 Tool-Use 与 Agent 数据,提供了行动空间、工具 schema 和多轮轨迹的基本概念。本章将这些概念放到医学图像中,说明工具调用不只是文本 Agent 的能力,也可以成为视觉 Agent 的数据对象。它把“调用搜索工具”一类语言任务,扩展到“调用视觉工具重新观察图像”的多模态任务。沿着这条线索继续往后看,第十篇进一步讨论 Data Engineering Agent 如何在真实数据工程流程中受到工具边界、安全权限和人机协同的约束。本章虽然聚焦医学图像数据集,但工具白名单、参数 schema、观察图审计和人工复核门禁所处理的正是同一类问题:当模型或数据构建器被允许采取行动时,数据工程必须同时规定它能做什么、做完之后留下什么证据,以及哪些环节需要人工接住。
第十一篇讨论隐私合规与数据安全,为本章提供了风险边界。医学图像数据不能只按技术可行性处理,还必须考虑脱敏、授权、审计和误用风险。工具调用样本引入了更多派生图像,也就引入了更多需要治理的对象。
第十三篇和第十四篇则更偏训练配方和项目实践。本章提供的医学图像工具轨迹,可作为 VLM 指令数据、Agent Tool-Use 工厂和多模态 RL 数据的前置案例。读者如果后续要设计自己的多模态工具调用项目,可以把本章当作一个中间桥梁:它既不是纯概念介绍,也不是某个项目的复现说明,而是将数据结构、工具行为和质量边界组织成可迁移的方法。
这种跨章节关系也提醒我们,专项数据集的意义不只是介绍一个数据对象。更重要的是,它帮助读者把前面学过的方法重新组合起来。医学图像只是载体;真正的主题是:当模型需要在视觉环境中主动取证时,数据工程应该怎样记录证据、行动、反馈和风险。
案例B:小结¶
MedImage-ToolVQA 展示了医学图像 VQA 数据工程的一种扩展方向:从单步答案监督,走向包含局部视觉证据和工具调用行为的多轮监督。它以区域级医学图像信息为基础,将 ROI、mask、bbox、目标描述、工具观察和多选答案组织在同一条证据链中,使模型不仅学习“答什么”,也学习“如何获取和使用视觉证据”。
这种数据范式的优势在于可解释性和可审计性更强。工具调用参数、观察图像和最终答案之间存在可检查关系,训练失败时也更容易区分是问题生成错误、区域 grounding 错误、工具调用错误,还是答案推理错误。与此同时,它也带来更高的数据工程成本:每个阶段都需要校验,每个工具都需要边界,每个派生图像都需要追踪和脱敏。对于医学图像这样的高风险场景,数据集不只是训练前的样本集合,也承担了一部分行为规范——它告诉模型何时直接观察、何时调用工具、调用后如何更新判断,以及哪些回答必须受到质量控制、隐私保护和人工复核的约束。
本章小结¶
本章将多图表信息图推理与医学图像工具调用放在视觉推理数据工程的同一脉络中展开。多图表信息图任务强调跨图表证据聚合、多步计算和问题结构控制;医学图像工具调用任务强调局部证据、工具行为、派生观察和高风险场景下的审计边界。二者都表明,视觉推理数据集的关键不只是“有图有问答”,而是能否把证据来源、推理步骤、工具动作和质量控制显式组织起来。
因此,本章提供的重点方法是将视觉推理任务拆解为可标注、可训练、可评测的数据接口:图表场景中需要约束问题类型、证据链和计算路径,医学场景中需要约束 ROI、工具参数、观察结果和合规审查。这样的结构化设计可以帮助模型从被动识别走向主动取证,也为后续 VLM 指令数据、Agent 数据和多模态 RL 数据提供可复用的工程模板。
参考文献¶
Masry A, Long D X, Tan J Q, Joty S, Hoque E (2022) ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. ACL 2022. https://doi.org/10.18653/v1/2022.findings-acl.177.
Methani N, Ganguly P, Khapra M M, Kumar P (2020) PlotQA: Reasoning over Scientific Plots. WACV 2020. https://doi.org/10.1109/wacv45572.2020.9093523.
Kahou S E, Michalski V, Atkinson A, Kádár Á, Trischler A, Bengio Y (2017) FigureQA: An Annotated Figure Dataset for Visual Reasoning. arXiv:1710.07300.
Kafle K, Price B, Cohen S, Kanan C (2018) DVQA: Understanding Data Visualizations via Question Answering. CVPR 2018. https://doi.org/10.1109/cvpr.2018.00592.
Mathew M, Karatzas D, Jawahar C V (2021) DocVQA: A Dataset for VQA on Document Images. WACV 2021. https://doi.org/10.1109/wacv48630.2021.00225.
Masry A, Islam M S, Ahmed M, Bajaj A, Kabir F, Kartha A, et al. (2025) Chartqapro: A more diverse and challenging benchmark for chart question answering. In Findings of the Association for Computational Linguistics: ACL 2025 (pp. 19123-19151). https://doi.org/10.18653/v1/2025.findings-acl.978.
Xie T, Lin M, Liu M, Ye Y, Chen C, Liu S (2026) Infochartqa: A benchmark for multimodal question answering on infographic charts. Advances in Neural Information Processing Systems, 38.
Foroutan N, Romanou A, Ansaripour M, Eisenschlos J M, Aberer K, Lebret R (2025) Wikimixqa: a multimodal benchmark for question answering over tables and charts. In Findings of the Association for Computational Linguistics: ACL 2025 (pp. 24941-24958).
Zhu Z, Jia M, Zhang Z, Li L, Jiang M (2025) MultiChartQA: Benchmarking vision-language models on multi-chart problems. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (pp. 11341-11359).
Antol S, Agrawal A, Lu J, Mitchell M, Batra D, Zitnick C L, Parikh D (2015) VQA: Visual Question Answering. Proceedings of the IEEE International Conference on Computer Vision, 2425–2433. https://doi.org/10.1109/ICCV.2015.279.
Lau J J, Gayen S, Ben Abacha A, Demner-Fushman D (2018) A dataset of clinically generated visual questions and answers about radiology images. Scientific Data, 5, 180251. https://doi.org/10.1038/sdata.2018.251.
He X, Zhang Y, Mou L, Xing E, Xie P (2020) PathVQA: 30000+ Questions for Medical Visual Question Answering. arXiv:2003.10286.
Liu B, Zhan L-M, Xu L, Ma L, Yang Y, Wu X-M (2021) SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering. IEEE 18th International Symposium on Biomedical Imaging. https://doi.org/10.1109/ISBI48211.2021.9434010.
Yao S, Zhao J, Yu D, et al. (2023) ReAct: Synergizing Reasoning and Acting in Language Models. International Conference on Learning Representations. arXiv:2210.03629.
Schick T, Dwivedi-Yu J, Dessì R, et al. (2023) Toolformer: Language Models Can Teach Themselves to Use Tools. Advances in Neural Information Processing Systems, 36.
Kirillov A, Mintun E, Ravi N, et al. (2023) Segment Anything. Proceedings of the IEEE/CVF International Conference on Computer Vision, 4015–4026.
Ravi N, Gabeur V, Hu Y-T, Hu R, Ryali C, Ma T, et al. (2025) SAM 2: Segment Anything in Images and Videos. International Conference on Learning Representations.
Ma J, He Y, Li F, et al. (2024) Segment anything in medical images. Nature Communications, 15, 654. https://doi.org/10.1038/s41467-024-44824-z.
Zhao T, Gu Y, Yang J, et al. (2025) A foundation model for joint segmentation, detection and recognition of biomedical objects across nine modalities. Nature Methods, 22, 166–176. https://doi.org/10.1038/s41592-024-02499-w.
Gebru T, Morgenstern J, Vecchione B, Vaughan J W, Wallach H, Daumé III H, Crawford K (2021) Datasheets for Datasets. Communications of the ACM, 64(12), 86–92. https://doi.org/10.1145/3458723.
Mitchell M, Wu S, Zaldivar A, et al. (2019) Model Cards for Model Reporting. Proceedings of the Conference on Fairness, Accountability, and Transparency, 220–229. https://doi.org/10.1145/3287560.3287596.