视频创作(视频制作)¶
“视频创作”也可以理解为“视频制作”。它用于生成一段可下载的数字人口播视频。它和“实时对话”不同:用户先选择数字人形象、音频来源和生成模型,服务端完成离线生成后,把结果保存到导出视频资产库。当前 WebUI 顶部标签显示为“视频创作”。
适合什么场景¶
视频创作适合:
- 商品讲解、课程口播、新闻播报等需要导出成文件的场景。
- 先上传一段录好的音频,再让数字人生成对应口播视频。
- 先输入口播文本,由 TTS 生成音频,再生成数字人视频。
- 先复刻音色,再用复刻音色生成一段口播视频。
它不适合实时问答,也不会进入 LLM / STT / WebRTC 实时会话链路。
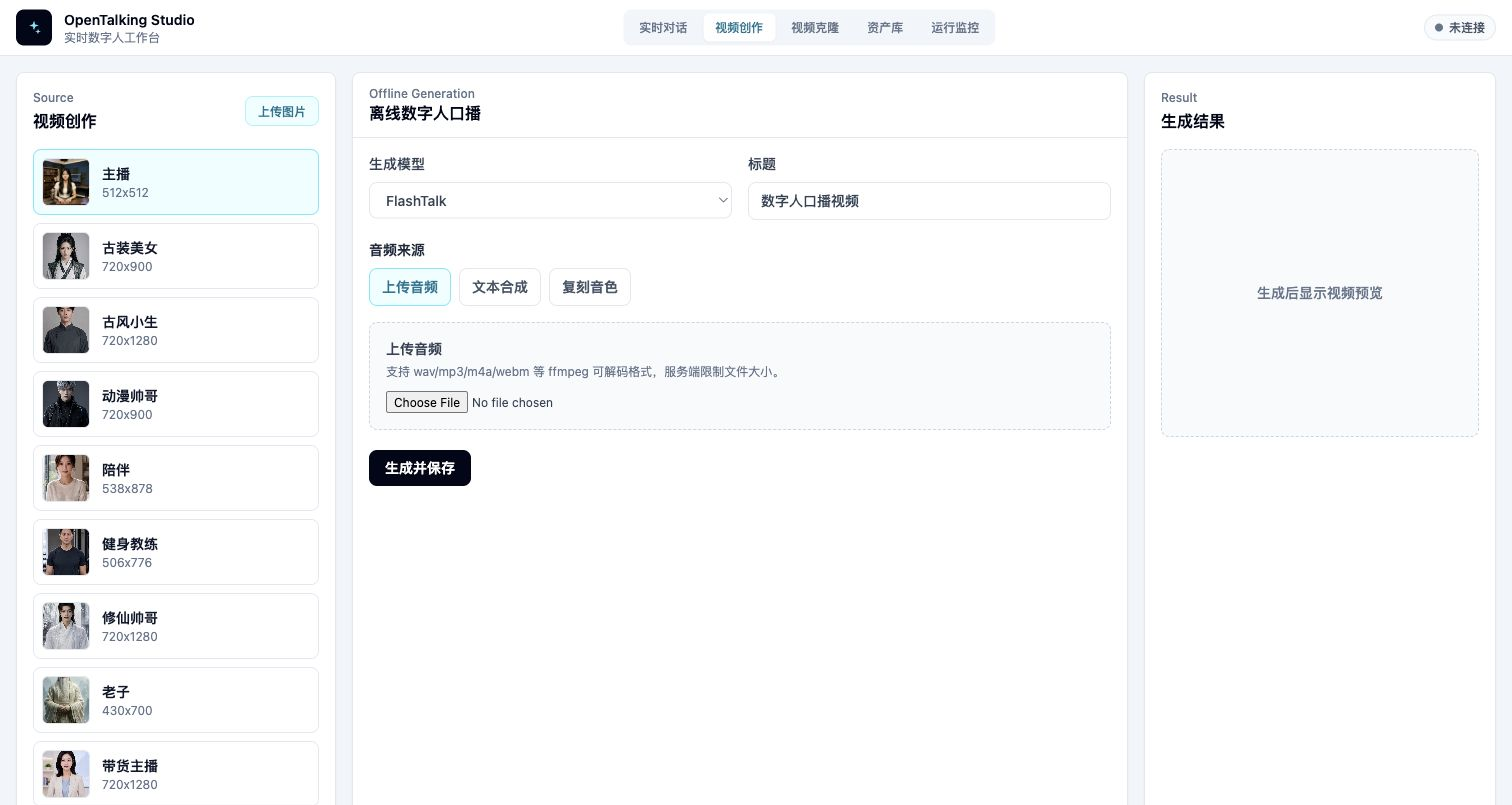
视频创作页面:左侧选择数字人形象,中间配置离线生成,右侧预览生成结果。
前置条件¶
你需要先启动 OpenTalking,并确保要使用的 talking-head 模型可用:
quicktalk:适合轻量实时或准实时口播生成。wav2lip:适合对已有音频做口型同步。fasterliveportrait:适合需要贴回原图、动作幅度参数和更细粒度表情控制的视频生成。
第一次验证可以先用 Mock 模式打开 WebUI 熟悉界面,但真正生成视频需要对应模型后端可用。
页面组成¶
Source¶
左侧 Source 区用于选择视频中的数字人形象。你可以直接选择已有 Avatar,也可以点击“上传图片”创建新的图片形象。
上传图片时,建议使用清晰正脸或半身图。上传后会加入当前形象库,并自动成为可选 source。
Offline Generation¶
中间区域负责生成配置:
- “生成模型”:选择当前后端已连接的 talking-head 模型,例如
quicktalk、wav2lip或fasterliveportrait。 - “标题”:生成后写入导出视频资产库的名称。
- “音频来源”:决定视频口播音频来自哪里。
音频来源有三种:
- “上传音频”:上传已有
wav、mp3、m4a、webm等音频文件。 - “文本合成”:输入口播文本,使用当前 TTS Provider 和 voice 合成音频。
- “复刻音色”:先录制或上传样本音频创建新 voice,再用该 voice 合成口播。
文本合成和复刻音色都建议先点击“试听口播”,确认声音、语速和文本没有问题后再生成视频。
Result¶
右侧 Result 区在生成完成后展示视频预览、下载按钮和资产库入口。生成结果会保存到导出视频资产库,后续可以在“资产库”工作流中查看、下载或删除。
操作步骤¶
- 打开 WebUI,顶部切到“视频创作”。
- 在左侧选择一个 Avatar;如果要使用新形象,点击“上传图片”。
- 在中间选择当前后端可用的生成模型。
- 填写标题。
- 选择音频来源。
- 如果使用文本合成或复刻音色,先试听口播。
- 点击“生成并保存”。
- 在右侧预览结果,或点击“去资产库查看”。
音频来源怎么选¶
上传音频¶
适合已有录音、已经剪辑好的旁白、或外部 TTS 生成的音频。上传前建议控制音频长度,先用短音频验证模型链路。
文本合成¶
适合快速生成口播。你只需要输入文案,选择 TTS Provider 和音色。当前试听和生成都使用同一套 TTS 配置。
复刻音色¶
适合需要固定品牌音色或主播音色的场景。复刻成功后,WebUI 会把新 voice 应用到当前视频创作流程。
常见问题¶
生成模型不可选¶
说明当前后端没有暴露对应模型。检查启动命令中的 --backend、--model,确认 OmniRT / local runtime 是否已启动,也可以先访问 /models 查看 connected 状态。
上传音频后生成失败¶
检查音频格式、文件大小和服务端日志。若不确定是不是音频问题,先换一段 3-5 秒的 wav 文件验证。
文本合成试听失败¶
检查 TTS Provider Key、voice 标识和网络访问。云端 TTS 失败通常不会进入 talking-head 生成阶段。
生成后右侧没有预览¶
先看页面错误提示,再检查 API 日志。生成成功但无法播放时,确认浏览器支持返回视频的编码格式。