第40章:视觉文档与表格数据工程:结构化抽取、稀疏表格与 Schema 约束¶
摘要¶
本章讨论视觉文档如何从图像、版式、表格和业务字段中形成可训练、可评测、可审计的数据对象,有票据文档理解与稀疏表格结构识别两个专项案例。StructBill-CN 强调高风险票据字段、层级 JSON 和算术一致性,SparseTable-Bench 强调表格拓扑、空单元格和结构鲁棒性;两者共同说明,视觉文档数据工程的核心不是单纯 OCR,而是把页面结构、业务语义和评测协议绑定成稳定的样本 schema。
关键词¶
视觉文档;表格结构识别;票据理解;样本 schema;结构鲁棒性;数据质量评测
案例A:StructBill-CN:票据字段、业务 schema 与逻辑一致性¶
案例A:学习目标¶
通过本章学习,读者应能够:
- 理解中文票据与医疗费用文档为什么是一个"高风险 × 高密度 × 弱视觉线索"的数据工程挑战,而不仅仅是 OCR 问题。
- 掌握 StructBill-CN 的任务定义——Schema-based End-to-End Unified Extraction——及其与传统表格结构识别的本质差异。
- 理解样本结构中三类监督信号(全局 Key-Value、嵌套 line-item Table、逻辑约束)的设计原理,以及"语义归属优先于物理位置"的标注哲学。
- 掌握一条带逻辑一致性门禁的数据构建流水线,理解采集、去噪、schema 设计、层级 JSON 标注、结构合规校验、逻辑一致性校验和版本切分各阶段的工程要点。
- 掌握多维评测协议——字段级准确率(KV-F1 / Table-F1)、字符级精度(ANLS)、结构一致性(TEDS)、算术一致性(ACR)和 Schema 约束违反率(SCVR)——及其串成闭环的方式。
- 能够对评测结果做错误归因,并把高频错误映射到可操作的数据工程修复动作上。
- 理解高风险文档场景下的隐私、合规与审计注意事项,以及"公开基准 / 私有生产"分层的基本原则。
- 明确本章如何与前后章节形成串联,支撑后续 VLM 数据配方、多模态 RAG 和隐私流水线项目实战。
案例A:场景引入¶
某省级医保中心的信息化团队历时两个月训练了一个基于 Qwen2.5-VL(Bai et al., 2025) 的端到端票据抽取系统。离线评测显示,系统在测试集上的字符识别准确率(ANLS)超过 92%,字段级 F1 也接近 90%。团队对此充满信心,准备接入结算对账流水线。
然而,在上线前的业务验收中,财务核算组随机抽取了 200 张无线表费用清单做交叉校验,结果令人意外:近 15% 的记录无法通过"明细金额求和 = 总额"的对账规则,其中多数并非字符识别错误——数字本身都"读对了"——而是行列错位导致金额归属到了错误的行。更严重的是,大约 5% 的清单中出现了"凭空多出的表行":模型把出院记录中的自由文本段落"编造"成了表格行项目,生成了看似合法实则不存在的费用明细。
验收组提出了三个问题。第一,现有测试集里有没有逐行检查过"单价 × 数量 = 金额"?如果标注本身不做算术一致性校验,模型从何学会守住这条规则?第二,评测指标只看了 ANLS 和 F1,有没有专门度量"多少条记录可以直接入库、不需要人工复查"?第三,如果一张图像质量太差导致本身就不可读,算模型的错还是数据的错?
这三个问题直击核心:一份只标注了"字段在哪里"的数据集,无法暴露算术不一致、结构捏造和行列错位等级联失效;一个只看字符级指标的评测,无法回答"这条记录到底能不能入库"。团队不得不回退到数据工程的起点——重新审视标注规范、校验流水线和评测协议。
StructBill-CN 要解决的,正是这类问题背后的数据工程挑战。
案例A.1:问题场景:票据与医疗费用文档为什么难做结构化抽取¶
医疗票据、费用结算单、药房发票这类文档,处于一个典型的「高风险 × 高密度 × 弱视觉线索」的交叉地带。它们既不是可以随意改写的自由文本,也不是结构规整、网格清晰的电子表格,而是要被直接灌入下游业务系统(财务审计、保险理赔、ERP)的结构化记录。这就决定了任务的真正目标不是「把图像里的字读出来」,而是「把图像直接转写成一个可查询的数据库对象」。
从数据工程视角看,这类文档的难点可以归纳为三层,它们恰好对应了后文数据集要刻意暴露与覆盖的三类挑战。
第一层是全局键值(Key-Value)抽取本身就不可靠。当模型去检索「总金额」「发票号」这类离散字段时,常见两种失败:一是数值幻觉,把图像里没有的数字凭空补全或抄错(Liu et al., 2024);二是空间定位漂移,抓到了相邻列、相邻行的值。对自由文本任务来说,这种偏差可能无关紧要;但对财务记录,一个数字错位就是一条不可用的低质量数据。
第二层是传统表格处理范式在这里直接失效。学术界长期聚焦于表格结构识别,其核心假设是「有可见的网格线,可以预测物理坐标」。然而真实票据中充斥着无线表:没有竖直分隔线,密集的数字列在视觉上彼此粘连,基于视觉分割的方法极易发生行列错位。更关键的是,TSR 输出的是「物理结构」,而业务系统要的是「语义 schema」,两者之间还隔着一层无法自动跨越的鸿沟。
第三层,也是最容易被忽视的一层,是逻辑一致性。票据里隐含着确定性的算术公理:单行的「单价 × 数量 = 金额」,整单的「明细金额求和 = 总额」。这些约束在 token 级别上几乎不可微——一个错误的金额 A' 与正确金额 A 可能只差一个字符,交叉熵损失看不出差别,但在业务逻辑上它是彻底错误的。也就是说,一个语法上完全合法、字段也基本对的 JSON,仍然可能在算术上自相矛盾。
把这三层叠加起来,就能理解为什么这是一个数据工程问题,而不只是模型问题:要让模型学会「看懂语义布局 + 守住算术约束」,前提是先有一份把图像、schema、层级 JSON、表格字段和逻辑约束都显式编码进去的数据资产,并且这份资产是可训练、可评测、可复查的。StructBill-CN 要解决的,正是这个数据资产的构建问题。
40.1.1 管线范式与端到端范式:为什么"读对字"不等于"抽对数据"¶
要理解 StructBill-CN 的取舍,需要先看清文档抽取的两条技术路线。管线范式把任务拆成文本检测、OCR 识别、信息抽取三段独立处理,模块清晰、可解释,长期主导工业落地;但其高风险弱点是误差累积——检测或识别阶段的错误会不可逆地传播到抽取阶段,前一步抓错一个框,后面再好的抽取也无力回天。端到端生成范式则用一个多模态模型直接从图像生成结构化输出,避免了级联误差,但又带来新问题:通用模型倾向于生成"语义流畅的描述",而不是"严格的数据库记录",因缺乏领域对齐而频繁出现格式错误或关键信息遗漏。
StructBill-CN 站在端到端这一侧,但它要补的恰恰是端到端范式的短板:用 schema 约束把"流畅描述"逼回"严格记录",用逻辑约束把"看起来对"逼成"算术上对"。这意味着数据集本身必须承载这两类约束——否则模型没有任何信号可学。这也是它与 FUNSD、DocVQA等只标注键值对或物理框的数据集的根本分野。
40.1.2 一次错位如何级联成一条废记录¶
逻辑约束之所以重要,是因为票据数据的错误不是孤立的。设想一张无线费用清单,其中某一列存在稀疏空值。模型在缺少网格线的情况下发生了行错位:把第 3 行的金额读到了第 2 行。单看字符识别,每个数字都"读对了",ANLS 甚至很高;但行级「单价 × 数量 = 金额」会在错位行失败,文档级「Σ 明细 = 总额」也会失衡。结果是:一条字符识别近乎完美的记录,在业务上彻底不可用——它既不能入库,也不能用于理赔核算。
这正是为什么本章反复强调"算术自洽"必须成为一等公民:在高风险结构化抽取里,衡量数据质量的单位不是字符,而是可入库的记录。一份只看字符级指标的数据集,无法暴露这种级联失效;而 StructBill-CN 通过显式的逻辑约束与 §40.4 的一致性门禁,把"这条记录到底能不能用"变成了可标注、可校验、可度量的对象。
案例A.2:数据集概览:规模、来源、业务 schema 与任务定义¶
40.2.1 规模与来源¶
StructBill-CN 共包含 2,300 张高分辨率票据图像,覆盖 6 类不同的业务 schema,全部来自两个公开医疗数据集:CHIP-2022与 SIBR-Med。这一组合刻意混合了有线网格表、文本密集型记录与无线表三种形态,使模型必须跨越不同分布,而不是在单一文档样式上做模式匹配。数据组成如表 40-1。
表 40-1:StructBill-CN 数据组成与特征(原始材料)
| 来源子集 | 文档类型 | 数量 | 表格形态 |
|---|---|---|---|
| CHIP-2022 | 住院发票 | 680 | 有线网格 |
| CHIP-2022 | 门诊发票 | 340 | 有线网格 |
| CHIP-2022 | 药房发票 | 340 | 有线网格 |
| CHIP-2022 | 出院记录 | 340 | 文本密集 |
| SIBR-Med | 费用清单 | 400 | 无线表 |
| SIBR-Med | 通知单 | 200 | 无表格 |
| 合计 | 6 类 schema | 2,300 | 混合 |
需要强调的是,这里所有图像均来自公开学术数据集,这是一个数据合规上的有意选择:把可发布的 benchmark 建立在公开来源之上,把真实私有数据留到生产部署阶段再按合规流程接入(详见 §40.6 的隐私与审计讨论)。这种「公开基准 / 私有生产」的分层,本身就是高风险文档数据工程的一个基本原则。
代码与数据资源。 StructBill-CN 数据集、schema 定义和标注工具见 github.com/vanvan6992/StructBill-CN。SRPO 算法实现(含 MindSpore 版 GRPO 与 SCL-Reward)见 github.com/Yuefeng-Zou/SRPO_CODE。
下面的代码示例说明数据集如何接入 MindSpore 中的 SRPO 训练循环。它串起了完整的数据消费路径:读取样本、采样候选输出、用 SCL-Reward 为每个候选打分、计算组内相对优势,并通过 GRPO loss 更新策略模型,从而把数据集里的 schema 与逻辑约束转化为可训练的信号。
代码清单40-1给出了流程示例。
import mindspore as ms
from mindspore import nn, ops
from mindspore.dataset import GeneratorDataset
# ---- 1. Dataset:每个样本输出 (image, schema_id, ground_truth_json) ----
class StructBillDataset:
def __init__(self, manifest_path):
self.records = load_manifest(manifest_path) # image path + schema id + GT
def __len__(self):
return len(self.records)
def __getitem__(self, i):
r = self.records[i]
image = preprocess(load_image(r["image_path"]))
return image, r["schema_id"], r["gt_json"]
train_set = GeneratorDataset(
StructBillDataset("train_manifest.json"),
column_names=["image", "schema_id", "gt_json"],
shuffle=True,
).batch(BATCH_SIZE)
# ---- 2. SCL-Reward:把一次预测转成标量奖励 ----
def scl_reward(pred_text, gt_json, schema, lam=0.4, gamma=0.6):
gate, row_acr, doc_acr = validate_logic(pred_text, schema) # 本节后文定义
if not gate: # structure / hallucination veto
return 0.0 # I_gate = 0 -> reward zeroed
r_content = content_alignment(pred_text, gt_json, schema) # Hungarian match
r_logic = gamma * row_acr + (1 - gamma) * doc_acr
return lam * r_content + (1 - lam) * r_logic # Eq. (6)
# ---- 3. GRPO step:组采样 -> advantage -> policy update ----
def grpo_train_step(policy, batch, G=8):
images, schema_ids, gts = batch
advantages, logp_list = [], []
for image, sid, gt in zip(images, schema_ids, gts):
schema = SCHEMA_REGISTRY[sid]
cands = policy.sample(image, schema, num=G) # G candidates
rewards = ms.Tensor([scl_reward(c.text, gt, schema) for c in cands])
adv = (rewards - rewards.mean()) / (rewards.std() + 1e-4) # Eq. (4)
advantages.append(adv)
logp_list.append(ops.stack([c.logp for c in cands]))
def forward():
return grpo_loss(logp_list, advantages, clip_eps=0.2, kl_beta=0.04) # Eq. (5)
loss, grads = ms.value_and_grad(forward, None, policy.trainable_params())()
optimizer(grads)
return loss
# ---- 4. Training loop:SFT warmup 后得到 reference policy ----
policy = load_sft_warmup_model("qwen3-vl-2b")
optimizer = nn.AdamWeightDecay(policy.trainable_params(), learning_rate=1e-5)
for epoch in range(EPOCHS):
for batch in train_set.create_tuple_iterator():
loss = grpo_train_step(policy, batch, G=8)
代码清单40-1:流程示例。
40.2.2 任务定义¶
形式上,给定一张文档图像 \(X\) 与一份 schema 定义 \(S=\{K, T, C\}\),其中 \(K\) 是待抽取的全局键字段集合,\(T\) 是表结构定义,\(C\) 是确定性约束规则。目标是学习一个策略,使生成的结构化序列 \(Y\) 在给定 \(X\) 与 \(S\) 条件下最大化后验概率 \(P(Y\,|\,X, S)\)。
与传统的端到端文本生成不同,这个任务要求输出严格遵守预定义的结构约束与业务逻辑:它不仅要"内容对",还要"结构合法"且"算术自洽"。正是 \(S\) 中这三个组成部分——键字段、表结构、约束规则——把一个 OCR/抽取任务,升级成了一个「结构 + 逻辑」双重受约束的抽取任务,也直接决定了后文标注规范与评测协议的设计。
40.2.3 数据集刻意暴露的三类核心挑战¶
StructBill-CN 在选材与标注上刻意保留了三类"难",使它成为一个真正的压力测试基准,而不是规整票据的"舒适区"。
其一,缺乏显式视觉线索。 无线表的普遍存在——缺少竖直分隔符——导致密集数字列在视觉上彼此粘连,频繁引发基于分割方法的列错位与失败。对数据工程的含义是:标注阶段必须以语义而非几何来切列,质检阶段必须有列归属的复核手段。
其二,结构歧义与幻觉风险。 非结构化文本块会诱导模型把正文"编造"成表格行;而稀疏空值列又会引发整行平移错误。对数据工程的含义是:需要为相应 schema 显式声明反幻觉约束,并在标注规范中明确空值的占位与对齐规则。
其三,极端密度与视觉噪声。 真实业务文档会产生超长序列,挑战长程注意力;物理退化(污损、模糊)与语义相近字段,则严苛地考验细粒度判别与稳健性。对数据工程的含义是:采集阶段就要做质量分级与分桶,把"图像不可读"与"模型读不对"从源头分离。
这三类挑战不是缺陷,而是设计目标:它们决定了 §40.4 流水线里"为什么要有逻辑门禁、为什么要做质量分级、为什么标注要语义优先"。
不同 schema 的图像形态也各有侧重,理解这一点有助于在切分与采样时保持分布可控:CHIP-2022 的住院/门诊/药房发票是有线网格,结构相对规整,主要考验密集字段的精确抽取;出院记录是文本密集型,几乎没有表格,考验长文本理解与全局键值定位;SIBR-Med 的费用清单是典型无线表,是行列对齐与逻辑一致性的主战场;通知单则无表格,用于检验模型在"该没有表时不要捏造表"上的克制能力。
案例A.3:样本 schema:Key-Value、Line-Item Table、层级 JSON 与逻辑约束¶
40.3.1 三类监督信号¶
StructBill-CN 的每个样本,把一张票据图像与一份预定义 schema 配对,并同时携带三类互补的监督信号:
- 全局 Key-Value 结构:捕获文档级属性,例如医院名称、发票号、总金额。
- 嵌套的 line-item Table:每一行携带单元格级字段,例如项目名称、单价、数量、金额。
- schema 绑定的逻辑约束:让每一个数值字段都可以被确定性的算术规则验证。
与传统「转写 + 包围框」基准最大的不同在于:StructBill-CN 的标注语义归属优先于物理位置——在存在打印偏移或无线表布局时,标签按业务逻辑上下文分配,而不是按几何坐标。这迫使模型从内容逻辑去推断结构,而不是依赖肤浅的视觉定位。这一条标注哲学,是后面整个质量控制与评测能否成立的根基。
为什么选择层级 JSON而不是扁平键值或物理坐标?原始材料的标注协议给出了清晰的工程理由:层级 JSON 把 ground truth 组织成"全局键值属性 + 嵌套行项目列表",直接对标真实数据库 schema,从而把下游后处理降到最低——抽取结果可以近乎零转换地灌入业务系统。相比之下,扁平键值无法表达"一张单里有多行明细"的一对多结构,而物理坐标(包围框)虽然精确,却把"语义"留给了下游去猜。层级 JSON 是"ingestion-ready(可直接入库)"这一目标的自然产物。
语义归属优先的标注原则,在实践中常常与直觉相反。举例来说,当一行因打印偏移而在视觉上落到了相邻列下方,标注员应当依据"它在业务上属于哪个字段"来打标,而不是"它在像素上压在哪条线下"。这条原则把判断依据从几何转向逻辑,代价是标注难度更高、对标注员的领域理解要求更高,但收益是模型被迫学习内容逻辑而非视觉投影——这也是无线表场景下较稳妥的对齐策略,后文质检与评测口径也需要围绕"语义正确"而非"位置正确"来设计。
40.3.2 Schema 到层级 JSON 的映射¶
schema 的三个部分 \(\{K, T, C\}\) 与最终的层级 JSON 一一对应:\(K\) 落到全局 key_information 对象,\(T\) 落到 Fee_List 数组及其行内字段,\(C\) 则不直接成为字段,而是作为「校验关系」贴附在数值字段之上。结构关系如图 40-1。
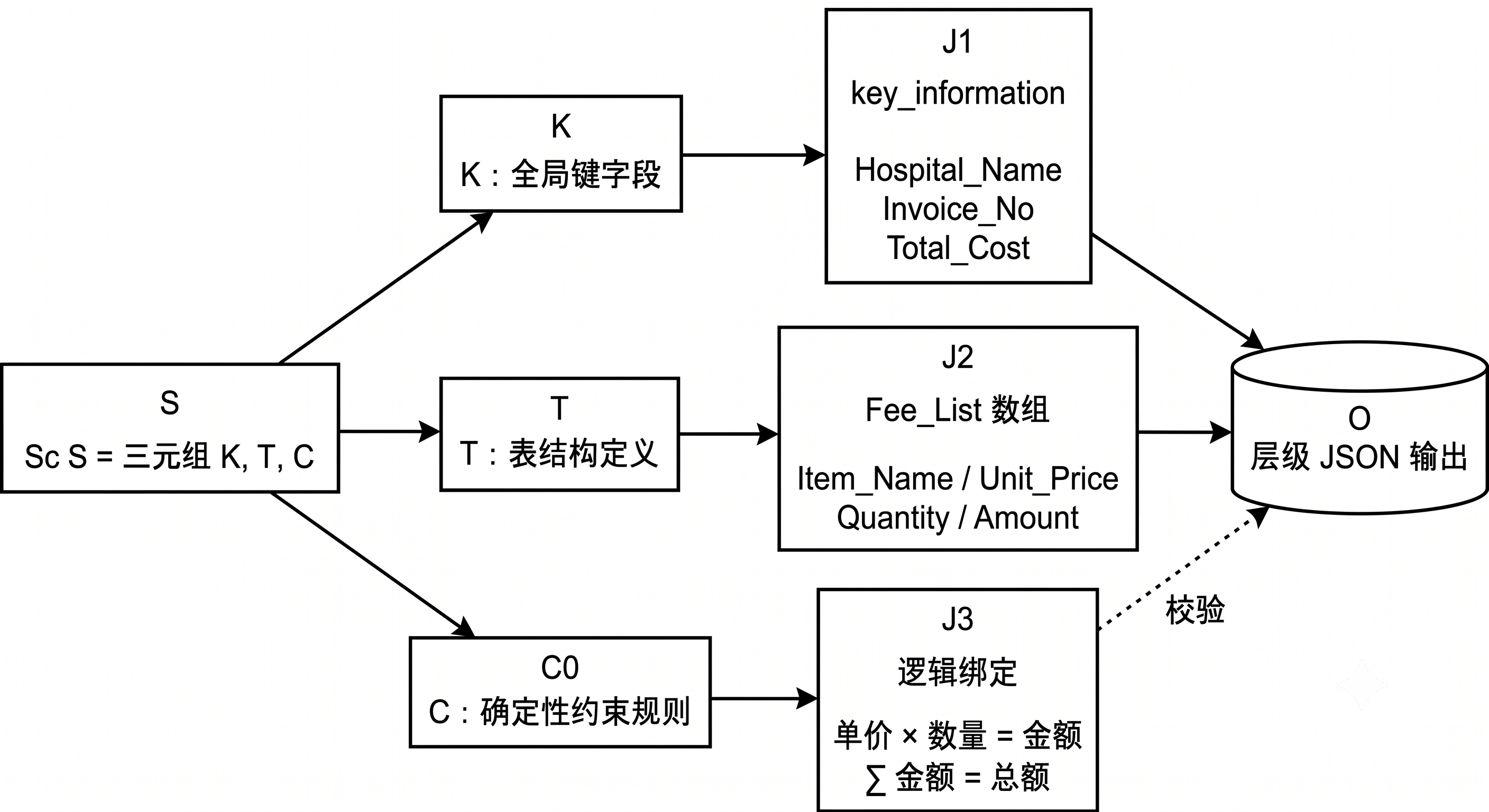
图 40-1:Schema 到层级 JSON 的结构示意 —— 键字段与表结构构成可见的 JSON 节点;约束规则不是节点,而是贴附在金额、总额等数值字段上的可验证关系。
这种"约束作为关系、而非字段"的设计,是层级 JSON 能同时服务于训练与评测的关键。约束 \(C\) 不占据 JSON 的任何键位,因此不会改变输出格式;但它在校验阶段被实例化为一组等式,既可以在构建期检验标注是否自洽,又可以在评测期度量模型输出是否守约。一份 schema 的演进(例如新增一条"折后金额 = 金额 × 折扣率"),只需在 \(C\) 中追加规则,而无需改动已有字段与历史标注——这正是数据契约可向后兼容演进的基础。
40.3.3 完整样本结构示例¶
下面给出一个抽象化的层级 JSON 样本(字段与逻辑关系来自原始材料的样例)。注释中标出了两类逻辑校验点:行级与文档级。
StructBill-CN 样本结构示例(抽象化层级 JSON):
代码清单40-2给出了JSON 数据示例。
{
"key_information": {
"Hospital_Name": "<医院名称>",
"Invoice_No": "4700852972",
"Total_Cost": 699.02 // = Σ Amount [文档级校验]
},
"Fee_List": [
{
"Item_Name": "<项目 A>",
"Unit_Price": 54.76,
"Quantity": 1.00,
"Amount": 54.76 // = Unit_Price × Quantity [行级校验]
},
{
"Item_Name": "<项目 B>",
"Unit_Price": 2.10,
"Quantity": 2.00,
"Amount": 4.20 // = 2.10 × 2.00
}
]
}
代码清单40-2:JSON 数据示例。
这个样本框很小,但它把本章的闭环讲清楚了:key_information 与 Fee_List 是结构,注释里的等式是逻辑约束,两者都要被标注、被校验、被评测。后文的流水线、质检与指标,全部围绕「如何让这个 JSON 既结构合法又算术自洽」展开。
代码清单40-3展示了 schema \(S=\{K, T, C\}\) 的程序化表示。每种业务文档类型对应一个 Schema 实例;三个约束字段(price_field、qty_field、amount_field)加上 total_field 在不改变 JSON 输出格式的前提下编码了算术规则 \(C\)。
@dataclass
class Schema:
"""单种业务文档的 schema 定义 S = {K, T, C}。"""
root_keys: List[str] # K:全局必填键字段
table_key: Optional[str] = None # T:JSON 中的行项目表键名
row_fields: List[str] = field(default_factory=list)
price_field: Optional[str] = None # ┐
qty_field: Optional[str] = None # │ C:确定性
amount_field: Optional[str] = None # │ 约束字段
total_field: Optional[str] = None # ┘
anti_hallucination: bool = True
# 示例:医疗费用清单 schema
expense_schema = Schema(
root_keys=["Hospital_Name", "Invoice_No", "Total_Cost"],
table_key="Fee_List",
row_fields=["Item_Name", "Unit_Price", "Quantity", "Amount"],
price_field="Unit_Price",
qty_field="Quantity",
amount_field="Amount",
total_field="Total_Cost",
)
代码清单40-3:Python 实现片段。
40.3.4 字段类型、标注规则与评测指标的对应关系¶
不同字段类型的标注规则与评测方式并不相同。把它们对齐成表,是后续标注规范与评测脚本的"契约",也是新标注员上手的速查表。
表 40-2:字段类型 × 标注规则 × 评测指标对照表
| 字段类别 | 代表字段(来自样例) | 标注规则 | 主要评测指标 |
|---|---|---|---|
| 文本属性 | Hospital_Name、Item_Name |
语义归属优先;长文本容忍轻微 OCR 噪声 | ANLS / Entity-Level F1 |
| 编号/字符串 | Invoice_No |
精确转写;保留前导零与分隔符 | 精确匹配 F1 |
| 数值属性 | Unit_Price、Quantity、Amount |
标准化小数格式;绑定行级算术规则 | 精确匹配 F1 + Row-ACR |
| 全局汇总 | Total_Cost |
与明细求和绑定 | Doc-ACR |
| 结构/拓扑 | Fee_List 行集合 |
行级对齐;空值用占位保持拓扑 | TEDS / Table-F1 |
表 40-2 中字段均取自原始材料的样例 JSON;ANLS、F1、TEDS、ACR 等指标定义见 §40.5。
案例A.4:构建流水线:采集、去噪、标注、Schema 对齐、逻辑校验、版本切分¶
StructBill-CN 通过一条多阶段流水线构建,核心诉求是同时保留语义内容与业务逻辑拓扑,并在每一步设置可回溯的质量门禁。整体数据流如图 40-2。
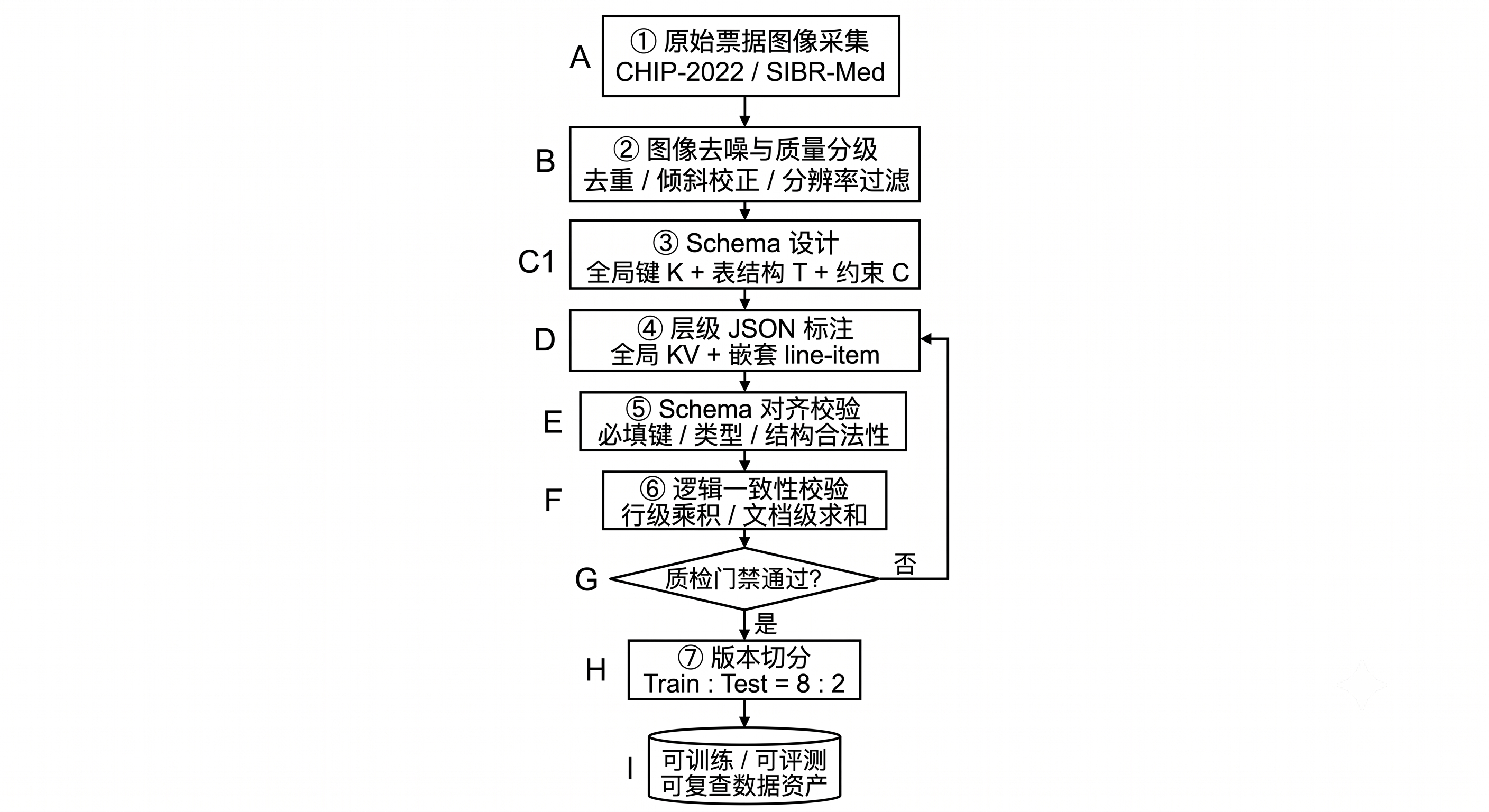
图 40-2:StructBill-CN 数据构建流水线 —— 关键设计是第 ⑥ 步与质检门禁:未通过逻辑一致性校验的样本会回流到标注阶段重做,而不是直接进入训练集。
下面逐阶段说明数据工程要点。
① 采集。 图像来自公开学术语料 CHIP-2022 与 SIBR-Med,刻意偏重无线表、稀疏布局与长费用清单等"难样本",以保证基准能够暴露真实失败模式,而不是只覆盖规整票据。
② 去噪与质量分级。 这一步是后续标注与逻辑校验能否成立的前提,工程上至少应包含:重复图像去重、倾斜/旋转校正、过低分辨率与严重残缺图像的过滤或单独分桶。质量分级的产物不只是"干净图像",还包括一份图像质量元数据,供后续错误归因时区分"模型错"还是"图像本身不可读"。
③ Schema 设计。 为每一类业务文档定义 \(S=\{K, T, C\}\):先确定全局键字段 \(K\) 与表结构 \(T\),再把领域算术规则写进约束 \(C\)(行级乘积关系、文档级求和关系)。schema 是这份数据资产的"契约",它一旦冻结,标注规范与评测脚本都以它为准(参见 §40.7 对 Ch27–Ch30 数据契约治理的回链)。
④ 层级 JSON 标注。 ground truth 被组织成"全局 Key-Value 属性 + 嵌套 line-item 列表"的 ingestion-ready 层级 JSON。标注按语义归属(而非几何坐标)分配标签,从而最小化下游后处理。对无表格的通知单这类文档,Fee_List 可为空,但 schema 结构保持一致,避免格式分叉。
⑤ Schema 对齐校验。 这是第一道自动门禁:检查 JSON 是否可被标准解析、是否包含 schema 规定的全部必填根键与表键、字段类型是否匹配。任何结构非法的标注在此被拦截。
⑥ 逻辑一致性校验。 这是 StructBill-CN 区别于普通抽取数据集的核心步骤——对标注本身做算术自洽性检查:逐行验证「单价 × 数量 ≈ 金额」,并验证「明细金额之和 ≈ 总额」(均带容差 \(\varepsilon\) 以吸收 OCR 浮点误差)。校验流程见图 40-3。只有当标注本身算术自洽时,它才能作为可靠的逻辑监督信号;否则后续基于该数据训练的奖励信号就是"脏"的。
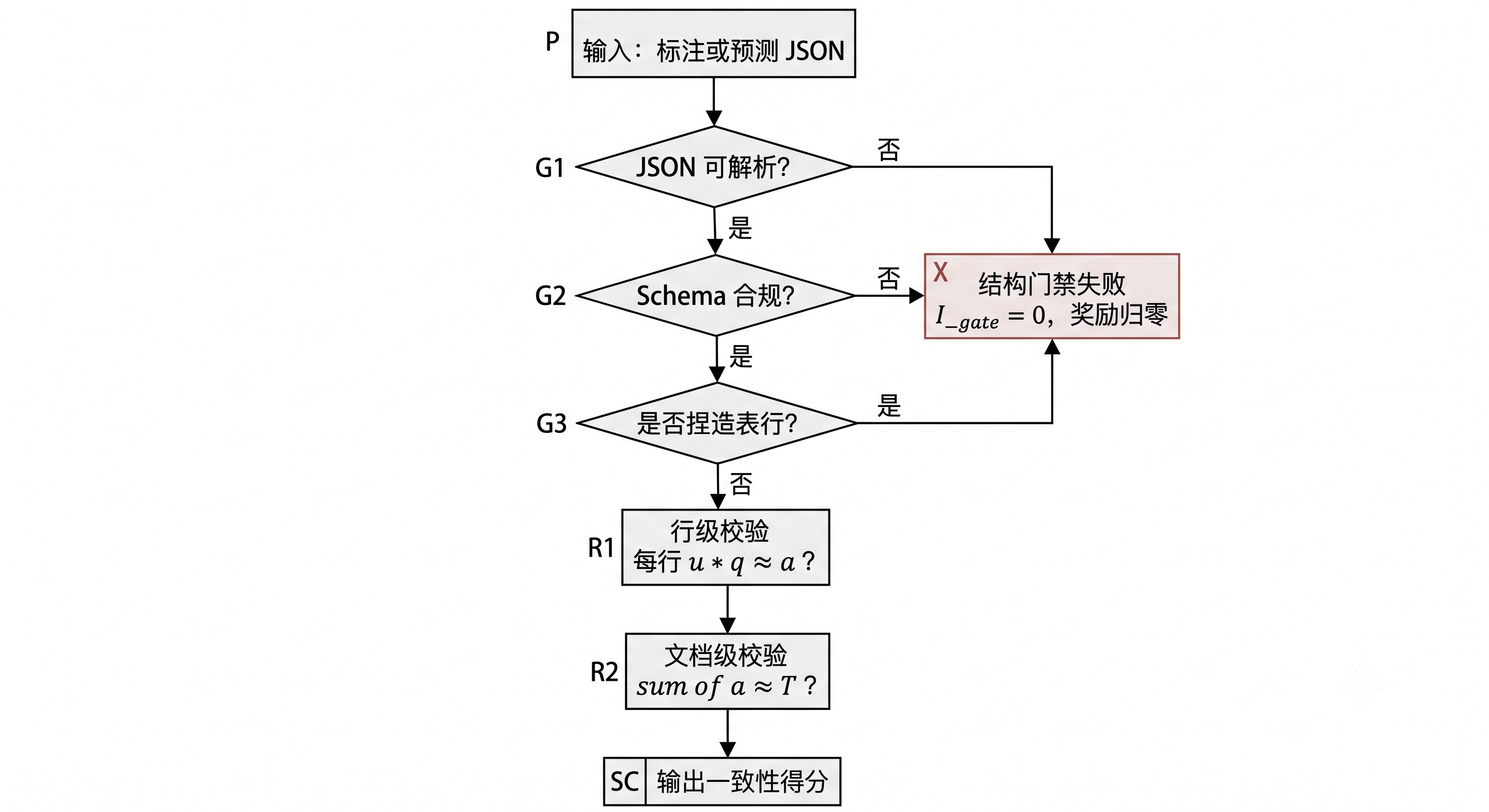
图 40-3:逻辑一致性校验流程 —— 同一套门禁逻辑在两处复用:构建期用于拦截不自洽的标注,评测/训练期用于给模型输出打一致性分(即 §40.6 的 SCL-Reward 中的结构门禁 \(I_{gate}\) 与逻辑奖励 \(R_{logic}\))。这种"构建即评测"的复用,是保证训练目标与评测口径一致的关键工程手段。
代码清单40-4实现了图 40-3 中的结构门禁(\(I_{gate}\))、行级检查(Row-ACR)与文档级检查(Doc-ACR)。它在构建流水线中拦截不自洽的标注,在评测流水线中给模型输出打分——同一份代码、两处复用。输入的 Schema 来自代码清单40-3。
def validate_logic(pred_text: str, schema: Schema, eps: float = 0.01
) -> Tuple[bool, float, float]:
"""逻辑一致性校验门禁。
返回 (gate_pass, row_acr, doc_acr)。
构建期拦截坏标注、评测期给模型输出打分——同一份代码两处复用。
"""
# ── 结构门禁 (I_gate) ──
try:
obj = json.loads(pred_text)
except json.JSONDecodeError:
return False, 0.0, 0.0 # 非法 JSON → 门禁失败
ki = obj.get("key_information", {})
if any(k not in ki for k in schema.root_keys):
return False, 0.0, 0.0 # 缺少必填键
rows = obj.get(schema.table_key, []) if schema.table_key else []
# ── 行级校验:|单价 × 数量 − 金额| < ε ──
ok, checked = 0, 0
row_amounts = []
for r in rows:
u, q, a = r.get(schema.price_field), r.get(schema.qty_field), r.get(schema.amount_field)
if u is None or q is None or a is None:
continue
u, q, a = float(u), float(q), float(a)
checked += 1
if abs(u * q - a) < eps:
ok += 1
row_amounts.append(a)
row_acr = ok / checked if checked else 1.0
# ── 文档级校验:|Σ 金额 − 总额| < ε ──
total = ki.get(schema.total_field)
if total is not None and row_amounts:
doc_acr = 1.0 if abs(sum(row_amounts) - float(total)) < eps else 0.0
else:
doc_acr = 1.0
return True, row_acr, doc_acr
代码清单40-4:流程示例。
⑦ 版本切分。 数据集按训练 : 测试 = 8:2 切分。工程实践上建议:切分时保证 6 类 schema 在两侧的分布可控、留出真正的跨布局测试样本;并可从训练集再切出一个小验证子集用于调参,但不污染测试集。每一个版本都应带上数据指纹与统计快照,接入数据版本与实验追踪体系。
40.4.1 数据血缘与元数据:让每条记录都可回溯¶
上述七个阶段如果只产出"图像 + JSON",是不够的。一份可复查的数据资产,还必须为每条样本附带一组血缘元数据,至少包括:源子集与原始文件标识、所属 schema 及其版本号、图像质量分级(来自第②步)、标注人与复核人、各项逻辑校验的通过/失败结论及容差、以及最终所属的数据切分。
这组元数据有三重作用。第一,错误归因。 当某指标回归时,可据此区分是图像质量、标注口径还是模型能力的问题。第二,审计合规。 高风险数据要求"谁、在哪个版本、为什么改"全程可追溯(详见 §40.6.3)。第三,可复现。 schema 版本与切分指纹被钉死后,任何一次实验都能精确复原它消费的数据子集。换言之,元数据不是附属品,而是把"数据集"升级为"数据资产"的关键一环。
值得单独点出的是 SFT 暖启数据的特殊地位。SRPO 的第一阶段需要一份能让模型产出"语法合法 JSON"的监督数据;如果这部分数据本身结构不干净,强化学习阶段就失去了稳定的起点。因此 §40.4 第⑤步的结构合规门禁,对暖启数据尤其严格——宁可回流复标,也不让结构非法的样本进入 SFT 集。
案例A.5:评测协议:字段、结构、表格、算术一致性与错误归因¶
StructBill-CN 的评测沿三个维度展开——抽取准确率、结构质量、逻辑一致性,对应的指标如下。
- KV-F1 / Table-F1(Entity-Level F1):分别衡量全局键值字段与表格行内字段的抽取精确率与召回率。
- ANLS(Average Normalized Levenshtein Similarity):长文本字段的字符级准确率,对轻微 OCR 噪声有容忍。
- TEDS(Tree-Edit-Distance-based Similarity):基于树编辑距离的相似度,衡量生成 JSON 的拓扑正确性,对复杂嵌套表格尤为关键。
- ACR(Arithmetic Consistency Rate,算术一致性率):核心逻辑推理指标,由两部分组成——Row-ACR(满足「单价 × 数量 ≈ 金额」的表行占比)与 Doc-ACR(满足「Σ 明细金额 ≈ 总额」的文档占比)。
- CHIP-2022 Score:对公开 CHIP-2022 子集,另报官方榜单的 Score(全字段 Macro-F1,类目/数值字段用精确匹配 F1、文本密集字段用归一化编辑距离)。
这些指标之所以要分维度并存,是因为它们彼此无法替代:F1 衡量"抓没抓到、抓得对不对",但对一个数字是 54.76 还是 54.67 并不敏感(两者编辑距离很小);ANLS 对长文本的轻微噪声宽容,却不能保证算术正确;TEDS 关注的是 JSON 树的拓扑——行列对齐、嵌套层级、合并单元格的恢复——它能抓住"结构塌了"的问题,却管不了"内容错了";只有 Row-ACR 与 Doc-ACR 直接回答最关键的问题:"这些数字加得起来吗?"一个健康的评测必须同时盯住这四类指标,因为任何单一指标都可能给出"虚高"的安全感。
把这些指标与 §40.3 的字段类型对齐,就构成了一个评测闭环:文本字段看 ANLS / Entity-F1,编号看精确匹配,数值字段看 F1 并叠加 Row-ACR,全局总额看 Doc-ACR,整体结构看 TEDS / Table-F1。也就是说,schema 定义了字段 → 标注规范决定了 ground truth → 逻辑校验产出一致性标签 → 指标分维度度量,四者首尾相接,没有任何一环是悬空的。
40.5.1 Schema 约束违反率:一个面向工程的补充指标¶
学术指标偏正向("对了多少"),但生产监控更关心负向("违反了多少")。可以从 §40.4 的门禁逻辑直接派生一个Schema 约束违反率:在一批输出中,未通过结构门禁或逻辑校验的样本占比。它本质上是结构门禁 \(I_{gate}\) 与一致性校验的"不通过率",与 Doc-ACR/Row-ACR 互补——前者回答"算术错没错",SCVR 回答"包括结构在内一共有多少条不可直接入库"。这个指标不需要新增标注,只需复用图 40-3 的校验流程,因此适合做线上数据质量看板与回归门禁。
SCVR 是本章为工程监控目的给出的派生指标定义(不引入任何新的数据事实或数值),其判定逻辑完全复用原始材料中的结构门禁与逻辑校验。
代码清单40-5基于代码清单40-4的 validate_logic,在一批模型预测上计算 SCVR 及其伴随指标。它不需要额外标注,只复用已有的 schema 与算术约束。
def compute_scvr(predictions: list, schema: Schema,
eps: float = 0.01) -> dict:
"""在一批模型预测上计算 SCVR 及伴随指标。
SCVR = 未通过结构或逻辑门禁的记录占比
(即不可直接入库的比例)。
"""
n = len(predictions)
violations = 0
row_acrs, doc_acrs = [], []
for pred_text in predictions:
gate, row_acr, doc_acr = validate_logic(pred_text, schema, eps)
if not gate:
violations += 1 # 结构或幻觉门禁失败
else:
row_acrs.append(row_acr)
doc_acrs.append(doc_acr)
scvr = violations / n if n else 0.0
return {
"scvr": scvr,
"ingestible_rate": 1.0 - scvr, # 补数:可直接入库的比例
"mean_row_acr": sum(row_acrs) / len(row_acrs) if row_acrs else 0.0,
"mean_doc_acr": sum(doc_acrs) / len(doc_acrs) if doc_acrs else 0.0,
}
# 使用示例:
# metrics = compute_scvr(model_outputs, expense_schema)
# print(f"SCVR={metrics['scvr']:.1%}, 可入库率={metrics['ingestible_rate']:.1%}")
代码清单40-5:流程示例。
40.5.2 可复现评测的工程约定¶
逻辑约束让评测更可信,但要让评测可复现,还需要一组工程约定:固定测试切分并钉死其指纹、固定 schema 版本、固定指标实现(同一份 TEDS / ACR 脚本)、控制随机种子。对生成式模型而言,解码参数与运行次数尤其影响可复现性。
为吸收大模型解码方差,在评测时采用 temperature=0.9、top_p=1.0,并对每个模型取 8 次独立运行**的平均后再报告指标。单次运行的分数在高温采样下波动较大,多次平均才能得到稳定可比的结论。工程上建议把"解码参数 + 运行次数 + 随机种子"一并写入评测配置并随结果归档。
40.5.3 错误归因与修复动作¶
评测不止给一个分数,更要能把错误归因到可操作的修复动作上。表 40-3 把本数据集刻意暴露的失败模式,与对应的数据工程修复手段配对。这张表既是评测后的"分诊单",也是标注规范的"反向校验清单"。
表 40-3:常见错误与修复动作表
| 错误类型 | 现象 | 根因 | 数据工程修复动作 |
|---|---|---|---|
| 数值幻觉 | 金额/数量被凭空生成或抄错 | token 级近似、缺逻辑约束 | 绑定 P×Q=A 与 Σ=T 约束;以 Doc-ACR 作为质检门禁;构造数值负样本 |
| 空间漂移 | 字段抓到相邻列/行的值 | 无线表缺网格线 | 语义归属标注;列不变锚点对齐复查;标注时记录列归属 |
| 捏造表行 | 把正文文字编造成表格行 | 非结构文本块诱导 | 幻觉过滤门禁(\(I_{gate}=0\));为相应 schema 打 anti_hallucination 标记 |
| 行错位 | 稀疏空值列导致整行平移 | 空单元缺占位 | 空值占位标注;行级匹配(Hungarian)复查;空列样本单独分桶 |
| 结构非法 | JSON 不可解析 / 缺必填键 | 自由生成、未约束 | Schema 合规门禁;结构校验脚本前置;schema 版本冻结 |
| 汇总不平 | Σ 明细 ≠ 总额 | 缺文档级校验 | 文档级一致性校验;超容差样本回流复标并标注成因 |
错误归因的工程价值在于:当某个指标下降时,能立刻定位是"图像不可读(②的质量问题)""标注口径漂移(④的规范问题)"还是"模型能力不足(训练问题)"。结合 §40.4 第②步产出的图像质量元数据,可以把"模型错"与"数据本身不可解"分开统计,避免把低质量数据的锅扣到模型头上。
更进一步,错误归因表(表 40-3)应当与标注规范双向绑定:每当线上发现一类高频错误,就回看它对应的标注规则是否存在歧义或盲区,必要时更新规范并触发受影响样本的回流复标。这样,评测就不再是训练结束后的"一次性体检",而成为持续驱动数据质量迭代的反馈回路——这也是把 StructBill-CN 当作"活的数据资产"而非"静态测试集"来运营的核心做法。
案例A.6:工程复盘:适合训练什么、评估什么、不该滥用到哪里¶
40.6.1 数据资产支撑的算法:SRPO(点到为止)¶
本章不展开模型细节,只从"数据如何被消费"的角度说明三者关系:
- 数据 → 奖励信号。 SRPO 的核心是把 §40.3 的离散 schema 规则,转成稠密、可验证的奖励——即 SCL-Reward:\(R_{total}=I_{gate}\cdot[\lambda\cdot R_{content}+(1-\lambda)\cdot R_{logic}]\)。其中结构门禁 \(I_{gate}\)、内容对齐 \(R_{content}\)(用 Hungarian 匹配解决表行乱序)、逻辑校验 \(R_{logic}\)(即图 40-3 的行级/文档级一致性)三者,全部直接读取本数据集的层级 JSON 与逻辑约束。这正是为什么数据集必须先在构建期做逻辑自洽校验:奖励的可靠性,等于标注的可靠性。
- 训练消费方式。 SRPO 分两段消费数据:先用数据做 SFT 暖启,得到能产出合法 JSON 的参考策略;再用 GRPO(Shao et al., 2024) 做强化学习,按组采样多个候选、用 SCL-Reward 打分、以组内相对优势更新。原始材料给出的训练配置为:SFT 10 epochs、学习率 1e−5、batch size 128;GRPO 组大小 G=8、奖励系数 \(\lambda=0.4\)、\(\gamma=0.6\);硬件为 8× NVIDIA A800(80GB)。
- 效果(定性)。 原始材料表明,标准 SFT 的逻辑分会在 84% 附近"封顶",而引入逻辑奖励后 Row/Doc-ACR 有约 10 个百分点的提升——说明本数据集的逻辑标注确实把"算术一致性"变成了可优化的目标。本章不复述完整榜单,避免写成模型综述。
从数据消费的角度还能看出一个常被忽视的细节:内容对齐 \(R_{content}\) 之所以要用 Hungarian 匹配(Kuhn, 1955) 做"行级一对一对齐",正是因为模型生成的行序可能与 ground truth 不一致,或存在漏检、误检。这要求数据集的每一行都具备可用于匹配的、足够判别的字段(如项目名 + 单价 + 数量),而不是只有一个模糊的文本块。也就是说,奖励机制能否稳定工作,反过来对标注的"行级可区分性"提出了要求——这再一次说明:算法设计与数据标注规范是一体两面,必须协同设计。
40.6.2 适合训练什么、评估什么¶
适合训练:schema 受约束的中文垂直文档抽取小模型。本数据集天然适配"SFT 暖启 + 规则奖励 RL"的配方——它既提供合法结构的监督,又提供可验证的逻辑监督,因此适合训练 3B 级别的多模态文档模型在无线表、稀疏布局上的稳健对齐能力。
适合评估:逻辑一致性与结构保真度,而不仅仅是字符识别。它能回答"模型会不会算术自相矛盾""会不会捏造表行""能不能守住 schema"这类传统 OCR 基准回答不了的问题。
40.6.3 高风险场景下的隐私、合规与审计¶
医疗费用文档属于高风险数据,即便本基准使用的是公开学术来源,其方法论一旦扩展到真实生产数据,必须遵守以下底线。
隐私与去标识。 任何接入的真实票据/病历数据,必须在进入流水线前完成受保护健康信息(PHI)的去标识与脱敏;公开发布的基准只应基于已授权、已脱敏或公开的来源。
人在回路。 抽取结果用于理赔、审计、入库等下游决策时,必须保留人工复核环节;模型定位是辅助工具,不是自动决策器。
可审计性。 每条记录应可回溯到:源图像版本、schema 版本、标注人/复核人、逻辑校验结论。结合 §40.5 的 SCVR 与错误归因表,形成"谁、在哪个版本、为什么改"的审计链路。
脱敏风控:本基准的合规状态与生产扩展的字段级去标识化方案。 有必要把"本基准数据本身"与"方法论向私有数据扩展"两件事严格区分开来。
就基准数据而言,StructBill-CN 所采用的全部图像均来自公开学术数据集——CHIP-2022 与 SIBR-Med,两者在原始发布时已由数据集提供方完成去标识化处理,StructBill-CN 不额外接入任何受保护健康信息(PHI)。这是一个刻意的合规设计:把可公开发布的基准建立在已授权的公开来源之上,从源头消除 PHI 泄露风险。
就生产扩展而言,当本章的方法论被应用于真实私有票据/病历数据时,必须在数据进入流水线的最早阶段执行字段级脱敏。下表给出医疗费用文档中各类敏感字段的具体遮盖规则,供生产部署时作为去标识化规范的起点。
表40-4汇总了相应的对比和工程要点。
表 40-4:医疗费用文档字段级去标识化规则(面向生产扩展)
| 敏感字段类型 | 示例 | 遮盖规则 | 说明 |
|---|---|---|---|
| 患者姓名 | 张某某 | 完全替换为占位符 <NAME> 或不可逆 hash |
PHI 核心字段,必须完全去除 |
| 身份证号 / 社保号 | 110108… | 完全替换或仅保留末 4 位 | 直接标识符,不可保留全文 |
| 联系电话 | 138… | 完全替换或仅保留末 4 位 | 直接标识符 |
| 住址 | 北京市朝阳区… | 脱敏至省/市级,删除街道与门牌号 | 准标识符,保留粗粒度地理信息即可 |
| 医院名称 | 示例医院 | 公开基准中保留(公共机构信息);私有部署可选匿名化 | 通常不构成个人隐私 |
| 发票号 / 流水号 | 4700852972 | 公开基准中保留(去关联后无隐私风险);私有部署中替换为序列化伪 ID | 去关联后风险可控 |
| 金额 / 单价 / 数量 | 54.76 / 1.00 | 保留原值——算术约束校验(P×Q=A / Σ=T)依赖真实数值 | 若高风险场景要求金额脱敏,可对全单做等比例缩放后重算一致性以保证逻辑约束不被破坏 |
| 诊断 / 项目名称 | 青霉素注射液 | 公开基准中保留(医学术语非个人信息);涉及高度敏感疾病(如 HIV / 精神类)时替换为上位类目 | 视敏感程度分级处理 |
| 日期 | 2024-01-15 | 整单偏移固定随机天数(保持行间时序关系) | 偏移而非删除,以保留业务时序语义 |
该表有一个工程上常被忽视的要点:金额字段的脱敏与逻辑约束之间存在张力。如果把金额随机扰动,行级「单价 × 数量 = 金额」与文档级「Σ 明细 = 总额」将被破坏,导致后续 SCL-Reward 的逻辑校验信号变"脏"。推荐做法是:对全单金额做等比例缩放(即乘以一个统一的随机因子),再重新计算并写回 Total_Cost,从而在脱敏的同时保持算术自洽。这一操作必须在 §40.4 第⑥步(逻辑一致性校验)之前完成,并在血缘元数据中记录缩放因子,以便审计回溯。
40.6.4 不该滥用到哪里¶
明确边界同样重要。这份数据集不适合:
- 直接驱动临床诊疗或自动理赔的无人复核决策——它评测的是抽取一致性,不承担医疗/金融决策责任。
- 当作通用 OCR 或版面还原基准——它的标注是语义归属优先、逻辑约束绑定的,并非物理坐标还原。
- 在跨语言/跨域场景下不加验证地直接套用——它是中文医疗票据垂直数据,迁移到其他语言或行业需要重新做 schema 设计与逻辑校验。
- 作为多任务联合训练中与分类任务硬混合的唯一数据——原始材料指出,算术抽取与语义分类联合训练时存在负迁移,会拖累数值字段,需谨慎设计任务配比。
40.6.5 数据视角的演进方向¶
原始材料在展望中提到两点,对数据工程尤其有启发。其一,多任务负迁移:当算术抽取与分类任务联合训练时,语义理解与严格推理的优化梯度可能冲突,导致数值字段退化。这提示数据配方设计者:在 VLM 数据混合中,逻辑敏感的抽取数据与语义分类数据的配比、采样温度与课程顺序,本身就是需要被实验追踪的超参数,不能不加区分地统一混合。其二,从确定性约束走向自适应奖励:当前的逻辑奖励依赖手写的算术规则,未来可演进为数据驱动的自适应奖励。对数据集而言,这意味着约束规则 \(C\) 不必永远静态;可以预留一个"规则版本"维度,让 schema 的逻辑约束随业务演进而迭代,并用版本治理保证每次评测口径一致。
这两点共同说明:StructBill-CN 不是一个一次性产物,而是一个可演进的数据契约——schema、约束、切分都带版本,能随下游 VLM 与 RAG 项目的需求持续生长。
案例A:小结¶
StructBill-CN 不只是"又一个数据集",它解决的数据工程问题是:如何把高风险中文票据/医疗费用文档,从图像 + schema + 层级 JSON + 表格字段 + 逻辑约束出发,构建成一份可训练、可评测、可复查的数据资产。
本章用一条带逻辑一致性门禁的构建流水线、一套字段—标注—逻辑—指标对齐的评测闭环、一份可读的样本结构示例,以及隐私/合规/审计的底线约束,把这个问题讲成了一个可复现的工程范式。核心结论有三点。第一,在高风险结构化抽取里,衡量数据质量的单位不是字符,而是可入库的记录——只看字符级指标的数据集无法暴露行列错位、算术不一致和结构捏造等级联失效。第二,schema 既是标注规范的"契约",也是评测脚本的"基线",还是逻辑奖励的"输入"——三者首尾相接,任何一环悬空都会让整个体系失效。第三,StructBill-CN 不是一个一次性产物,而是一个可演进的数据契约——schema、约束、切分都带版本,能随下游 VLM 数据配方、多模态 RAG 与隐私流水线项目的需求持续生长。
案例B:SparseTable-Bench:稀疏表格、空单元格与结构鲁棒性¶
案例B:学习目标¶
通过本章学习,读者应能够:
- 解释表格结构识别相较于 OCR 与文本抽取,为何必须把行列拓扑、空单元格和跨行跨列关系作为一等监督对象。
- 掌握 SparseTable-Bench 将每张表格组织为 HTML 逻辑层、单元格文本语义层与 bbox 几何层三层同步表示的 schema 设计原理。
- 区分 STB-Train、STB-Val、STB-Standard-Test 与 STB-Mask-Stress 四个切分各自承担的训练、开发、标准泛化与遮挡压力测试职责。
- 分析空单元格占位缺失与文本左移如何系统性削弱传统 TSR 评测的判别力,并据此设计保留空位的标注约束。
- 解释 TEDS 与 TEDS-S 指标在结构鲁棒性评测中的差异,并结合 cell-level bbox 做出读错内容、排错结构与错位放置的错误归因。
案例B.1:表格结构识别为什么需要专门 benchmark¶
在视觉文档理解任务中,表格经常被简化为“图像中的文字块集合”。这种简化在密集表格中有时可以工作,因为每个行列位置都有显著文本,文本本身能够充当隐式锚点;但在边框弱、留白多、空列多或单元格合并频繁的场景中,文本锚点会迅速失效。模型看到的是一组离散文字和大面积空白,真正的网格线并不总是可见,逻辑结构只能从视觉排布、局部对齐和上下文先验中推断。
传统 TSR 评测更关注最终 HTML 树是否接近参考结构,或者关注单元格文本是否被正确填入。问题在于:如果数据标注没有显式保留空单元格,模型跳过空列也可能得到看似合理的文本序列;如果评测只比较非空文本,模型可能把第三列内容左移到第二列而不被充分惩罚;如果没有 cell-level bbox,模型即使生成了正确数量的 <td> 节点,也无法证明这些节点与图像中的真实位置对齐。对于财务报表、临床试验表、论文实验表格等场景,这类错误不是格式瑕疵,而是会改变数值所属字段和证据链的结构性错误。
SparseTable-Bench 把这些风险前置到数据设计中。它将表格样本视为由三层对象构成的复合结构:
- 逻辑层:由 HTML 标签表达行、列、单元格和跨度关系。
- 语义层:由每个单元格的文本内容表达可读信息,其中空单元格也作为显式对象保留。
- 几何层:由每个单元格的二维边界框表达其在图像中的空间位置。
这三层必须同步存在。只有 HTML 而没有 bbox,数据集无法约束模型是否真正学会空间对齐;只有 bbox 而没有 HTML,模型无法学习行列拓扑和跨行跨列结构;只有非空文本而没有空单元格占位,评测会系统性低估稀疏布局带来的结构难度。
案例B.2:数据集概览与任务边界¶
SparseTable-Bench 的任务可概括为“给定一张表格图像,恢复其可解析的结构化表示,并保持文本、结构和几何位置的一致性”。在训练和评测中,模型需要输出类似 HTML 的结构序列,同时在单元格级别对齐文本内容和 bbox。该数据集可定位为面向空间对齐感知表格识别框架的数据基础,既可用于普通 TSR 训练,也可用于检验 VLM 在稀疏、无边框、部分遮挡条件下的结构鲁棒性。在相关模型实验中,STB 常作为 SA-Table 及其 Structural Prior Injection Adapter(SPIA)等方法的数据支撑;本章不展开 SA-Table 或 SPIA 的模型结构,只借其需求说明 STB 的数据设计动机。
数据集公开入口为:
https://huggingface.co/datasets/champion666/SparseTable_Bench_Dataset
从规模上看,数据集说明中通常以“约 11,000 张表格图像”概括 STB;按切分统计,具体样本数为 10,983 张。为了避免混淆,本章以切分表中的数字为准。
表40-5列出了相关字段与出版复核口径。
表40-5:关键要点与工程复核口径。
| 切分 | 图像数量 | 标注格式 | 主要用途 |
|---|---|---|---|
| STB-Train | 8,000 | HTML + 单元格 bbox | 多任务监督训练 |
| STB-Val | 1,000 | HTML + 单元格 bbox | 超参数选择与开发集评估 |
| STB-Standard-Test | 1,000 | HTML + 单元格 bbox | 标准泛化评测 |
| STB-Mask-Stress | 983 | 遮挡表格 + 拓扑标签 | 稀疏和信息缺失条件下的鲁棒性评测 |
| 合计 | 10,983 | - | 训练、验证、标准测试与压力测试 |
从任务边界看,STB 至少覆盖三类能力。
第一类是表格结构识别。模型需要恢复 <table>、<tr>、<td> 等结构标签,并处理行列组织、空位、合并单元格和局部对齐。此处的重点不是把图像中所有文字读出来,而是把文字放回正确的网格位置。
第二类是几何感知标注。每个单元格都有边界框 bbox=[x1,y1,x2,y2]。这使数据集可以用于训练位置感知输出头、检查视觉特征与逻辑节点的对应关系,也可在错误分析时判断模型是读错内容、排错结构,还是把正确内容放到了错误位置。
第三类是掩码压力测试。STB-Mask-Stress 通过列级和局部遮挡主动减少文本线索,模拟严重稀疏或不完整视觉条件。它的目标不是制造更难的 OCR,而是测试模型能否在部分内容不可见时仍保留表格拓扑,尤其是空列、空单元格和跨列关系。
案例B.3:样本 schema:HTML、文本与 bbox 的同步表示¶
SparseTable-Bench 的一个核心设计是把每张表格图像表示为同步的多信号样本,而不是只保存一种目标格式。下面的示例展示了一个简化样本,其中第二个单元格为空,但它仍然是结构上有效的列位。
代码清单40-6给出了JSON 数据示例。
{
"html": "<table><tr><td>Revenue</td><td></td><td>$12.4M</td></tr></table>",
"cells": [
{
"text": "Revenue",
"bbox": [34, 52, 118, 74]
},
{
"text": "[EMPTY_CELL]",
"bbox": [118, 52, 215, 74]
},
{
"text": "$12.4M",
"bbox": [215, 52, 310, 74]
}
]
}
代码清单40-6:JSON 数据示例。
这里的 [EMPTY_CELL] 不是普通文本,而是用于表达“结构存在、内容为空”的占位符。它把单元格的结构身份和语义内容解耦:即使图像区域没有可读字符,该位置仍然有行列坐标、边界框和上下文关系。对于稀疏表格,这种占位符可以防止模型在生成时把空白区域当作不存在的区域,从而降低列坍缩和左移错误的概率。图 40-4 概括了同一表格样本中 HTML、文本和 bbox 三类监督信号的同步关系。
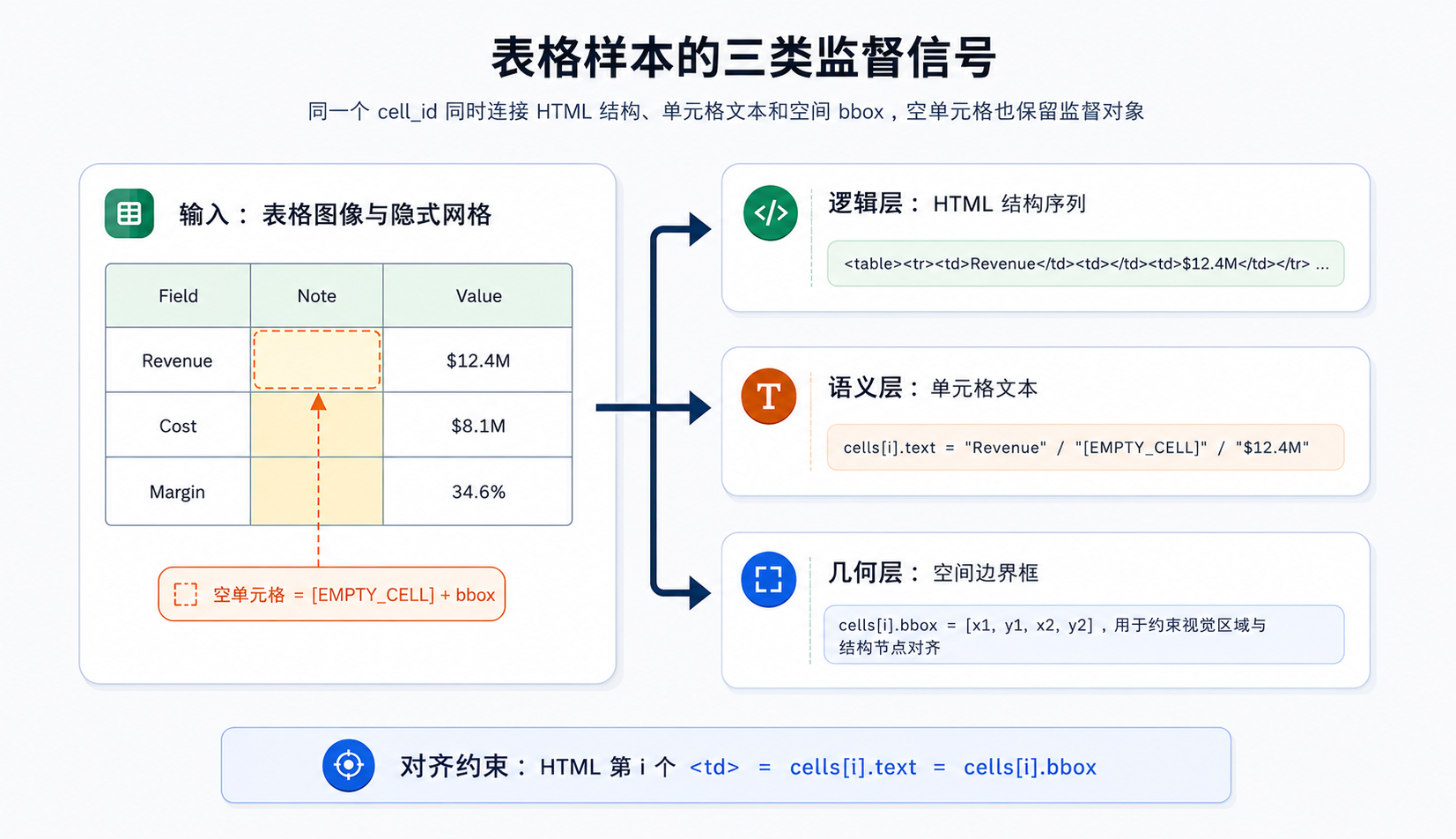
图40-4:表格样本三类监督信号结构图。
从数据工程角度看,STB 的样本 schema 至少包含以下字段和检查规则。
表40-6列出了相关字段与出版复核口径。
表40-6:字段说明与复核口径。
| 对象 | 典型字段 | 作用 | 质量检查要点 |
|---|---|---|---|
| 图像 | image_id、图像文件、宽高 |
作为视觉输入和 bbox 坐标参照 | 图像可打开;分辨率与 bbox 坐标系一致;无损坏页 |
| HTML 结构 | html、rowspan、colspan |
表达逻辑拓扑和输出序列 | HTML 可解析;行列数一致;合并单元格不造成网格冲突 |
| 单元格文本 | cells[i].text |
表达每个 cell 的语义内容 | 文本与 HTML 顺序一致;空单元格使用统一占位;特殊符号规范化 |
| 空单元格 | [EMPTY_CELL] 或等价空位标记 |
保留结构有效但文本为空的位置 | 不因文本为空被过滤;bbox 仍存在;参与结构评测 |
| 空间边界框 | cells[i].bbox=[x1,y1,x2,y2] |
约束视觉区域和结构节点对齐 | 坐标不越界;面积为正;同一行列近似对齐;与单元格数一一对应 |
| 数据切分 | split、版本号、来源域 |
支持训练、验证和评测复现 | 训练/测试不交叉;压力集与标准集关系清楚;版本可追踪 |
这套 schema 的价值在于,它让同一份数据可以服务多种训练和评测目标。若模型是纯生成式 VLM,可以使用图像到 HTML 序列的监督;若模型包含位置预测头,可以使用 bbox 回归或离散坐标 token;若研究目标是空单元格恢复,可以专门统计 [EMPTY_CELL] 的召回率、空列保留率和结构编辑距离。数据资产越接近这种“多信号同步”形态,模型实验越容易做错误归因。
需要注意的是,空单元格 token 的具体写法必须在数据、tokenizer、训练脚本和评测脚本之间保持一致。数据集中使用 [EMPTY_CELL] 表达空单元格;在部分模型论文上下文中,也可能出现 [EMPTY CELL] 一类排版写法。工程实现时需要选择一种规范并在数据转换阶段统一,否则同一个空位可能被 tokenizer 切成不同片段,造成训练目标和评测目标不一致。
案例B.4:四阶段构建流水线¶
SparseTable-Bench 的构建可整理为四个阶段:表格收集、结构抽取、空间标注和稀疏拓扑增强。四个阶段之间不是简单串行的文件转换,而是围绕“结构、文本、几何三者一致”反复校验,如图 40-5 所示。
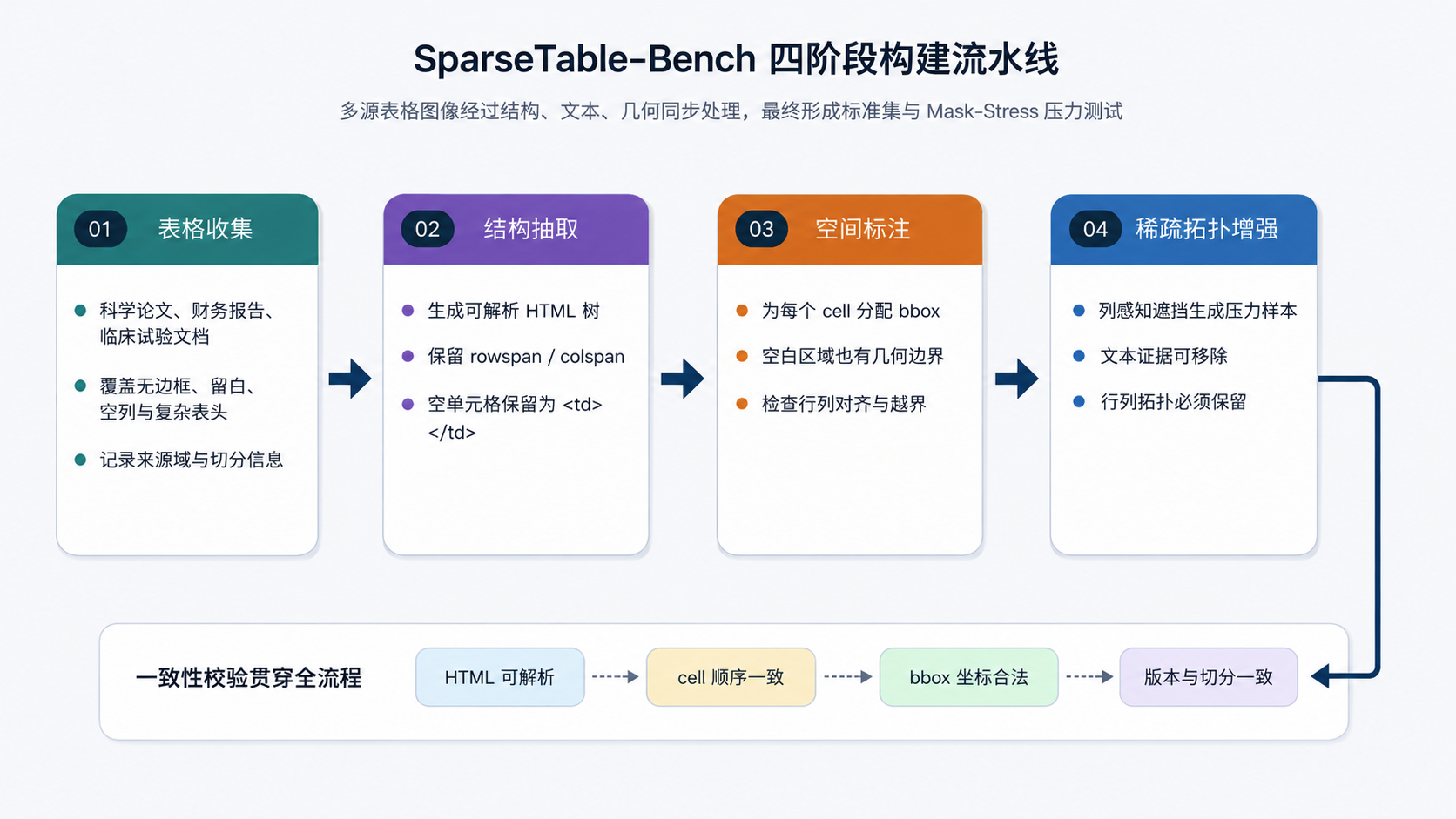
图40-5:SparseTable-Bench 四阶段构建流水线图。
案例B.4.1 表格收集¶
原始表格图像来自科学出版物、财务报告和临床试验文档等多源文档。选择这些来源的原因在于,它们天然包含大量不规则表格:科研论文中常见无边框实验结果表和 meta-analysis 表;财务报告中常见多层表头、空白分组和跨列注释;临床试验文档中常见指标、组别、时间点和空缺观测混合出现的表格。相比模板化票据或固定格式表单,这些表格更能暴露 VLM 对隐式结构的依赖。
采集阶段的关键不是盲目增加图像数量,而是覆盖稀疏结构的多样性。数据工程人员需要关注至少四类样本:边框缺失但行列对齐明显的表格,大面积空白或空列的表格,存在复杂 rowspan/colspan 的表格,以及文本密度在不同区域变化很大的表格。这些样本构成了 STB 区分于普通密集表格数据集的基础。
案例B.4.2 结构抽取¶
结构抽取阶段将表格的逻辑拓扑转换为 HTML 序列。HTML 不是唯一可选格式,但它具有两个优势:一是标签树天然适合表达行、列和单元格层级;二是 TEDS 等主流表格结构指标可以直接在 HTML 树上计算。对于普通单元格,标注应明确其所属行列;对于合并单元格,应保留 rowspan 和 colspan;对于空单元格,应保留对应的 <td> 节点,而不是因为没有文本就删除。
这一阶段最容易出现的错误是“视觉上看起来合理,逻辑网格不可解析”。例如,某一行少标一个空 <td>,人工浏览时可能不明显,但 HTML 树转为矩阵后会导致后续所有列索引左移。因此,结构抽取不能只依赖人工肉眼检查,还应使用解析器把 HTML 还原为网格矩阵,检查每行展开后的列数、合并单元格占用区域、空位数量和单元格顺序。
案例B.4.3 空间标注¶
空间标注为每个单元格分配二维边界框。bbox 不只是辅助可视化字段,它决定了数据集是否能训练和评估几何对齐能力。对于有文字的单元格,bbox 应覆盖单元格区域而不仅是文字区域;对于空单元格,bbox 仍需根据相邻行列边界、表格整体布局和隐式网格推断得到。这样,模型才能学习“没有文字的区域也可能是有效单元格”这一结构先验。
质量检查可以分为几何合法性和拓扑一致性两类。几何合法性包括坐标不越界、宽高为正、bbox 与图像尺寸一致;拓扑一致性包括同一行单元格的纵向范围应大体重叠,同一列单元格的横向范围应大体对齐,合并单元格的 bbox 应覆盖对应的行列区域。对于稀疏表格,拓扑一致性往往比文字 OCR 更重要,因为大量空白区域无法用文本校验。
案例B.4.4 稀疏拓扑增强¶
稀疏拓扑增强阶段用于构造压力测试和补充鲁棒性信号。它不是简单随机遮挡图像,而是基于列、表头、正文和单元格拓扑进行可控 mask。遮挡后,图像中的对应区域被统一背景色覆盖,标注中的文本 token 也同步置空或移除,但单元格节点、行列位置和拓扑关系应继续保留。这样构造出的样本可以减少模型对局部文本线索的依赖,迫使模型利用剩余布局、相邻单元格和结构先验恢复表格。
构建流水线最终应产出三类可复查对象:标准训练/验证/测试样本,STB-Mask-Stress 压力测试样本,以及记录数据版本、来源域、切分策略和转换脚本的数据说明。没有这些元信息,benchmark 很容易变成一次性实验材料,难以支持后续模型迭代和横向对比。
案例B.5:空单元格和稀疏布局如何诱发结构错误¶
稀疏表格的核心难点不是“空白太多所以信息少”这么简单,而是空白本身携带结构意义。空白区域可能代表一个空单元格、一整列缺失值、一个跨行单元格占据的区域,也可能只是页面排版留白。模型若不能区分这些情况,就会出现结构幻觉。
一种典型错误是空列跳过。假设真实表格有三列,中间列大部分为空,模型生成时可能只输出第一列和第三列,把第三列内容移动到第二列位置。文本层面看,主要数值都被识别出来了;结构层面看,列语义已经改变。对于财务报表,这可能把“本期数”解释为“上期数”;对于临床表格,这可能把治疗组指标错放到对照组。
另一种错误是级联错位。表格识别通常按序列自回归生成,前面某个空 <td> 被漏掉后,后续同一行的所有单元格都会左移;如果该错误发生在多层表头,影响还会扩展到多行和多个字段。传统平均分可能只显示分数略降,但实际业务含义已经完全偏移。
这些结构错误会进一步反映到评测结果中。稀疏表格中的空位遗漏、列位左移和空单元格误填会改变 HTML 树中的节点数量、节点顺序和行列展开关系,因此通常会拉低 TEDS 或 TEDS-S 分数。STB 同时保存 HTML、文本和 bbox,就是为了把分数下降对应到可检查的数据对象,而不仅停留在总体指标层面。
可以把稀疏表格中的错误分为五类。
表40-7列出了相关字段与出版复核口径。
表40-7:关键要点与工程复核口径。
| 错误类型 | 表现 | 主要原因 | 在 STB 中的观测方式 |
|---|---|---|---|
| 空位遗漏 | 空 <td> 未生成,列数减少 |
空单元格没有视觉文本锚点 | [EMPTY_CELL] 召回、TEDS-S、行列展开检查 |
| 列位左移/右移 | 非空内容被放入相邻列 | 中间空列被跳过或合并 | HTML 矩阵对齐、bbox 与列索引一致性 |
| 空单元格误填 | 模型在空位生成不存在的文本内容 | 上下文补全或语言先验过强 | [EMPTY_CELL] 精确率、单元格文本检查 |
| 合并关系错误 | rowspan/colspan 漏标或错标 |
稀疏区域边界弱,表头层级复杂 | 结构树编辑、合并区域覆盖检查 |
| 空间漂移 | HTML 结构可解析但 bbox 对不上 | 模型只学序列,缺少几何监督 | cell bbox IoU、行列几何对齐检查 |
这些错误说明,SparseTable-Bench 的价值不只是提供难度更高的数据集,而是把稀疏表格中的结构失败模式转化为可标注、可计算、可归因的监督对象。
案例B.6:STB-Mask-Stress:面向信息缺失的压力测试¶
STB-Mask-Stress 是 SparseTable-Bench 中专门用于鲁棒性评估的压力测试切分。它的设计思想是:在保留表格拓扑的前提下,系统性减少文本线索,观察模型是否还能恢复行列结构和空单元格位置。与普通数据增强不同,STB-Mask-Stress 的目标不是提升训练集多样性,而是构造一个更接近“结构理解压力测试”的评测环境。本章沿用数据集说明中的 STB-Mask-Stress 命名;在相关实验语境中,它也可理解为面向列级遮挡的 masked table evaluation setting,并可与 Masked-TEDS 等压力测试指标配合使用。
图 40-6 展示了 STB-Mask-Stress 从列级遮挡生成到评测解释的基本流程。
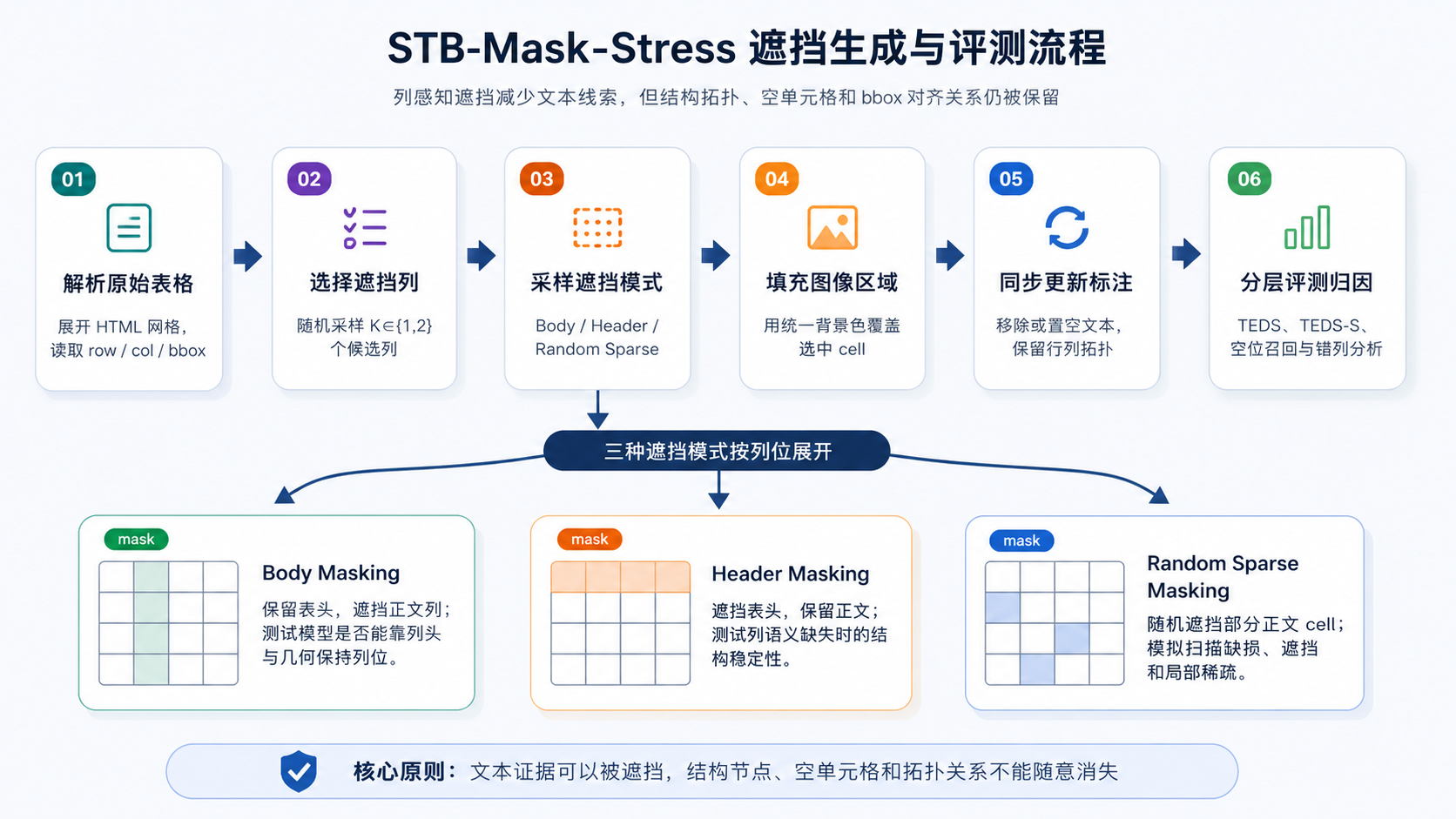
图40-6:STB-Mask-Stress 遮挡生成与评测流程图。
STB-Mask-Stress 的遮挡策略是列感知的。流程可以概括如下。
- 解析原始表格结构,得到每个单元格的行列索引、表头/正文归属和 bbox。
- 随机选择若干列作为遮挡候选。
- 对每个选中列采样遮挡模式。若采样概率落在 body masking 区间,则遮挡该列正文单元格并保留表头;若落在 header masking 区间,则遮挡表头单元格并保留正文;否则随机遮挡部分正文单元格,制造间歇性空白。
- 将图像中被选中单元格区域填充为统一背景色。
- 同步更新标注:被遮挡区域的文本 token 从目标中移除或置空,但行列拓扑仍保留。
- 用更新后的样本计算 TEDS、TEDS-S 或 masked 版本的结构指标,并进行错误归因。
三种遮挡模式分别考察不同能力。Body Masking 保留表头但删除正文内容,检验模型能否根据列头和几何结构维持列位;Header Masking 删除表头,检验模型在列语义缺失时能否保持正文对齐;Random Sparse Masking 生成局部断裂和间歇空白,更接近真实扫描、遮挡或渲染缺损造成的稀疏条件。
需要强调的是,STB-Mask-Stress 的分数不应直接等同于普通测试集泛化分数。标准测试集衡量模型在自然表格上的整体识别能力,压力测试衡量模型在信息缺失和视觉稀疏条件下的结构恢复能力。一个模型在标准测试上 TEDS 很高,但在 STB-Mask-Stress 上 TEDS-S 明显下降,说明它可能依赖可见文本锚点,而没有稳定学习行列拓扑。反过来,一个模型在压力测试上结构分数较稳,但文本分数下降,也可能说明它保持了拓扑但无法恢复被遮挡内容,这属于不同类型的能力边界。
从数据工程角度看,压力测试的关键是“遮挡与标注同步”。如果只遮挡图像而不更新标签,模型会被要求预测不可见文本,评测结果会混入语言记忆和猜测能力;如果删除文本时也删除单元格节点,压力测试又会退化为普通稀疏表格,无法检查空位保留。因此,STB-Mask-Stress 应始终保持这样一个原则:文本证据可以被移除,结构拓扑不能随意消失。
案例B.7:评测协议:TEDS、TEDS-S 与错误解释¶
SparseTable-Bench 采用 Tree-Edit-Distance-based Similarity(TEDS)及其结构变体 TEDS-S 作为主要评测指标。TEDS 将预测 HTML 和参考 HTML 解析为树,计算归一化树编辑相似度;它同时受到结构标签、节点顺序和单元格文本的影响。TEDS-S 则忽略文本内容,更关注结构拓扑,例如行列对齐、合并单元格恢复和空单元格位置。
这两个指标适合做模型横向比较,但不能被机械解释。尤其是在 STB 这类稀疏表格数据集中,指标差异往往对应不同错误来源。
在极度稀疏或空单元格密集的表格中,TEDS/TEDS-S 的下降通常源于模型结构预测错误。大量空位削弱了可见文本锚点,模型可能把不存在的内容补入空单元格,跳过空列,或将相邻列内容归入错误列位;一旦这类错误进入 HTML 输出,<td> 节点数量、节点顺序和行列展开关系都会发生变化,最终表现为 TEDS 或 TEDS-S 降低。TEDS-S 进一步聚焦结构拓扑和空单元格位置,因此更容易暴露这类行列对齐错误。
表40-8列出了相关字段与出版复核口径。
表40-8:指标、计算方式与解释。
| 指标现象 | 可能解释 | 不宜直接得出的结论 | 补充检查 |
|---|---|---|---|
| TEDS 高,TEDS-S 高 | 结构和文本整体较稳定 | 不能说明 bbox 一定正确 | cell bbox IoU、行列几何对齐 |
| TEDS 低,TEDS-S 高 | 结构基本正确但文本内容错误 | 不能说明模型结构识别差 | OCR/text normalization、数字格式 |
| TEDS-S 低,TEDS 接近或略高 | 部分文本正确但结构错位 | 不能只看文本命中率 | 空单元格召回、列位偏移检查 |
| 标准集高,Mask-Stress 低 | 依赖可见文本锚点,抗稀疏能力弱 | 不能说明模型在普通场景不可用 | 分遮挡模式统计 body/header/random |
| Mask-Stress 中 TEDS-S 高但 TEDS 低 | 拓扑保留较好,被遮挡文本不可恢复 | 不能要求模型凭空恢复不可见内容 | 确认遮挡文本是否从目标同步移除 |
在 STB 中解释 TEDS/TEDS-S 时,需要同时关注三类信息。
第一,TEDS 是结构和文本的混合指标。它适合衡量最终 HTML 输出是否接近参考答案,但当分数下降时,需要拆分看是文本误识别、标签树错误,还是单元格顺序错位。对稀疏表格而言,同样的 TEDS 降幅可能代表完全不同的风险。
第二,TEDS-S 是结构指标,但不是几何指标。它忽略文本后能更清楚地反映行列拓扑,但它仍然基于 HTML 树,不直接验证 bbox 与图像位置是否匹配。如果模型输出的 HTML 拓扑正确,但把 cell bbox 放到错误视觉区域,TEDS-S 不会充分惩罚。因此,对于使用 STB 的几何感知模型,还应增加 bbox IoU、中心点距离、行列对齐误差或 cell-to-region assignment 等检查。
第三,压力测试分数需要按遮挡类型分层报告。Body Masking、Header Masking 和 Random Sparse Masking 所考察的能力不同。如果只报告一个平均分,可能掩盖模型在表头缺失时崩溃、在正文遮挡时稳定、在随机稀疏时漂移等差异。数据工程实践中通常同时给出整体分数、分 mask 类型分数和典型失败案例。
除了主指标,STB 还适合引入若干诊断性指标。例如,空单元格召回率可以衡量 [EMPTY_CELL] 是否被保留;列数展开一致率可以衡量每一行展开后是否与参考列数一致;合并单元格准确率可以衡量 rowspan/colspan;bbox 匹配率可以衡量结构节点与视觉区域是否对应。这些指标不一定都进入排行榜,但适合用于模型调试和数据质检。
案例B.8:数据工程实践:如何使用 STB 训练和复现¶
将 SparseTable-Bench 用于模型训练时,最常见的做法是把图像作为输入,把 HTML 结构、单元格文本和 bbox 组织成统一输出序列或多任务监督目标。对于生成式 VLM,可以让模型直接生成 HTML,并在单元格内容位置插入文本或空单元格 token;对于带位置头的模型,可以在文本生成之外增加 bbox 回归或坐标 token 预测;对于 adapter 或结构先验模型,可以把 bbox 和网格拓扑转换为辅助结构特征,帮助解码器在生成时保留行列对齐。
实践中有几条容易被忽略的约束。
首先,数据转换必须保持样本顺序一致。HTML 中第 i 个单元格、cells[i].text 和 cells[i].bbox 应指向同一逻辑单元格。如果转换脚本在过滤空文本、展开合并单元格或排序 bbox 时改变了顺序,训练目标会变成噪声。
其次,空单元格不能在清洗阶段被删除。许多通用文档清洗脚本会把空字符串、空标签和空 bbox 当作无效字段过滤掉;在 STB 中,这正是需要保留的核心监督信号。因此,清洗规则应区分“无效缺失”和“有效空单元格”。
第三,bbox 坐标需要明确坐标系。不同模型可能使用原图像素坐标、归一化坐标或离散 token 坐标。转换时应记录图像宽高、缩放比例和 padding 策略,避免训练和评测使用不同坐标系。
第四,标准测试和压力测试要分开报告。若把 STB-Mask-Stress 混入普通测试均值,审阅者很难判断模型到底是自然场景泛化不足,还是极端稀疏场景鲁棒性不足。更清晰的报告方式是:先给出 Standard-Test 的 TEDS/TEDS-S,再给出 Mask-Stress 的 TEDS/TEDS-S,并按遮挡类型拆分。
第五,错误案例应回到数据对象。一次失败可以被拆成几个问题:HTML 是否可解析,行列展开是否一致,空单元格是否漏掉,文本是否错读,bbox 是否偏移。只有这样,模型修复动作才明确:是需要更多空单元格样本、改进位置监督、修正 tokenizer,还是重新校验标注。
为了让实验具有可复现性,STB 的使用不宜只停留在“加载数据、训练模型、报告分数”的粗粒度流程上。更稳妥的做法是把一次实验拆成四个可检查阶段。第一阶段是数据读取检查:随机抽取训练、验证、标准测试和压力测试样本,确认图像、HTML、cell 列表和 bbox 都能被同一个样本 ID 关联起来。第二阶段是 schema 渲染检查:将 HTML 展开为二维网格,并把 bbox 叠加回原图,确认空单元格、合并单元格和非空文本在视觉上可解释。第三阶段是模型输入输出检查:明确模型看到的是原图、裁剪图还是带 patch 的图像,输出的是纯 HTML、HTML 加坐标 token,还是 HTML 与 bbox 多任务结果。第四阶段是评测和归因检查:先分别计算 Standard-Test 和 STB-Mask-Stress,再按空位遗漏、列位偏移、文本错误和空间漂移四类错误抽样复核。
表40-9列出了相关字段与出版复核口径。
表40-9:关键要点与工程复核口径。
| 复现环节 | 输入对象 | 输出对象 | 关键检查 |
|---|---|---|---|
| 数据读取 | 图像、HTML、cells、bbox | 统一样本记录 | ID 对齐、字段完整、切分正确 |
| schema 渲染 | HTML 树、cell 列表 | 二维网格与可视化叠加图 | 空单元格保留、合并关系可解析、bbox 不越界 |
| 模型训练 | 表格图像与多任务标签 | HTML 序列、文本 token、bbox 预测 | [EMPTY_CELL] 词表一致、坐标系一致、loss mask 合理 |
| 评测归因 | 预测结果与参考标注 | TEDS、TEDS-S、诊断性错误表 | 标准集/压力集分开报告,错误能回到数据字段 |
对于 VLM 或文档模型训练,STB 可以承担两种不同角色。作为训练数据时,它提供的是结构化视觉监督,适合帮助模型学习“视觉区域到逻辑单元格”的对齐关系;作为评测数据时,它更适合作为鲁棒性切片,用来检验模型是否只是依赖文本密度和局部 OCR 线索。若一个通用 VLM 在自然图片问答上表现良好,但在 STB-Mask-Stress 上无法保留空列,就说明它的文档结构能力仍需要专门数据补强。若一个文档模型在标准测试上结构分数很高,却在 bbox 复核中出现大量空间漂移,则说明模型可能学会了 HTML 语言模式,但没有真正建立几何对齐能力。
因此,在课程实验或项目实战中,STB 的结果报告通常可以拆成“可用性”和“鲁棒性”两层。可用性层关注标准测试集上的表格结构恢复质量,回答模型是否能够处理常规科学、财务和临床表格;鲁棒性层关注压力测试中的空单元格、遮挡列和局部稀疏区域,回答模型在证据缺失时是否还能维持可信结构。这种分层报告方式比单一排行榜分数更适合数据工程复盘,也更便于把失败样本回流到清洗、标注和再训练流程中。
在团队协作中,还应把 STB 从“实验数据”提升为“可交付数据资产”。一个可交付版本至少应包含三类记录。第一类是数据卡,记录数据来源、许可状态、样本规模、切分方式、字段 schema、空单元格约定和 bbox 坐标系;第二类是评测卡,记录使用的模型、输入分辨率、解码参数、TEDS/TEDS-S 计算脚本版本、是否启用 OCR 后处理以及 Mask-Stress 的遮挡策略;第三类是错误卡,记录典型失败样本、错误类型、是否由标注引起、是否由模型输出引起,以及下一轮修复动作。没有这些记录,即使分数可复现,失败原因也很难复查。
尤其是空单元格相关错误,不能只在最终报告中给出几个案例截图。更好的做法是把它们沉淀为可查询的错误切片,例如“整列为空但列头可见”“表头为空但正文密集”“空白区域跨越多行”“空单元格位于合并单元格旁边”等。每个切片都可以单独统计 TEDS-S、空单元格召回率和列展开一致率。这样,当某个模型版本在平均分上提升但在空列切片上下降时,数据团队能够及时发现鲁棒性回退,而不是等到业务侧出现错列解释后再排查。
标注质检也可以采用双通道检查。第一条通道检查结构:HTML 是否能稳定解析为二维矩阵,展开后的行列数是否一致,rowspan 和 colspan 是否造成重叠或空洞。第二条通道检查几何:bbox 是否越界、是否覆盖单元格区域、同一列的横向范围是否连续、空单元格 bbox 是否与相邻单元格共同形成合理网格。只有结构和几何同时通过,样本才适合进入训练集;如果只有文本正确但结构或 bbox 有疑点,应进入返修队列,而不是直接作为监督信号使用。
一个可复现的 benchmark 版本需要固定训练集、验证集、标准测试集和 STB-Mask-Stress 的版本号,并保留数据生成脚本的哈希值。压力测试尤其需要版本化,因为遮挡列数、遮挡概率和背景填充值的细小变化都会影响模型分数。若未来调整遮挡策略,应作为新的压力测试版本发布,而不是覆盖旧结果。这样,STB 才能支持长期模型迭代、跨团队比较和书中项目复现实验。
案例B.9:MindSpore 实现与代码¶
为了便于复现实验和复查数据处理流程,SparseTable-Bench 的 MindSpore 配套实现入口如下:
champiom666/SparseTable-Bench-MindSpore
该仓库作为本章配套实现入口,用于组织数据读取、遮挡构造和评测复现实验。一个完整的配套实现通常应包含以下内容:STB 数据读取器、HTML 与 cell schema 转换脚本、[EMPTY_CELL] token 规范化、bbox 坐标转换、STB-Mask-Stress 生成脚本、TEDS/TEDS-S 评测脚本,以及用于 MindSpore 训练的最小示例配置。这样,书中章节、数据集说明和代码仓库之间才能形成闭环。
除 GitHub 代码入口外,数据集公开地址应与代码仓库在 README 中互相引用:
https://huggingface.co/datasets/champion666/SparseTable_Bench_Dataset
需要注意,代码仓库的作用不是简单复刻论文实验,而是支持本章描述的数据工程流程复现:读取样本、验证 schema、构造遮挡、运行评测并解释错误。只要这些接口稳定,后续无论替换为 SA-Table、OCRFlux、Qwen-VL 或其他表格识别模型,都能在同一数据协议下比较。
案例B.10:与前后章节的连接¶
SparseTable-Bench 可以自然连接本书多个部分。
与第三篇的文档理解和跨模态对齐相关,STB 提供了一个比普通 OCR 更严格的例子:视觉区域、文字内容和结构 token 必须同时对齐。第9章讨论的 OCR 与文档结构重标注,在这里具体体现为 cell-level 文本、bbox 和 HTML 的同步;第11章讨论的跨模态对齐,在这里具体体现为表格图像区域与逻辑单元格节点的对齐。因此,本章可以被看作从“页面文本识别”进一步走向“结构化视觉对象恢复”的专项案例。
与第40章的票据文档理解相比,StructBill-CN 更强调业务 schema、字段抽取和逻辑一致性,SparseTable-Bench 更强调表格内部拓扑、空单元格和稀疏布局。两者都属于视觉文档数据工程,但一个面向高风险票据字段,一个面向通用表格结构鲁棒性。
与第41章的多图表信息图推理相比,STB 关注的是单个表格对象内部的结构恢复,而多图表信息图推理关注跨图表证据聚合和多步计算。前者为后者提供了基础能力:如果模型连表格内部列位都无法稳定恢复,跨图表推理中的数值读取和证据定位就会失去可靠基础。
向后看,STB 直接连接第47章的 VLM 数据配方。第47章关注多模态训练数据如何组织图像、文本、坐标和指令信号,而 STB 正好提供了一个结构化视觉监督样例:输入是表格图像,输出同时包含 HTML 结构、单元格文本、bbox 和空单元格占位。它可以作为 VLM 数据配方中的文档表格切片,用来说明为什么通用图文对不足以训练稳定的表格结构能力。
在第十四篇项目中,STB 也可以连接 P03 和 P05。P03 的 LLaVA 多模态指令数据工厂需要把文档图像转成可训练的视觉指令样本,STB 可以提供“识别表格结构”“指出空单元格位置”“解释列位偏移错误”等指令来源。P05 的多模态 RAG 项目需要从 PDF、财报和科研报告中抽取可检索证据,STB 则能帮助把表格解析为可引用、可比对、可追踪的结构化证据。特别是在财报、医学论文和科研报告场景中,表格结构错误往往比单个 OCR 错字更难发现,也更容易影响最终回答。
案例B:小结¶
SparseTable-Bench 的核心贡献在于,它把稀疏表格中的结构鲁棒性问题转化为可标注、可训练、可评测的数据工程问题。数据集通过 HTML 结构序列、单元格级文本内容和细粒度 bbox 建立三类监督信号,并用 [EMPTY_CELL] 显式保留空单元格拓扑,避免空白区域在清洗、训练和评测中被错误删除。STB-Mask-Stress 进一步通过列感知遮挡构造压力测试,使模型在严重信息缺失下的结构恢复能力可以被单独观察。
使用该数据集时,不能只看一个总体 TEDS 分数。TEDS、TEDS-S、bbox 检查、空单元格召回和分 mask 类型错误分析应结合使用,才能区分文本错误、结构错误和空间错误。STB 的价值不是简单提供一个“更难”的表格数据集,而是把稀疏表格里的失败模式变成可标注、可训练、可评测的对象。对于大模型数据工程而言,STB 的启示是:复杂文档数据集的价值不只来自样本规模,更来自是否把真实失败模式编码进 schema、构建流程和评测协议中。
本章小结¶
本章将票据文档理解与稀疏表格结构恢复放在同一类视觉文档数据工程问题中讨论。前者强调业务字段、版式证据和逻辑一致性,后者强调表格拓扑、空单元格、遮挡鲁棒性和结构化评测。二者共同说明,视觉文档数据集不能只停留在图文配对或 OCR 文本层面,而需要把字段 schema、空间定位、结构约束、失败模式和质量审计共同纳入数据工程设计。
对后续多模态模型训练而言,本章的核心启示是:文档类数据的出版级与生产级价值,取决于其是否能稳定表达“图像区域—文本内容—结构对象—业务语义”之间的可追踪关系。只有当这些关系被清晰编码,数据集才能支撑可复现训练、可解释评测和面向真实场景的持续改进。
参考文献¶
Bai S, Chen K, Liu X, et al. (2025) Qwen2.5-VL Technical Report. arXiv preprint arXiv:2502.13923.
Blecher L, Cucurull G, Scialom T, Stojnic R (2023) Nougat: Neural Optical Understanding for Academic Documents. arXiv preprint arXiv:2308.13418.
Huang Y, Lv T, Cui L, Lu Y, Wei F (2022) LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking. Proc. ACM Multimedia.
Huang Z, Chen K, He J, Bai X, Karatzas D, Lu S, Jawahar CV (2019) ICDAR2019 Competition on Scanned Receipt OCR and Information Extraction. Proc. ICDAR, pp. 1516–1520.
Hu EJ, Shen Y, Wallis P, Allen-Zhu Z, Li Y, Wang S, Wang L, Chen W (2021) LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685.
Jaume G, Ekenel HK, Thiran J-P (2019) FUNSD: A Dataset for Form Understanding in Noisy Scanned Documents. ICDAR Workshop.
Kuhn HW (1955) The Hungarian Method for the Assignment Problem. Naval Research Logistics Quarterly, 2(1–2), pp. 83–97. https://doi.org/10.1002/nav.3800020109.
Levenshtein VI (1965) Binary Codes Capable of Correcting Deletions, Insertions and Reversals. Soviet Physics Doklady, 10, pp. 707–710.
Liu H, Xue W, Chen Y, et al. (2024) A Survey on Hallucination in Large Vision-Language Models. arXiv preprint arXiv:2402.00253.
Mathew M, Karatzas D, Jawahar CV (2021) DocVQA: A Dataset for VQA on Document Images. Proc. WACV. https://doi.org/10.1109/wacv48630.2021.00225.
Niu J, Liu Z, Gu Z, et al. (2025) MinerU 2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing. arXiv preprint.
Park S, Shin S, Lee B, et al. (2019) CORD: A Consolidated Receipt Dataset for Post-OCR Parsing. NeurIPS Workshop on Document Intelligence.
Rafailov R, Sharma A, Mitchell E, Ermon S, Manning CD, Finn C (2024) Direct Preference Optimization: Your Language Model Is Secretly a Reward Model. Proc. NeurIPS. arXiv:2305.18290.
Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O (2017) Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347.
Shao Z, Wang P, et al. (2024) DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv preprint arXiv:2402.03300.
Tianchi A, CHIP Committee (2022) CHIP 2022 Shared Task: Medical Invoice OCR Element Extraction Dataset. Aliyun Tianchi Platform.
Xu Y, Li M, Cui L, Huang S, Wei F, Zhou M (2020) LayoutLM: Pre-training of Text and Layout for Document Image Understanding. Proc. ACM SIGKDD, pp. 1192–1200.
Xue W, Yu B, Wang W, Tao D, Li Q (2021) TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition. arXiv preprint arXiv:2106.10598.
Yang Z, Long R, Wang P, et al. (2023) Modeling Entities as Semantic Points for Visual Information Extraction in the Wild. Proc. CVPR.
Zhang N, Chen M, Bi Z, et al. (2022) CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark. Proc. ACL, pp. 7888–7915. https://doi.org/10.18653/v1/2022.acl-long.544.
Zhong X, ShafieiBavani E, Jimeno Yepes A (2020) Image-based Table Recognition: Data, Model, and Evaluation. arXiv preprint arXiv:1911.10683.
Bai S, Cai Y, Chen R, et al. (2025a) Qwen3-VL Technical Report. arXiv preprint.
ChatDOC (2025). OCRFlux-3B: A Multimodal Large Language Model for Document Parsing. Hugging Face Model Card.
Cui C, Sun T, Liang S, et al. (2025) PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model. arXiv preprint.
Guo D, Yang D, Zhang H, et al. (2025) DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948.
Hunyuan Vision Team (2025). HunyuanOCR Technical Report. arXiv preprint.
Li Y, Yang G, Liu H, Wang B, Zhang C (2025a) Dots.OCR: Multilingual Document Layout Parsing in a Single Vision-Language Model. arXiv preprint.
Poznanski J, Soldaini L, Lo K (2025) olmOCR 2: Unit Test Rewards for Document OCR. arXiv preprint arXiv:2510.19817.
Smock B, Faucon-Morin V, Sokolov M, et al. (2025) PubTables-v2: A New Large-Scale Dataset for Full-Page and Multi-Page Table Extraction. arXiv preprint arXiv:2512.10888.
Wang W, Gao Z, Gu L, et al. (2025) InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency. arXiv preprint arXiv:2508.18265.
Zhang J, Liu Y, Wu Z, et al. (2025) MonkeyOCR v1.5 Technical Report: Unlocking Robust Document Parsing for Complex Patterns. arXiv preprint.
Smock B, Pesala R, Abraham R (2022) PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents. Proc. CVPR. https://doi.org/10.1109/cvpr52688.2022.00459.
Zhu F, Lei W, Huang Y, Wang C, Zhang S, Lv J, Feng F, Chua T-S (2021) TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance. Proc. ACL. https://doi.org/10.18653/v1/2021.acl-long.254.
Pandas Development Team (2026) pandas Documentation. https://pandas.pydata.org/docs/.
Apache Arrow Contributors (2026) Apache Arrow Documentation. https://arrow.apache.org/docs/.