项目八:企业级 DataOps 平台搭建:从数据项目到组织级治理能力¶
本章概览¶
P08 聚焦把分散的数据工程动作组织成可治理、可追踪、可回滚、可评估的 DataOps 平台能力。章节重点不在单个控制台页面,而在对象建模、版本治理、实验追踪、血缘回滚和可观测闭环之间的系统化关系。
本章可以按四条主线理解:
- 对象模型与平台规格:明确租户、项目、角色、API 与权限边界。
- 版本治理与实验追踪:管理版本演进、实验记录、发布状态和回滚路径。
- 血缘关系与运营可观测:把指标、日志、告警、审计和事故复盘接入平台主链。
- 检查验收与组织交付:通过检查脚本和交付物验证平台的一致性与可扩展性。
如果按工程顺序阅读,本章对应的是一条完整链路:
对象建模 -> 平台规格 -> 版本治理 -> 实验追踪 -> 血缘与回滚 -> 可观测与审计 -> 检查验收 -> 组织交付
这一结构对应的核心目标,是把数据项目中的分散动作沉淀为可持续运行的组织级 DataOps 平台原型。
1. 项目背景:DataOps 平台的必要性¶
在小规模项目里,团队经常依靠少数成员的经验和默契协作完成整个流程。
一个人写清洗脚本,一个人整理样本,一个人配置评测,一个人查看结果,最后再由项目负责人汇总汇报。
只要项目短、团队小、版本少,这种方式往往可以运行。
但只要项目开始进入常态化迭代,这种方式就会迅速失效。
最常见的问题通常有三类。
第一类是版本失控。
数据版本、实验参数、提示词配置、评测集口径、报告结论往往分散在不同目录和不同成员手里。
当结果发生变化时,团队能看到“变化”,却看不到“变化是如何发生的”。
没有统一版本治理,结果就无法被可靠解释,更无法被可靠回滚。
第二类是责任失焦。
当一次实验效果下降时,算法工程师可能认为是数据问题,数据团队可能认为是标注问题,标注团队可能认为是评测口径变化,平台团队则可能认为是调度异常。
如果平台没有统一的血缘和审计链路,复盘就会变成“人人都有局部证据,但没人能还原全局”。
第三类是运营失明。
很多团队有作业调度系统,却没有真正的平台可观测能力。
作业可能运行成功,但输出数据已经异常;
指标可能产生波动,但异常没有关联到具体版本;
告警可能被触发,但没有结构化的 incident review 与修复闭环。
所以,P08 的价值,不在于“做出一个平台概念图”,而在于它把企业级 DataOps 最关键的治理对象组织成了一个原型系统:
角色权限、平台架构、数据版本、实验血缘、回滚事件、SLA、告警、审计和事故复盘。
2. 项目目标与边界¶
2.1 项目目标¶
P08 的目标可以概括为四点。
目标一:建立统一的平台规格层。
先定义平台范围、核心架构、API、队列、治理策略和操作模型,让平台从一开始就不是零散脚本的集合,而是有对象、有边界、有结构的系统。
目标二:建立可追踪的数据版本与实验链路。
平台不仅要知道有哪些数据版本,还要知道这些版本被谁使用、被哪些实验引用、哪些实验产生了回归、哪些版本最终进入发布。
目标三:建立可观测与可复盘能力。
平台不只记录“实验跑完了没有”,而是进一步记录告警、SLA、恢复时长、rollback 和 incident review,让失败路径成为平台的一部分。
目标四:建立可检查的交付闭环。
项目不仅输出规格、模拟运行结果和指标文件,还输出检查脚本与测试报告,让代码、产物和文档相互对齐。现有项目共有 13 项检查,已全部通过。
2.2 项目边界¶
P08 也明确设置了边界。
第一,它是一个平台原型,不是生产级控制平面。
第二,它重点放在规格设计、模拟运行、指标计算和治理机制,而不是复杂交互式 UI。
第三,README 中提到的 render_p8_chapter.py 当前缺失,这一不一致点被显式保留,而不是被掩盖。
2.3 边界说明的作用¶
平台类项目最容易被写成两种失真的样子:
- 一种是“什么都能做”的万能平台;
- 另一种是“只能演示”的概念工程。
更可信的写法是第三种:
在什么边界下,这个原型已经把哪些关键治理能力结构化实现了。
3. 项目定位:P08 的能力链位置¶
如果把整条数据工程能力链看成一个持续运转的系统,那么 P08 所在的位置并不在数据采集、清洗或标注本身,而在更靠后的平台化阶段。
它解决的问题不是“怎么做一个数据集”,而是:
当前面的数据项目、评测项目、训练项目和反馈项目越来越多时,团队如何用平台把这些动作统一治理起来?
因此,本章的重点不是解释某个具体脚本,而是展示一个平台视角下的工程问题:
- 如何定义平台对象;
- 如何组织版本与实验关系;
- 如何保留失败路径;
- 如何把观测、审计和复盘变成系统对象;
- 如何让平台产物可检查、可验证、可扩展。
根据任务书,P08 要覆盖版本、调度、质检、监控,以及与组织接口和运营节奏相关的内容。
当前平台已经显式管理租户、项目、角色、API、队列、UI 面板、数据版本、实验、告警、审计与事故复盘。
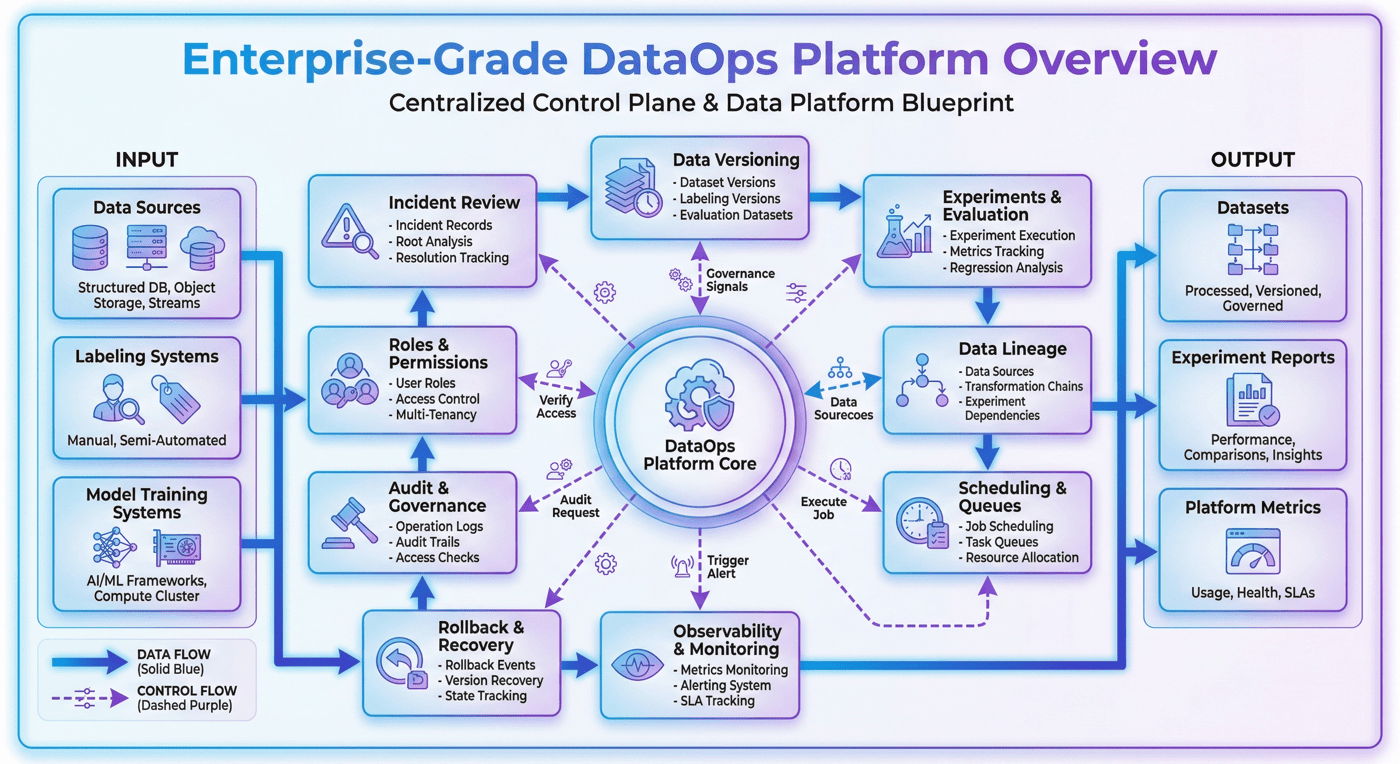
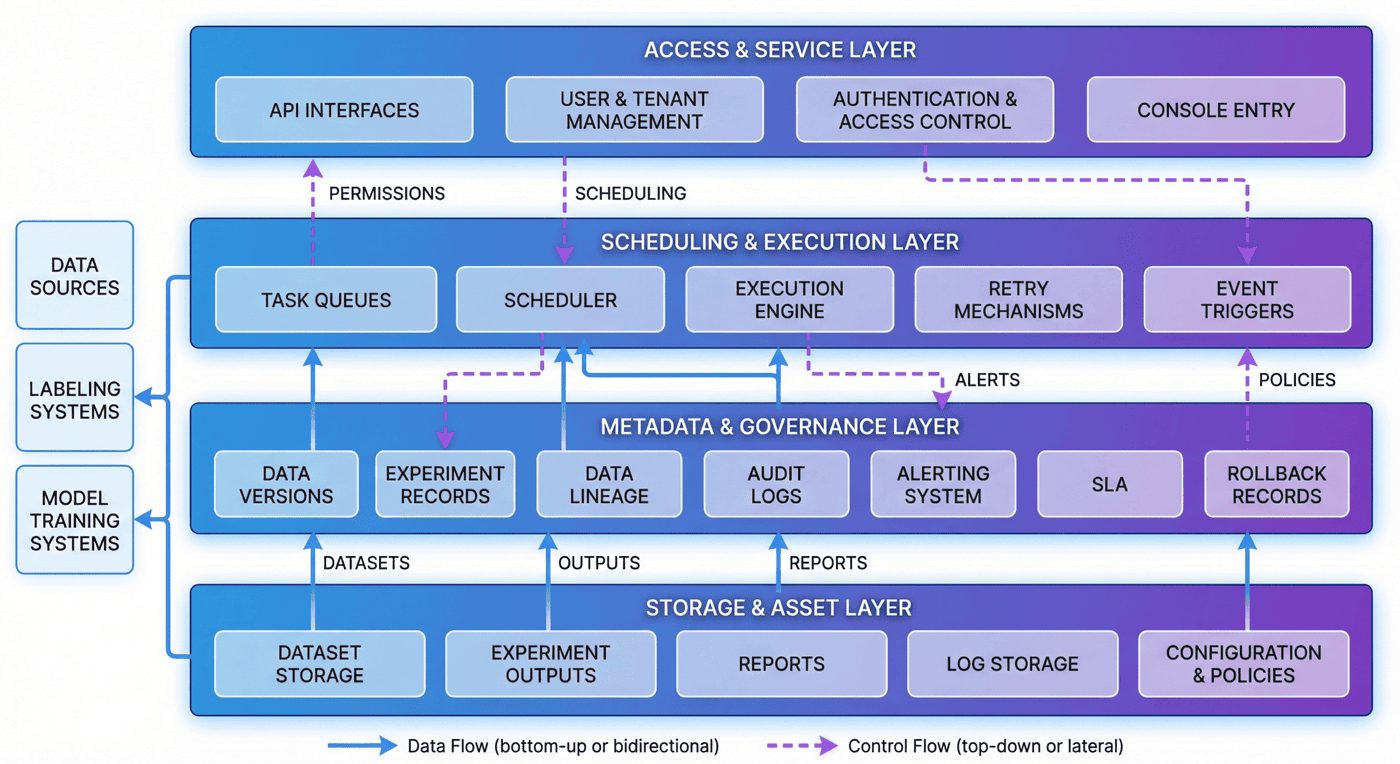
4. 整体架构:DataOps 平台的分层结构¶
当前平台已经包含 4 个核心层、4 个队列和 5 个 UI 面板。
这说明平台原型并不是围绕单一调度器展开,而是按“系统层次 + 运行对象 + 治理视图”来组织。
从工程角度,一个更容易解释的拆法通常是四层。
4.1 接入与服务层¶
这一层承接租户、项目、用户和外部系统的入口。
它通常包括 API 接口、鉴权逻辑、角色校验和控制台入口。
平台不是先有内部逻辑,再临时给一个入口;相反,平台从一开始就要明确“谁以什么身份进入系统”。
4.2 调度与执行层¶
这一层负责把平台上的动作真正落成任务。
包括任务队列、调度规则、执行状态、失败重试和事件触发。
没有这一层,平台只是元数据系统;只有这一层,平台又会退化成普通调度系统。
因此,平台必须把执行能力和治理能力同时纳入。
4.3 元数据与治理层¶
这是 DataOps 平台最核心的一层。
这一层负责记录版本、实验、血缘、审计、告警、SLA、回滚和治理策略。
也正是在这一层,平台和“脚本编排工具”真正拉开差距。
如果没有这层,团队最多只能知道任务有没有跑完;
有了这层,团队才知道任务为什么这样跑、出了问题怎么追、出现回归怎么退。
4.4 存储与资产层¶
这一层承接数据版本、实验结果、评测报告、操作日志、配置文件和运营记录。
它保证平台管理的不是抽象流程,而是真正可复用的数据资产和治理资产。
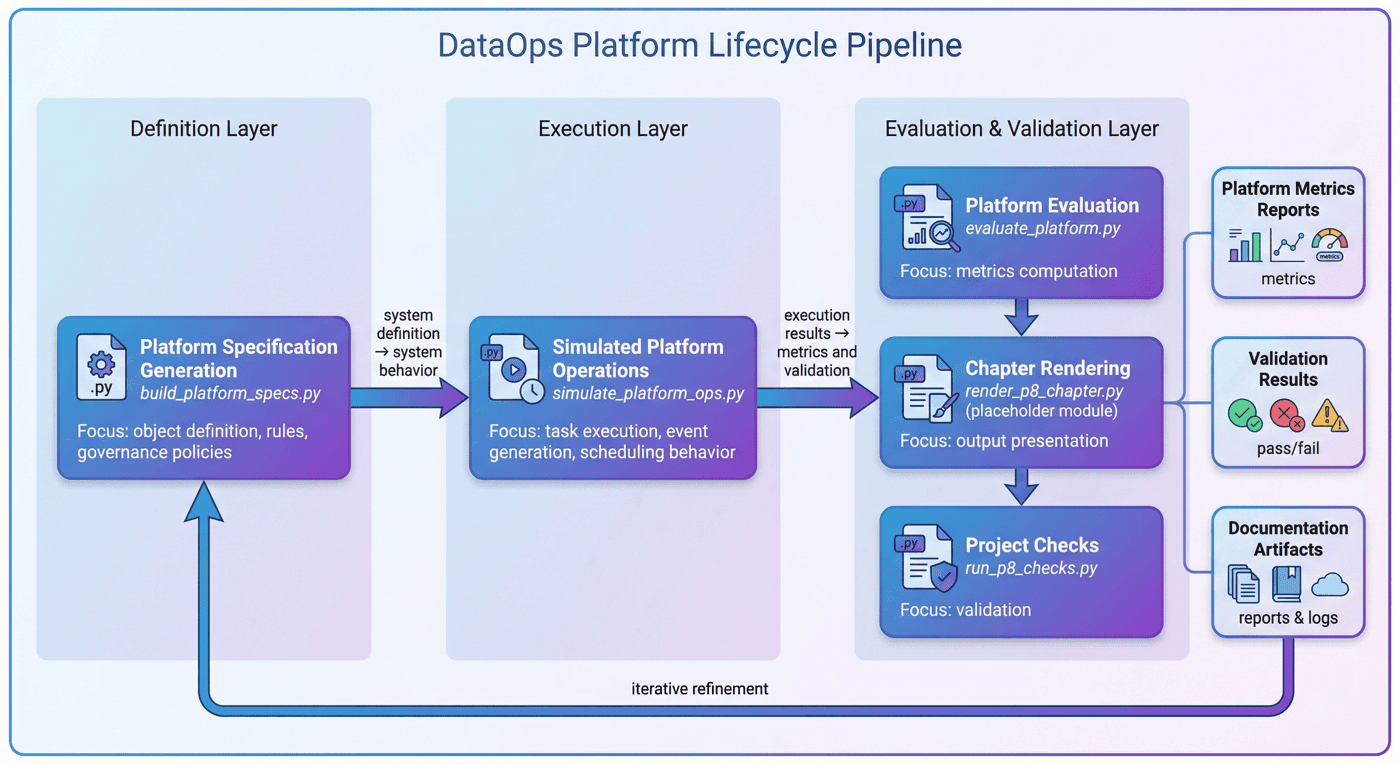
5. 平台流程:规格生成、模拟运行与评估检查¶
现有项目流程是:
src/build_platform_specs.py:生成平台规格与治理设计src/simulate_platform_ops.py:模拟平台运行src/evaluate_platform.py:评估平台指标src/render_p8_chapter.py:渲染章节预览(README 中提到,但当前缺失)src/run_p8_checks.py:项目检查
这个顺序非常重要,因为它体现出平台项目与普通数据脚本项目的区别:
平台首先要定义“系统是什么”,然后才去运行“系统做了什么”,最后再评估“系统运行得怎么样”。
也就是说,P08 不是先写一堆任务逻辑,再回头补说明文档;
而是先建立平台的规格层和治理层,再去模拟平台的运行与运营。
这一点体现了平台建设的一个关键原则:
- 先定义对象与规则;
- 再定义运行与事件;
- 最后定义指标与验收。
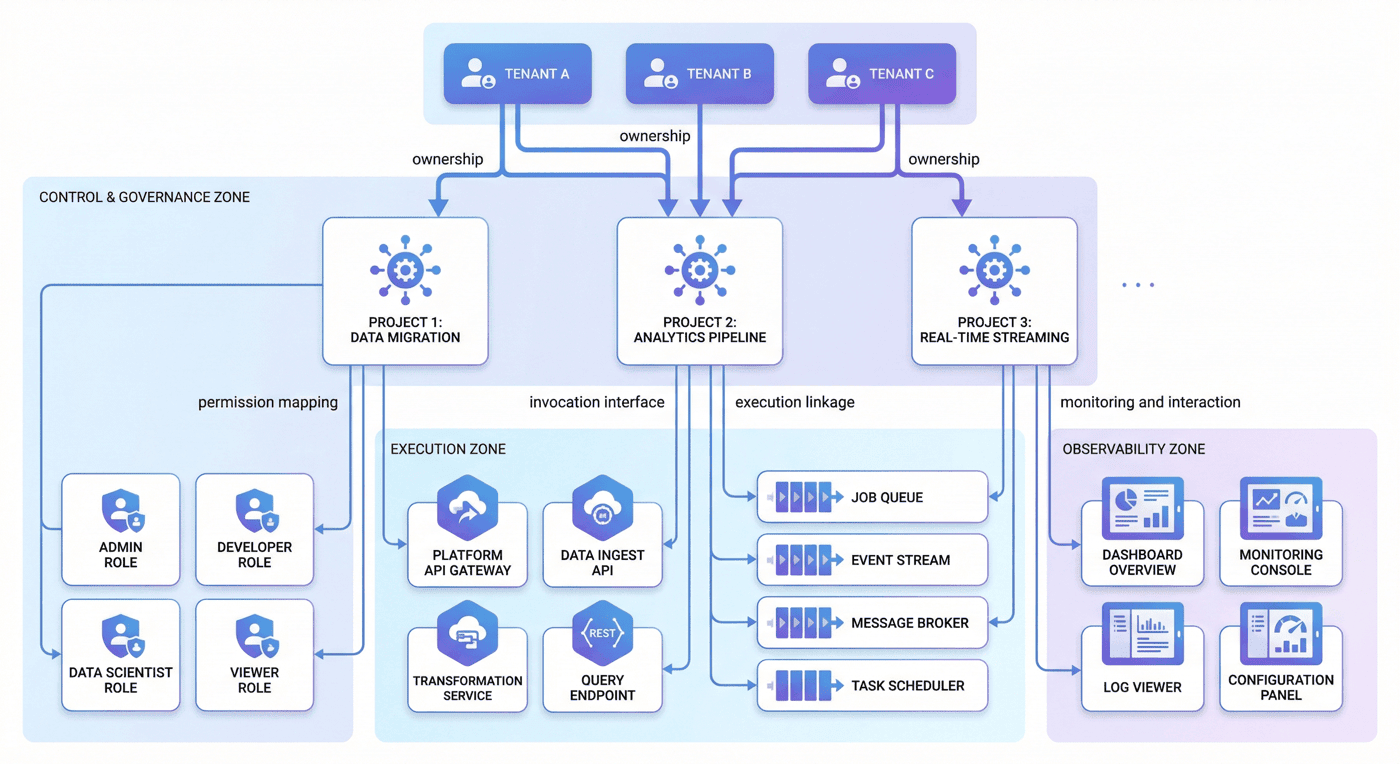
6. 对象建模:平台的关键对象层次¶
平台当前管理的关键对象包括:
- 租户
3 - 项目
3 - 角色
5 - API
6 - 核心层
4 - 队列
4 - UI 面板
5
这组对象关系说明,P08 并不是先从“功能菜单”出发,而是先从“平台对象”出发。
这也是企业级平台与个人脚本系统的重要区别之一。
6.1 租户¶
租户是平台的最上层资源与治理边界。
它不仅决定资源隔离,也决定权限、生效范围、审批链路和治理规则。
一个没有租户概念的平台,很难走向真正的组织级共享使用。
6.2 项目¶
项目是平台的实际工作单元。
数据版本、实验运行、告警事件、交付产物和报表结果都应该能够归属到具体项目。
项目层的存在,保证平台不是一个抽象治理壳,而是能真正承接团队工作的操作空间。
6.3 角色¶
平台当前共有 5 个角色。
角色模型的重要性在于,它把“谁能做什么”从口头协作变成系统能力。
例如:
- 谁可以创建版本;
- 谁可以发布版本;
- 谁可以查看审计日志;
- 谁可以执行回滚;
- 谁负责事故复盘。
在平台项目中,角色不是为了显得“企业级”,而是为了建立最基本的责任边界。
6.4 API、队列与 UI 面板¶
平台有 6 个 API、4 个队列和 5 个 UI 面板。
这三类对象分别代表:
- API:平台能力的程序化入口;
- 队列:平台任务的运行承载体;
- UI 面板:平台治理视图的组织方式。
它们共同说明,P08 并不是只做离线产物,而是在原型层面已经思考了“系统如何被调用、如何被执行、如何被观察”。
7. 代码结合:平台规格如何落成结构化产物¶
P08 的交付物中已经包含:
data/processed/platform_scope.jsondata/processed/architecture_spec.jsondata/processed/api_catalog.jsondata/processed/task_queues.jsondata/processed/governance_policy.jsondata/processed/operating_model.json
这说明平台设计不是停留在文字说明层,而是已经把核心规格落成结构化文件。
对应实现如下,这段结构体现的是平台规格如何被落成结构化产物:
from pathlib import Path
import json
OUTPUT_DIR = Path("data/processed")
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
platform_scope = {
"tenant_count": 3,
"project_count": 3,
"roles": [
"admin",
"platform_pm",
"data_engineer",
"qa",
"ops"
],
"core_layers": 4,
"queues": 4,
"ui_panels": 5
}
with open(OUTPUT_DIR / "platform_scope.json", "w", encoding="utf-8") as f:
json.dump(platform_scope, f, ensure_ascii=False, indent=2)
这段结构体现了平台设计的三个特征:
- 平台对象被显式建模;
- 规格定义先于运行过程;
- 平台能力通过结构化产物被固定下来,而不是在运行结束后再做口头总结。
与单纯展示架构图相比,这种表达方式更接近可落地的平台设计。
8. 版本治理:平台的版本中心¶
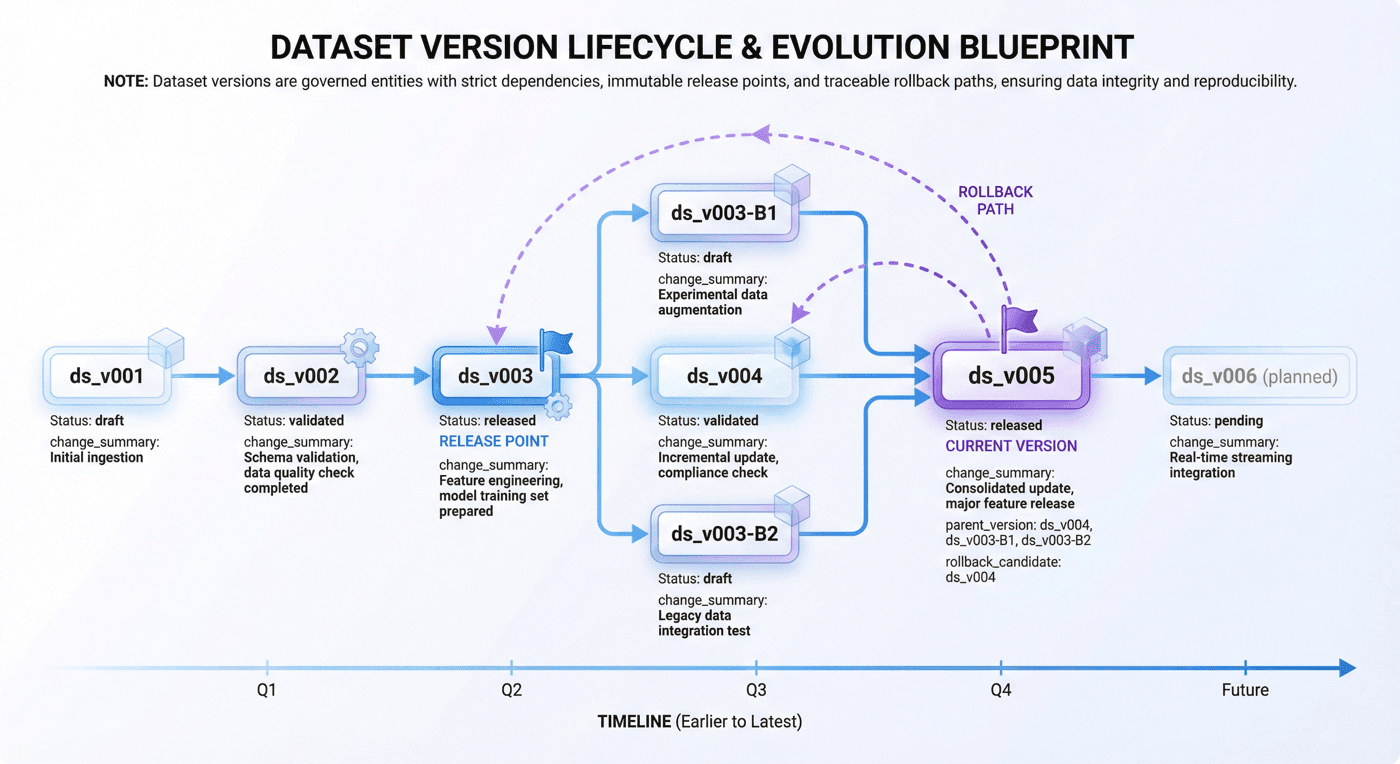
当前平台共管理 6 个数据版本,其中 5 个已发布。 这个规模并不大,但已经足以支撑一个重要论点:
对于 DataOps 平台来说,版本不是一个附属字段,而是整个治理闭环的基础语言。
8.1 版本与可解释性¶
在没有版本治理的平台里,实验结果通常只有“这次跑出来了什么”这个层面的意义。 但真正重要的问题往往是:
- 这次结果依赖的是哪一个数据版本?
- 与上一版相比改了什么?
- 是哪个变化导致了结果波动?
- 这个版本是否可发布?
- 如果要回滚,应该回滚到哪里?
如果这些问题不能被系统回答,那么实验结果就只能是一次性的观察,而不是组织可复用的知识。
8.2 版本治理与目录命名的区别¶
很多团队习惯按日期或按人名建目录,把这称为“版本管理”。 这种方式能提供最表面的可区分性,却无法提供真正的平台治理能力。
真正的版本治理至少应包括:
- 唯一版本标识;
- 版本状态;
- 上游依赖关系;
- 变更摘要;
- 发布与冻结规则;
- 回滚候选关系;
- 与实验、报告、发布对象之间的引用链。
8.3 版本结构示意¶
dataset_version = {
"version_id": "ds_v005",
"project_id": "p02_legal_sft",
"status": "released",
"parent_version": "ds_v004",
"change_summary": [
"补充高风险拒答样本",
"修复重复切块问题",
"同步新评测标签"
],
"rollback_candidate": True
}
在这个结构中,版本不再是静态标签,而是一个能参与运行、评估和回滚的治理对象。
9. 实验追踪:运行记录与原因追踪¶
当前平台共记录 7 次实验,其中:
completed = 5regressed = 1failed = 1
这组数字非常有代表性,因为它说明平台没有只保留成功实验。
9.1 保留全部实验记录¶
很多项目汇报习惯只展示“最佳结果”。 但平台治理的目标不是做一份漂亮的宣传材料,而是沉淀团队的真实运行轨迹。
失败实验、回归实验和不稳定实验,通常才是平台最有价值的资产,因为它们回答的是:
- 哪些策略无效;
- 哪些版本存在风险;
- 哪些指标对波动最敏感;
- 哪些实验结果不值得进入发布流程。
9.2 实验对象需要包含哪些核心信息¶
一个平台级实验对象至少应包括:
- 实验 ID
- 所属项目
- 引用的数据版本
- 关键配置
- 运行状态
- 结果摘要
- 评测结论
- 是否触发告警
- 是否关联 rollback
这让平台具备从“实验发生了”走向“实验可被追责、可被复盘、可被门禁”的能力。
9.3 一个实验记录的简化结构¶
experiment_run = {
"experiment_id": "exp_007",
"project_id": "p02_legal_sft",
"dataset_version": "ds_v005",
"status": "regressed",
"metric_summary": {
"f1": 0.79,
"latency_ms": 620
},
"requires_review": True
}
![]()
10. 血缘图:版本、实验与事件的关联¶
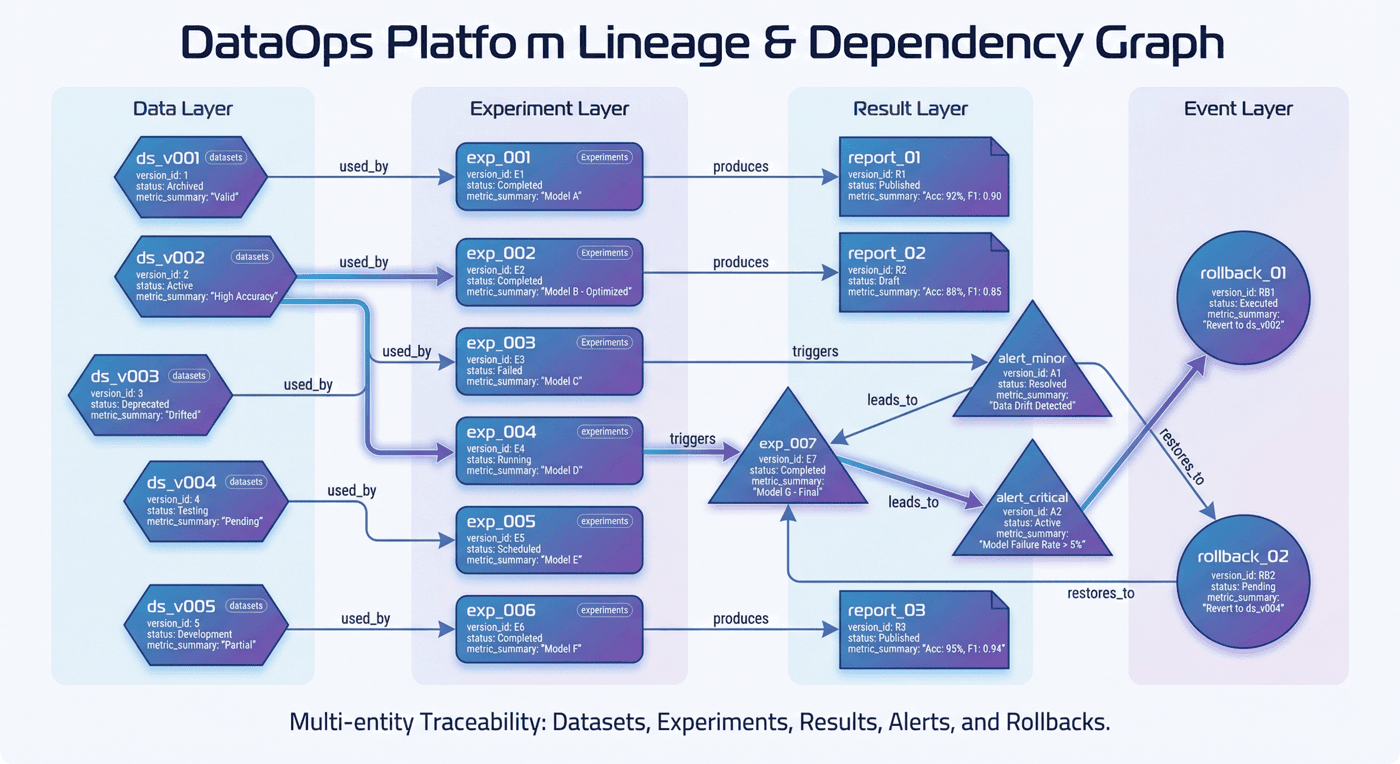
当前血缘图规模为:21 个节点、19 条边。 这说明平台已经开始把对象之间的依赖关系组织成图,而不是停留在表格式记录。
10.1 血缘图的因果追踪作用¶
血缘图的真正价值,在于它能帮助团队回答一连串关键问题:
- 某个数据版本被哪些实验使用?
- 某次实验失败是否影响后续发布?
- 哪条告警是由哪个实验或版本触发的?
- 某次 rollback 退回的是哪条链路上的对象?
- 某个结果报表是由哪些上游对象共同生成的?
如果没有血缘图,这些问题只能依赖人工追查; 如果有血缘图,它们就可以成为平台的日常能力。
10.2 一个简单的边定义示例¶
10.3 原型期引入血缘的价值¶
很多团队会觉得,血缘图应该等平台成熟后再做。 但恰恰相反,越早引入血缘,越容易形成可持续的对象设计。 如果一开始就把版本、实验、告警、回滚和报告视为互相关联的图对象,后续平台扩展会更顺; 如果一开始把它们分散成若干孤立表格,后面再补血缘通常成本更高。
11. 回滚机制:平台的恢复能力¶
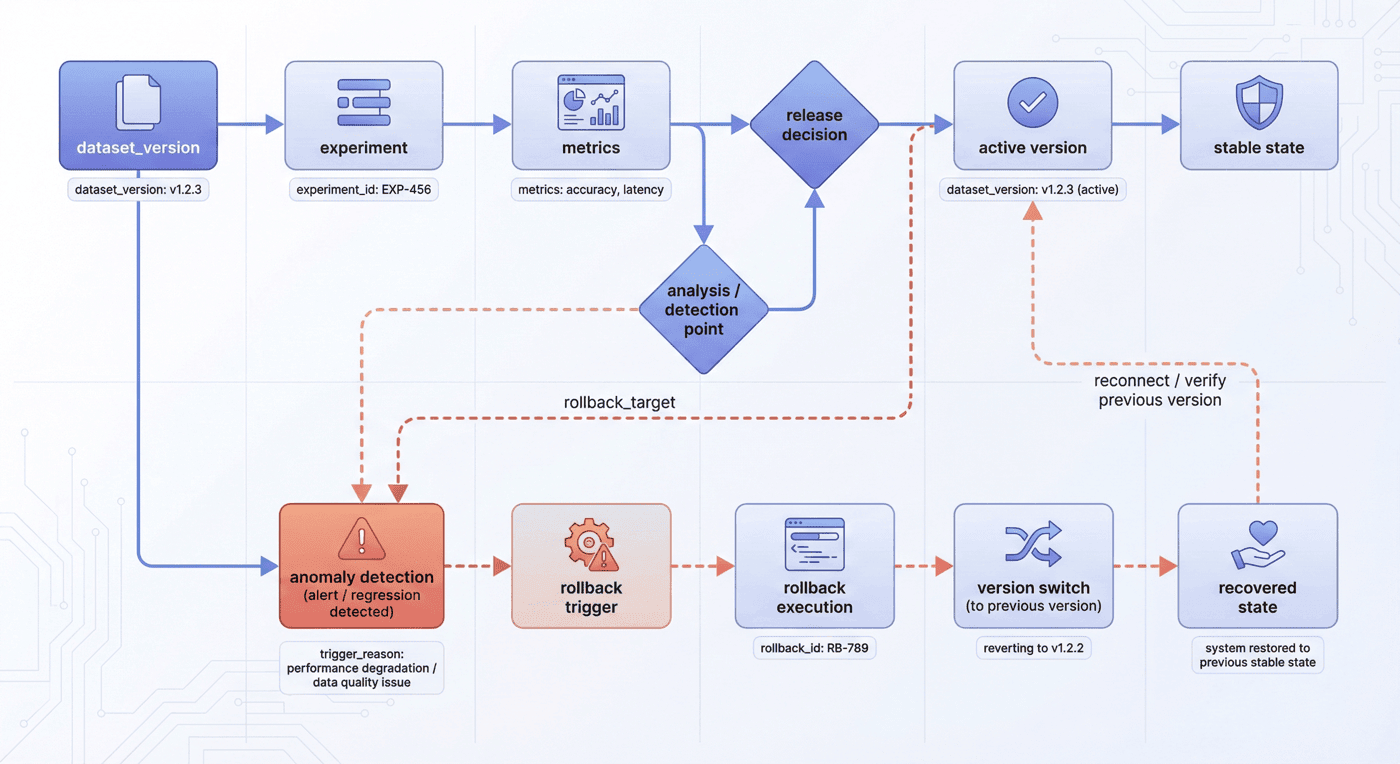
当前平台显式保留了 rollback=1 这一事件。
这一点很重要,因为它说明平台不只管理前进路径,也管理撤回路径。
11.1 回滚作为基础能力¶
现实中的数据项目并不会线性向好。 一次数据修订、一次清洗逻辑调整、一次评测集替换,甚至一次任务顺序变化,都可能让结果变差。
如果平台没有显式回滚能力,团队只能在出现问题后临时恢复历史文件、人工切换版本或重新部署旧对象。 这类做法的问题在于:
- 恢复时间长;
- 操作不可审计;
- 责任边界模糊;
- 经验无法沉淀。
11.2 rollback 事件应该记录什么¶
一个合格的 rollback 事件,至少应包括:
- rollback ID
- 触发原因
- 关联实验或告警
- 回滚目标版本
- 执行时间
- 执行人
- 恢复状态
- 后续复盘链接
11.3 rollback 对组织信任的作用¶
当平台发生回归时,团队最怕的不是“需要后退”,而是“后退成本不可控”。 一个具备 rollback 能力的平台,可以把“出现问题怎么办”从紧急救火变成标准动作。
12. 可观测性:平台健康判断¶
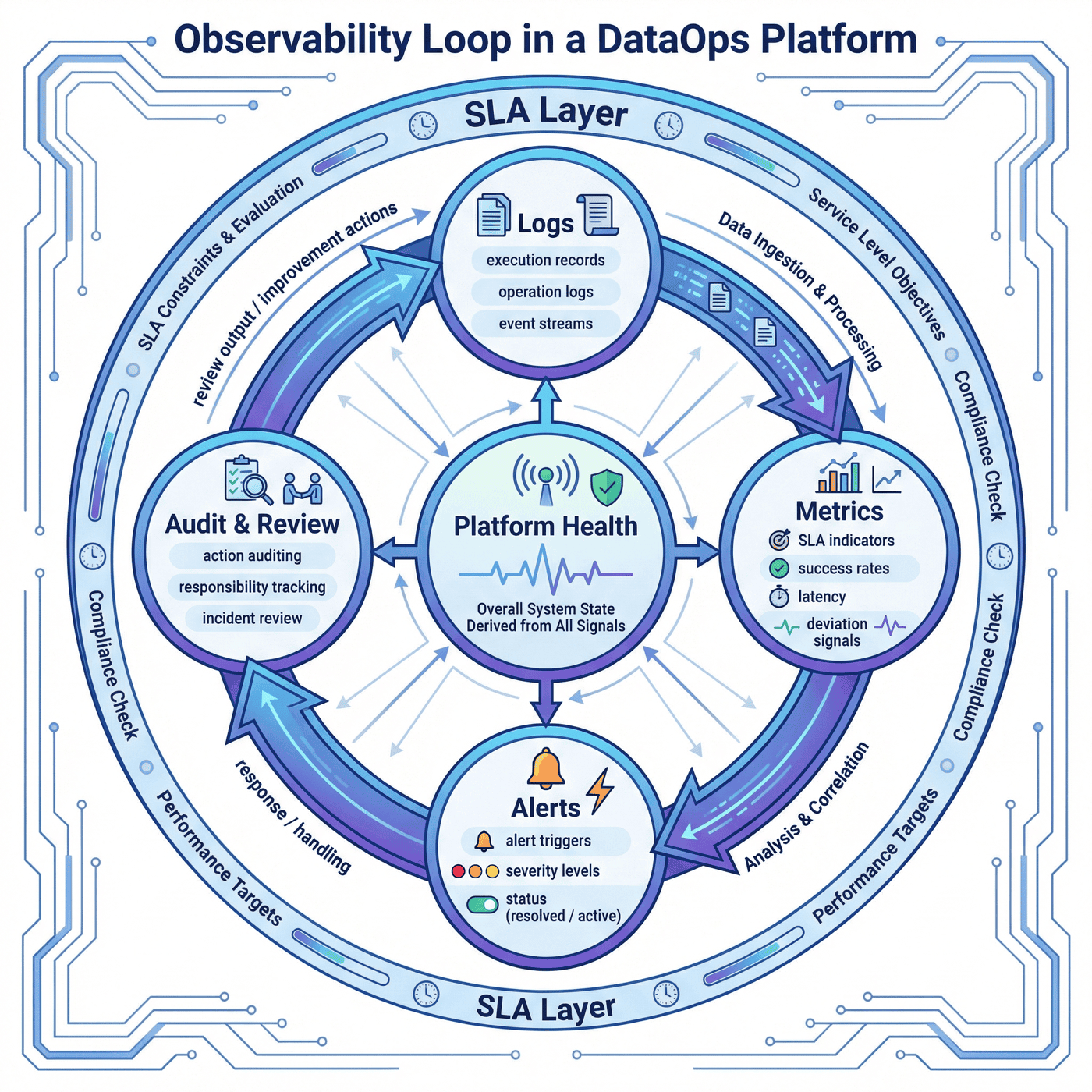
当前平台可观测性侧有:
- 告警
3条 - 解决率
100.00% - SLA 达标率
100.00% - 平均事故恢复时长
36.5分钟
这说明 P08 并不是只统计“任务是否执行成功”,而是开始衡量更接近真实平台运营的问题:
- 有没有告警;
- 告警是否被解决;
- SLA 是否达标;
- 事故恢复需要多久。
12.1 超出日志的可观测性¶
日志很重要,但日志只回答“发生了什么”。 平台运营还需要其它维度:
- 指标回答“是否偏离”;
- 告警回答“是否需要响应”;
- 审计回答“是谁做了什么”;
- 事故复盘回答“以后如何避免”。
这几个维度共同组成平台的可观测闭环。
12.2 SLA 视角¶
SLA 的价值在于,它把“系统运行”转换成“服务承诺”。 一旦平台进入组织使用阶段,团队关心的不只是脚本是否能跑完,而是:
- 平台是否持续可用;
- 异常是否及时发现;
- 故障是否在可接受时间内恢复;
- 关键治理动作是否被保障。
12.3 一个简化的告警结构¶
alert = {
"alert_id": "alert_003",
"severity": "high",
"category": "sla_risk",
"related_object": "experiment:exp_007",
"status": "resolved"
}
13. 审计与事故复盘:incident review 作为平台组成¶
P08 的主要交付物中明确包含:
alerts.jsonlaudit_log.jsonlincident_reviews.jsonlsla_report.json
这说明平台没有把事故处理留在系统之外。 这点非常关键,因为很多团队会把事故复盘做成会议纪要或聊天记录,而不是平台资产。 这样做的后果是: 事故虽然“讨论过了”,但平台并没有真正变得更强。
13.1 incident review 应该沉淀什么¶
一个真正有价值的事故复盘,不只记录“发生过一次问题”,更应该沉淀:
- 问题现象;
- 影响范围;
- 根因分析;
- 临时修复动作;
- 永久修复项;
- 责任角色;
- 截止日期;
- 对应版本或对象。
13.2 审计日志与复盘联动¶
审计日志负责回答“谁做了什么”, incident review 负责回答“为什么出问题、以后怎么不再发生”。 这两者如果分开存在,平台只能提供局部证据; 如果联动存在,平台才真正具备学习能力。
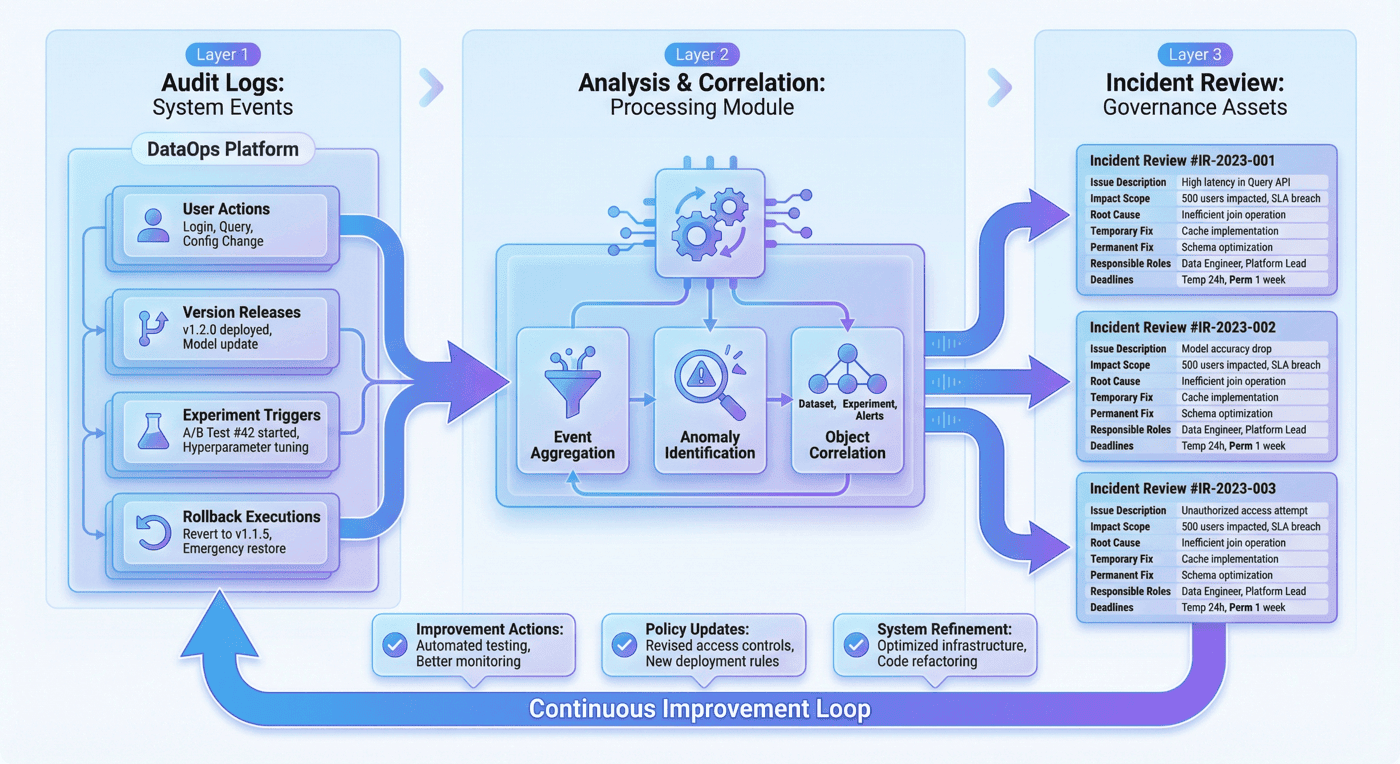
14. 控制台与运营视图:面板化治理对象¶
当前平台有 5 个 UI 面板。 虽然当前项目重点不在 UI 实现本身,但这个数字本身说明,平台已经考虑到治理对象需要被组织成不同视图。
对于 DataOps 平台来说,面板的价值不在于“可视化很好看”,而在于:
- 把对象分门别类;
- 把运行状态结构化呈现;
- 把不同角色需要看的内容隔离开;
- 把平台日常动作转成可理解的操作界面。
一个合理的控制台视图通常可以包括:
- 平台总览面板
- 版本与发布面板
- 实验与评测面板
- 告警与 SLA 面板
- 审计与复盘面板
这样的设计方式意味着平台不是一个统一大杂烩页面,而是将治理对象按职责拆分成不同视图。
15. 项目检查:平台一致性验证¶
项目当前共有 13 项检查,全部通过。
其中命令级检查 2 项,数据/产物级检查 11 项。
检查覆盖包括:
py_compileevaluate_platformrequired_files_existrole_and_permission_model_presentarchitecture_layers_completeapi_queue_ui_presentversion_lineage_links_validexperiments_reference_versions ...
这类检查非常重要,因为它决定平台是否真正具备代码、产物与报告之间的一致性验证能力。
15.1 检查链路的作用¶
很多项目文档能写得非常漂亮,架构图、流程图、指标解释都很完整。 但如果代码、产物和报告彼此不一致,学到的就不是工程方法,而只是案例包装。
15.2 检查在平台项目中的意义¶
对于平台项目,检查至少承担三种作用:
- 验证产物是否齐全;
- 验证对象关系是否合理;
- 验证报告描述是否与数据一致。
15.3 一个简化的检查示例¶
required_files = [
"data/processed/platform_scope.json",
"data/processed/architecture_spec.json",
"data/processed/dataset_versions.jsonl",
"data/processed/experiment_runs.jsonl",
"data/reports/p8_metrics.json",
"data/reports/p8_test_report.md"
]
for path in required_files:
assert Path(path).exists(), f"Missing required artifact: {path}"
这种检查看起来简单,但它能有效把平台工程从“概念正确”推进到“交付一致”。
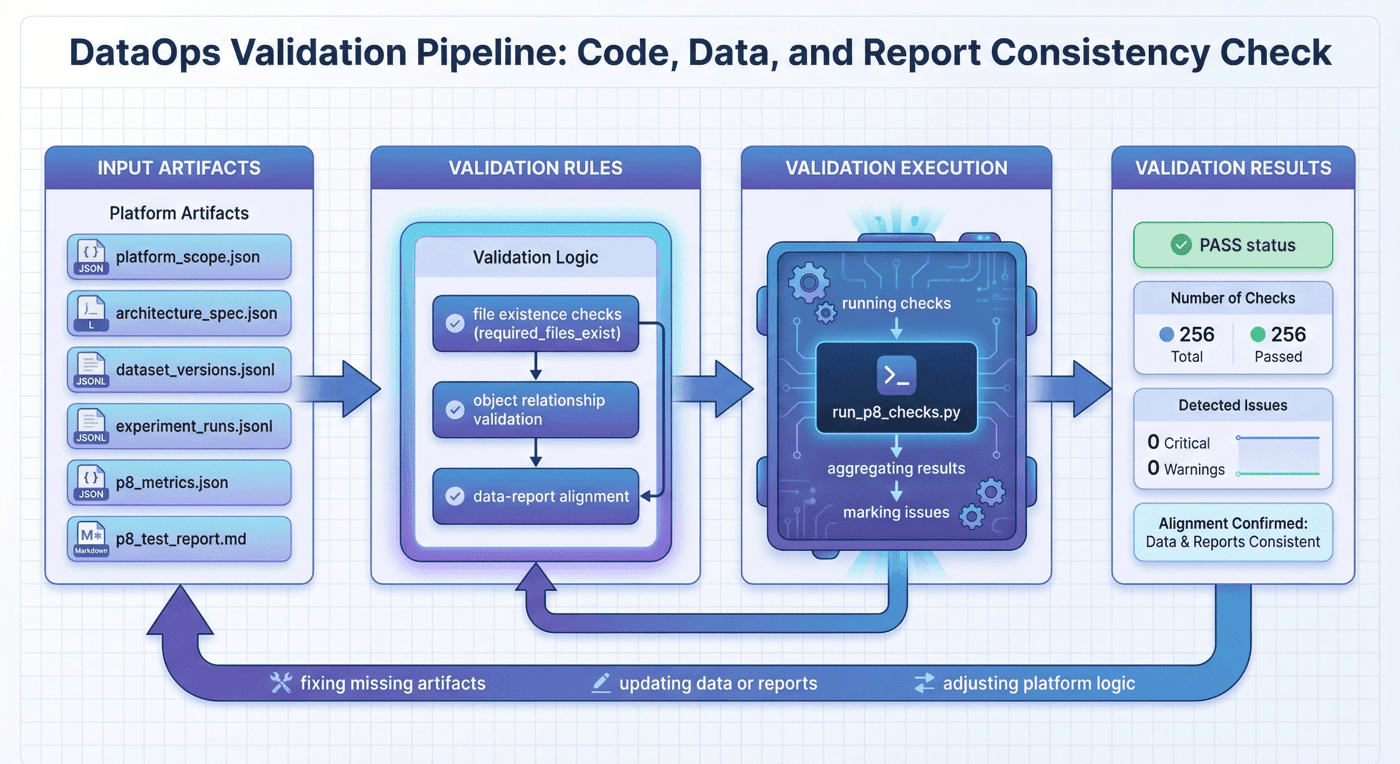
16. 主要交付物:平台完整产物链¶
P08 的主要交付物包括:
data/processed/platform_scope.jsondata/processed/architecture_spec.jsondata/processed/api_catalog.jsondata/processed/task_queues.jsondata/processed/governance_policy.jsondata/processed/operating_model.jsondata/processed/dataset_versions.jsonldata/processed/experiment_runs.jsonldata/processed/lineage_graph.jsondata/processed/rollback_events.jsonldata/processed/alerts.jsonldata/processed/audit_log.jsonldata/processed/incident_reviews.jsonldata/processed/sla_report.jsondata/console/ui_panels.jsondata/reports/p8_report.mddata/reports/p8_chapter_preview.pdfdata/reports/p8_preview_stats.jsondata/reports/p8_metrics.jsondata/reports/p8_test_results.jsondata/reports/p8_test_report.md
这组交付物说明,P08 并不只有最终报告,而是已经沉淀出一条完整的平台产物链。
从这组文件可以进一步看出:
- 平台不是只有“最后展示层”;
- 中间状态和治理对象都被保存;
- 报告、指标和检查来自真实产物,而不是反向编写。
17. 结果解读:P08 当前体现出的平台特征¶
P08 的一个关键特征,是它没有把平台收缩成只沿成功路径推进的理想系统,而是显式保留了:
- 回归实验;
- 失败实验;
- rollback 事件;
- 告警和 incident review;
- 文档与代码之间的小缺口。
这些信息共同说明,当前平台已经开始覆盖真实治理中最关键的几类对象和状态,而不只是展示一套静态架构。
如果一个平台原型只保留概念层和成功路径,后续治理能力就很难被验证。P08 当前至少已经把下面两类信息同时纳入系统:
- 一类是对象、规则、版本、实验和审计等结构化治理对象;
- 另一类是回归、失败、回滚和复盘等失败路径信息。
平台可以不大,但关键治理对象和失败路径必须被系统化保留;只有这样,平台才具备继续扩展为组织级能力的基础。
18. 局限与风险:平台原型的边界¶
当前项目至少有三个需要显式保留的局限。
18.1 当前仍是平台原型¶
它已经具备对象建模、模拟运行、指标评估和检查闭环,但还不是生产级控制平面。 这说明它更适合作为方法论样板,而不是直接作为线上平台方案。
18.2 文档与代码仍有局部不一致¶
README 中提到的 render_p8_chapter.py 当前缺失。
这一点并不会推翻项目价值,但说明平台工程与文档同步仍然是后续要补齐的环节。
18.3 多租户深度治理还未展开¶
虽然项目已经显式包含租户概念,但跨 BU、跨组织的隔离、审批、配额和治理深度还没有真正展开。 这也是平台从原型走向组织级系统的关键差距之一。
主动把这些局限写出来,不会削弱项目,反而会提升案例的可信度。
19. 后续扩展:走向组织级 DataOps¶
结合当前平台结构,P08 后续最自然的扩展方向大致有三条。
19.1 从原型治理走向多 BU 协同治理¶
把当前单团队或小规模协作原型,扩展到真正的跨团队使用环境,需要进一步补齐:
- 配额管理;
- 更细粒度权限;
- 审批与例外机制;
- 多租户隔离策略。
19.2 从静态记录走向动态门禁¶
当前平台已经能够记录版本、实验、告警和回滚。 下一步可以把这些对象进一步接入动态门禁逻辑,例如:
- 实验回归自动阻断发布;
- SLA 风险触发冻结;
- 高风险版本需要人工审批;
- 关键项目的 rollback 进入升级流程。
19.3 从技术平台走向运营平台¶
很多平台项目止步于“系统做出来了”,但真正的组织级平台还需要运营节奏,例如:
- 版本冻结日;
- 每周治理例会;
- 值班机制;
- 事故复盘节奏;
- SLA 周报或月报;
- 发布门禁 review。
只有这些节奏与平台对象连在一起,DataOps 才真正从“工具”变成“组织能力”。
20. 本章总结:责任、证据与恢复能力¶
P08 的关键价值,不在于证明“平台可以管理很多 JSON 文件”,而在于证明另一件更重要的事:
当数据工程从单项目协作走向长期组织化运转时,平台的核心职责不是让流程看起来更统一,而是让版本、实验、失败、告警、回滚和复盘都变成可追踪的系统对象。
从现有项目结果来看,P08 已经具备几个关键的工程特征:
- 有明确的平台边界,而不是泛化成“什么都做”的系统;
- 有从规格生成到模拟运行、指标评估、项目检查的完整链路;
- 有版本、实验、血缘、rollback、SLA、告警、审计和事故复盘等治理对象;
- 有真实失败路径,而不是只保留成功演示;
- 有
13/13检查通过记录,说明代码、产物和报告之间是一致的。
因此,P08 的真正价值,不是“搭了一个平台原型”,而是用一个规模适中的项目,把企业级 DataOps 平台最关键的治理逻辑做成了可讲述、可验证、可复用的案例。
可以把本章最重要的结论压缩成一句话:
DataOps 平台真正要建设的,不是更多页面,而是更完整的治理闭环。
专题:平台从原型走向组织试点的实施路径¶
很多团队在看到 P08 这类平台原型后,第一反应往往是“我们是不是也要先做一个大而全的平台”。但从落地经验看,平台最容易失败的方式,恰恰就是一上来想把所有问题一次性解决。更现实的做法,是把平台建设拆成若干个可落地阶段,让对象模型、治理能力和组织采用率同步增长。
一、第一阶段:先把对象和边界固化下来¶
平台化的第一步通常不是写 UI,也不是接入所有调度器,而是把最关键的系统对象固化下来。也就是说,团队至少要先回答这些问题:
- 平台管理哪些租户、项目和角色;
- 数据版本、实验、告警、回滚和审计分别是什么对象;
- 哪些操作属于平台内动作,哪些仍然停留在外部脚本;
- 平台当前支持哪些边界内的工作流,不支持哪些边界外的需求。
这一阶段的成功标志,不是“功能很多”,而是“所有人开始使用同一套词汇描述同一件事”。一旦这一点做到了,后续无论接入指标、面板还是自动门禁,平台都会有明确依附对象;如果这一点没做到,后续新功能越多,系统就越容易失焦。
二、第二阶段:先打通版本、实验与发布主链¶
从原型进入试点时,最值得优先打通的不是所有治理对象,而是版本、实验和发布三者之间的主链。原因很简单,组织里最频繁、也最痛的分歧,通常都围绕这条链路展开。
在这个阶段里,平台至少应该能回答:
- 某个版本由谁创建、何时创建、变更了什么;
- 某次实验用的是哪个版本、采用了哪些参数、产出了哪些评测结果;
- 某个结果为什么进入发布,或为什么被回滚;
- 某次回归到底发生在版本、实验、评测还是调度环节。
只要这条主链跑通,平台就已经能解决大量“版本失控”和“责任失焦”的问题。相比之下,很多看起来更炫的能力,比如复杂工作台、统一图表大屏或细粒度工作流编排,反而可以放在稍后的阶段逐步补齐。
三、第三阶段:把失败路径接入平台主结构¶
组织试点真正拉开差距的地方,往往不在成功路径,而在失败路径是否被纳入主结构。平台如果只记录“谁成功发布了什么”,它很快就会沦为展示面板;只有当失败实验、回归告警、审批阻断和 rollback 事件都被结构化保留时,平台才真正成为治理基础设施。
这一阶段最值得优先补齐的通常有四件事:
- 告警对象化,不再让告警只停留在消息工具里;
- rollback 结构化,让恢复动作可追踪、可复盘;
- incident review 标准化,让事故经验能反哺流程;
- 例外审批留痕,让高风险放行不再依赖口头沟通。
很多团队会担心,把失败路径写进平台会显得“系统不稳定”。但恰恰相反,只有敢于把失败对象化,平台才有机会变得稳定。因为稳定不是没有问题,而是出了问题也能定位、恢复和学习。
四、第四阶段:再推进多团队采用与运营节奏¶
当主结构已经清楚、失败路径也纳入系统后,平台才适合真正推进多团队采用。这时重点不再只是“系统能做什么”,而是“组织愿不愿意用、会不会持续用、能不能在平台上形成运营节奏”。
这一步通常需要补齐:
- 团队 onboarding 机制;
- 平台操作手册和角色说明;
- 周报、月报、值班和复盘节奏;
- 关键指标的看板化呈现;
- 版本冻结、发布评审和例外审批机制。
平台真正进入组织试点,并不意味着所有技术问题都解决了,而是意味着平台已经开始承接真实协作关系。到这一刻,平台建设就不再是一个纯技术项目,而是一个技术与运营同时存在的组织项目。
专题:平台级指标体系与运营节奏¶
平台项目很容易掉进一个误区,就是把“指标”理解成少数技术指标的堆叠,比如任务成功率、CPU 使用率或平均耗时。这些指标当然重要,但它们并不足以判断 DataOps 平台是否真的发挥了组织价值。平台级指标必须同时覆盖使用、质量、治理和恢复四个维度。
一、使用维度:平台是不是真的被采用¶
平台最先要回答的,不是“我们做了多少功能”,而是“团队是否真的在平台上完成关键动作”。因此,使用维度至少应该关注:
- 活跃租户数、活跃项目数和活跃角色覆盖情况;
- 关键动作的平台内完成率,例如版本创建、发布审批、回滚发起、告警确认是否都在平台闭环内完成;
- 通过平台进入的实验数、发布数和审计记录数;
- 不同团队对同一平台对象模型的使用一致性。
如果这些指标长期偏低,说明平台虽然存在,但还没有真正成为工作入口;如果这些指标逐步提升,平台才算从“工具可用”进入“组织在用”。
二、质量维度:平台是否减少了不确定性¶
平台不是为了简单替代脚本,而是为了降低系统不确定性。质量维度可以重点关注:
- 版本到实验的引用完整率;
- 实验到报告的对齐率;
- 发布前检查通过率;
- 回归问题定位时长;
- 文档、代码和产物之间的一致性缺口数量。
这些指标共同反映的是,平台有没有让“出了问题但不知道问题在哪”这种状态减少。只要这一点在下降,平台就已经在创造很真实的工程收益。
三、治理维度:高风险动作是否被纳入控制¶
DataOps 平台和普通内部系统的最大区别之一,在于它必须对高风险动作建立治理约束。因此,治理维度适合关注:
- 高风险版本是否都经过审批;
- 告警是否在规定时间内得到确认与处理;
- 审计日志覆盖率是否达到预期;
- 关键角色权限变更是否留痕;
- incident review 是否形成整改闭环。
这一组指标不一定会直接提高“性能”,但它们决定平台能否被组织长期信任。很多平台技术上能跑,但治理维度长期缺失,最后就会在关键时刻被绕开。
四、恢复维度:系统出问题后能不能有序恢复¶
平台建设中最有价值、但常被忽视的一组指标,就是恢复维度。因为组织真正关心的,并不只是“有没有问题”,而是“有问题之后能不能迅速恢复,并且知道以后如何避免同类问题”。
恢复维度通常可以关注:
- rollback 触发次数与成功率;
- 平均恢复时间和关键事件恢复时间;
- 高优先级事故的复盘完成率;
- 同类问题重复发生率;
- 从告警触发到恢复完成的全过程可追踪率。
这些指标能帮助平台从“能看见问题”进一步升级到“能处理问题并沉淀经验”。
五、运营节奏:指标必须嵌入固定机制¶
指标如果只停留在报表里,通常很快会失去生命力。更有效的方式,是把不同维度的指标嵌入固定运营节奏中。
一个比较实用的节奏可以是:
- 日级关注运行、告警和恢复类指标;
- 周级关注版本、实验、回归和门禁类指标;
- 月级关注租户采用率、治理成熟度和平台收益类指标;
- 季度关注跨团队协同、制度执行和平台扩容方向。
这样一来,平台指标就不再只是“为了汇报而统计”,而是直接嵌入组织的日常治理动作。指标一旦进入节奏,平台就会从项目产物逐步变成组织习惯。
专题:DataOps 平台建设中的常见反模式¶
把平台做出来并不难,难的是避免走进那些一开始看起来合理、长期却会拖累系统的反模式。P08 作为原型案例,恰好适合把这些反模式提前写清楚。
一、只有控制台,没有对象模型¶
这是最常见、也最危险的一种反模式。团队先做了一套很像平台的页面,里面有列表、有图表、有按钮,但如果去问“版本、实验、回滚、告警之间是什么关系”,往往很难得到清楚答案。结果就是页面越来越多,系统却越来越难解释。
没有对象模型的平台,短期看上去迭代很快,长期却很难承接治理。因为所有新增功能都只能挂在 UI 层,而不是挂在稳定的系统对象上。
二、只记录成功路径,不记录失败路径¶
很多内部平台为了展示效果,只保存成功发布、顺利实验和漂亮指标,却把失败实验、异常恢复和人工介入都留在系统外。这样做的结果,是平台永远只能讲“理想中的流程”,却无法支持真实复盘。
一旦组织开始依赖平台,失败路径就必须是平台的一部分。否则每次出问题,团队都会回到聊天记录、临时脚本和个人记忆里寻找答案,平台本身就失去了最重要的价值。
三、把审计和权限留到最后再补¶
另一种高频反模式,是先把主流程跑通,再想着以后补审计、补权限、补审批。问题在于,这些能力不是表层装饰,而是很多对象关系的组成部分。等主流程已经写死之后再补,往往意味着要重构大半系统。
更稳妥的方式,是哪怕一开始只有最小化版本,也要先把角色边界、审计留痕和高风险操作控制点放进系统骨架里。平台越早考虑这些问题,后续越容易扩展。
四、把版本治理做成目录命名规范¶
有些团队会把平台中的版本治理,退化成“大家约定好命名规则”。命名规则当然有帮助,但它不等于治理。真正的治理至少要包含版本元信息、引用关系、发布时间、审批状态、回滚关联和实验依赖。如果这些都没有,所谓版本管理仍然只是“更整齐的文件夹”。
P08 之所以强调版本中心、实验追踪和血缘关系,正是为了避免把治理误解为整理目录。目录可以帮助人找到文件,但只有结构化对象才能帮助系统解释因果关系。
五、把平台当成技术工具,而不是组织机制¶
最后一种反模式,也是很多平台迟迟做不大的根源,就是始终把平台看成工程师写给工程师的内部工具。只要这样理解,平台就很难吸纳项目经理、治理角色、审计角色和运营角色,也很难形成固定节奏。
真正的平台一定同时是一种组织机制。它需要定义谁负责什么、什么情况下可以例外、哪些指标要被持续跟踪、哪些事故必须复盘、哪些风险不能被口头放行。只有当这些机制和平台对象绑定在一起时,DataOps 才会从“一个系统”升级为“一个组织能力”。
专题:平台试点中的角色冲突与治理协同¶
DataOps 平台进入试点后,经常会遇到一种很真实但又不太技术化的问题,就是不同角色对同一个平台目标的理解并不一致。平台团队更关心结构和统一性,业务团队更关心效率,治理团队更关心边界和责任,管理角色更关心节奏与结果。如果这几种视角不能被平台显式吸收,平台就会在试点期频繁出现摩擦。
一、角色冲突通常不是坏事,而是信号¶
平台试点里常见的冲突包括:
- 业务团队希望快速发布,治理团队要求补齐审批;
- 算法团队希望灵活试验,平台团队要求统一版本入口;
- 运维团队关注稳定性,项目团队更看重局部效率;
- 管理层希望看整体看板,一线团队更需要细粒度上下文。
这些冲突并不说明平台失败了,反而说明平台开始真正接入真实协作关系。问题的关键不在于消灭冲突,而在于让冲突能够在平台对象和治理机制里被吸收,而不是反复回到临时沟通中去。
二、平台需要给不同角色提供不同的“正确性”¶
对平台工程来说,一个很重要的认知是,不同角色眼中的“正确”并不相同。对工程师来说,正确可能意味着对象关系清楚、版本引用完整;对治理角色来说,正确可能意味着高风险动作都留痕并可追溯;对业务角色来说,正确可能意味着流程不要过度阻塞;对管理角色来说,正确可能意味着风险和进度都能被一眼看见。
这意味着平台不能只用一种视图服务所有人。更成熟的做法,是围绕同一批对象,向不同角色暴露不同层次的信息:
- 工程角色看到结构和依赖;
- 治理角色看到审批、审计和风险;
- 业务角色看到进度、阻塞和交付状态;
- 管理角色看到里程碑、趋势和整体健康度。
一旦这一点做到了,很多看似“平台不够好用”的问题,其实就会转化为“平台需要给这个角色增加合适视图”。
三、协同治理的关键是把分歧写进流程¶
平台从原型走向组织能力时,最需要沉淀下来的,不是“大家终于完全达成一致”,而是“当大家不一致时,系统规定应该如何推进”。这通常意味着:
- 哪些发布必须经过评审;
- 哪些回归可以临时放行,哪些必须阻断;
- 谁可以发起例外,谁可以批准例外;
- 复盘结论如何进入下一轮平台改造;
- 哪些冲突属于流程问题,哪些冲突属于对象设计问题。
只要这些分歧被写进流程,平台就开始具备治理弹性。它不要求组织完全没有矛盾,而是要求矛盾出现时能有序解决。这也是 P08 作为平台案例最适合补充出来的一层实践价值。
专题:平台发布评审与例外处理机制¶
DataOps 平台一旦进入多团队使用阶段,就不可避免会面对发布评审和例外处理。很多组织的问题并不是没有规则,而是规则只写在文档里,没有真正进入平台运行节奏。把发布评审与例外处理写进章节,能够帮助读者更清楚地理解:平台治理并不止于记录事实,还要管理“在什么条件下允许变化发生”。
一、发布评审的重点是判断“现在该不该放行”¶
一个平台版本或关键数据版本进入发布评审时,真正要判断的通常不是“这个版本有没有任何问题”,而是“在当前证据下,这个版本是否达到了可放行标准”。因此,评审会议更适合围绕以下问题展开:
- 检查项是否全部通过,若未全部通过,未通过项的风险等级是什么;
- 当前版本是否引入了新的高风险对象或新的跨团队依赖;
- 如果出现回归,rollback 是否已经准备好;
- 本次放行是否会影响关键租户、关键项目或关键 SLA。
这样的平台评审,本质上是在把发布决策从个人判断升级为结构化判断。
二、例外处理必须被记录成平台对象¶
组织里永远会存在某些需要加急、破例或临时绕行的情况。问题不在于要不要允许例外,而在于例外能不能被平台对象化。一个成熟的例外处理机制通常至少要保留:
- 例外原因;
- 生效范围;
- 生效时间;
- 批准角色;
- 到期后的回收与复盘动作。
只要这些信息能进入平台,例外就不再是治理失败,而是治理的一部分。反过来,如果例外总在系统外发生,平台就会逐渐失去权威性。
专题:平台 adoption 的推进策略¶
很多平台项目在技术上已经能用,却始终推不开,根本原因往往不是功能不够,而是 adoption 策略缺失。P08 这类平台在组织内部要真正形成使用惯性,通常需要把 adoption 当成单独工作来设计。
一、先抓高频痛点,再扩功能外延¶
平台 adoption 最有效的方式,通常不是一次性推给所有团队,而是先抓住最痛、最频繁、最容易形成共识的场景,例如版本追踪、实验回归定位、发布前检查和 rollback 记录。只要这些高频痛点先被平台稳定承接,团队就会自然增加使用黏性。
二、让首次使用成本足够低¶
很多平台失败不是因为长期价值不够,而是第一次接入成本太高。更好的做法通常是:
- 预置项目模板;
- 提供最小必填对象;
- 自动生成部分元数据;
- 把关键结果直接映射到现有报表与面板。
这样团队在第一次进入平台时,不会觉得自己是在“多做一套工作”,而更像是在原有工作基础上获得更强的结构化能力。