架构¶
OpenTalking 是面向实时数字人的编排框架,负责协调语音识别、语言模型、语音合成、 talking-head 渲染与 WebRTC 推送,整合为统一的会话模型。框架对外提供一套简洁的 HTTP 与 WebSocket 接口。
本页说明系统级架构:组件、部署拓扑、会话生命周期、事件总线,以及可插拔合成 backend 边界。
架构总览¶
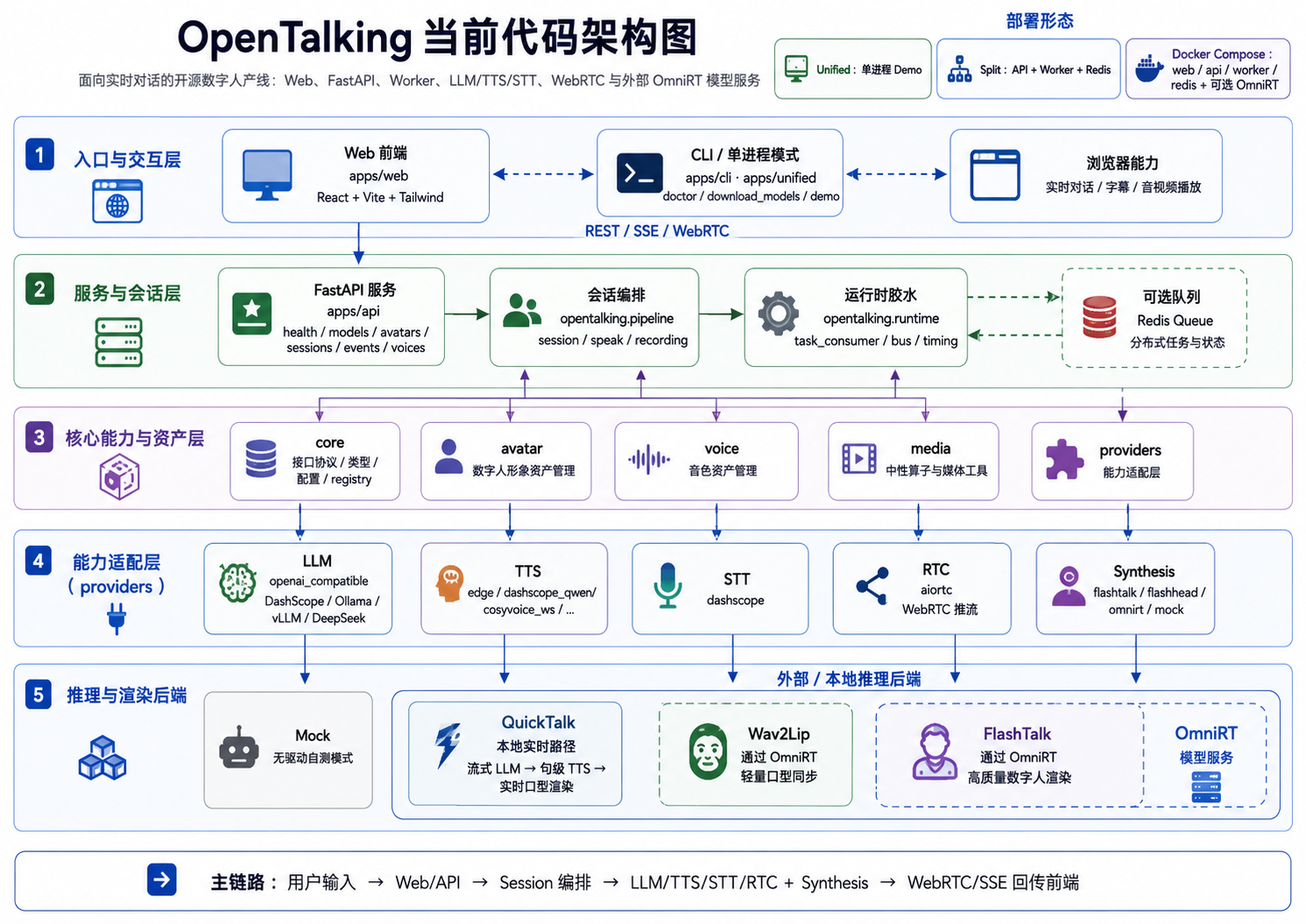
组件¶
flowchart TB
subgraph 前端
Web[apps/web<br/>React + Vite]
end
subgraph "OpenTalking 服务"
API[apps/api<br/>FastAPI 路由<br/>会话状态]
Worker[apps/worker<br/>流水线驱动]
Bus[(Redis<br/>或内存)]
end
subgraph 外部
LLM[语言模型端点<br/>OpenAI 兼容]
TTSExt[语音合成<br/>Edge / DashScope / ElevenLabs]
STT[语音识别<br/>DashScope Paraformer]
Synth[(合成 backend<br/>mock / local / direct_ws / omnirt)]
end
Web -->|HTTP / SSE / WebRTC| API
Web -.->|音频流 WS| API
API <-->|pub/sub| Bus
Worker <-->|pub/sub| Bus
Worker --> LLM
Worker --> TTSExt
Worker --> STT
Worker --> Synth| 组件 | 职责 | 源码 |
|---|---|---|
apps/api |
HTTP 与 WebSocket 入口、会话 CRUD、WebRTC 信令、SSE 事件流。 | apps/api/routes/ |
apps/worker |
驱动一个或多个会话执行渲染管线。 | apps/worker/、opentalking/worker/ |
apps/unified |
单进程组合 API、Worker 与内存总线,面向开发场景。 | apps/unified/ |
opentalking/ 库 |
Provider、适配器、接口、类型、配置、总线与流水线代码。 | opentalking/(flat layout) |
| 合成 backend | 由 backend resolver 按模型选择:mock、local、direct_ws、omnirt。 |
opentalking/providers/synthesis/ |
| OmniRT(外部) | 当模型使用 backend: omnirt 时承载重模型、多卡、GPU/NPU 与远端推理。 |
datascale-ai/omnirt |
| Redis(外部) | API 与 Worker 之间的 pub/sub 总线。 | unified 模式可省略。 |
部署拓扑¶
flowchart LR
subgraph "拓扑 A:Unified"
direction TB
U[apps/unified]
end
subgraph "拓扑 B:API + Worker"
direction TB
Aa[apps/api] --- Rr[(Redis)] --- Ww[apps/worker]
end
subgraph "拓扑 C:API + 多 Worker"
direction TB
Ab[apps/api] --- Rb[(Redis)]
Rb --- Wb1[Worker 1]
Rb --- Wb2[Worker 2]
Rb --- Wb3[Worker N]
end命令行细节详见 部署。
会话生命周期¶
sequenceDiagram
participant Browser as 浏览器
participant API
participant Worker
participant LLM
participant TTS
participant Model as 合成 backend
participant Redis
Browser->>API: POST /sessions(avatar_id、model)
API->>Redis: 发布 session.created
Worker->>Redis: 订阅会话事件
Browser->>API: POST /sessions/{id}/webrtc/offer
API->>Worker: SDP 交换
Worker-->>Browser: WebRTC track 建立
Browser->>API: POST /sessions/{id}/chat
API->>Redis: 发布 chat.request
Worker->>LLM: 流式获取 token
LLM-->>Worker: token delta
Worker->>TTS: 按句合成
TTS-->>Worker: 音频字节
Worker->>Model: 以音频驱动
Model-->>Worker: 视频帧
Worker-->>Browser: AV 帧经 WebRTC 推送
Worker->>Redis: 发布事件(transcript、llm、tts、frame)
API->>Browser: 经 SSE 转发
Browser->>API: POST /sessions/{id}/interrupt
API->>Redis: 发布 cancel
Worker->>Worker: 排空缓存并回到 idle事件总线¶
每个会话对应一条逻辑频道,全局控制频道单独维护。事件以 JSON 编码,schema 定义于
opentalking/core/types/events.py 与 opentalking/events/schemas.py。
| 事件 | 生产者 | 消费者 |
|---|---|---|
session.created / session.terminated |
API | Worker |
chat.request / speak.request |
API | Worker |
cancel |
API | Worker |
transcript |
Worker | API → SSE |
llm(token delta) |
Worker | API → SSE |
tts(生命周期标记) |
Worker | API → SSE |
frame(视频帧时序) |
Worker | API → SSE |
error |
Worker | API → SSE |
unified 模式总线为内存实现;分布式模式使用 Redis pub/sub。
边界¶
下列事项不在 OpenTalking 范围内:
| 事项 | 由谁承载 |
|---|---|
| 模型执行与权重加载 | 所选合成 backend(local、direct_ws 或 omnirt) |
| GPU/NPU 调度、批处理、多卡编排 | backend: omnirt 时由 OmniRT 承载;否则由所选 backend 的运行时承载 |
| 语言模型托管 | 用户自选 endpoint(DashScope、OpenAI、vLLM、Ollama 等) |
| 语音合成托管 | 用户自选 provider(或本地 Edge TTS) |
| 用户认证与账号管理 | 不在范围;由上游网关接入。 |
| WebRTC TURN | 不在范围;部署 coturn 或等价服务。 |
apps/ 入口依赖 backend resolver,而不是硬编码模型集合。轻量模型可通过
backend: local 留在进程内,单模型服务可通过 backend: direct_ws 直连,生产级
重模型可通过 OmniRT 承载,且会话 API 不需要改变。
库结构(opentalking/)¶
opentalking/
├── core/
│ ├── interfaces/ # Protocol(ModelAdapter、TTSAdapter 等)
│ ├── types/ # AudioChunk、VideoFrameData、SessionState
│ ├── config.py # Settings 模型(环境变量到类型化配置)
│ ├── model_config.py # 模型运行时配置与 backend 选择
│ └── bus.py # Pub/sub 抽象(Redis 或内存)
├── providers/
│ ├── llm/ # OpenAI 兼容流式客户端
│ ├── stt/ # DashScope Paraformer realtime 适配器
│ ├── tts/ # Edge、DashScope、CosyVoice、ElevenLabs
│ ├── rtc/ # aiortc WebRTC 适配器
│ └── synthesis/ # Backend resolver、可用性探测、OmniRT/direct WS client
├── models/
│ ├── registry.py # @register_model 与本地 adapter 查找
│ └── quicktalk/ # 本地 talking-head 适配器(参考实现)
├── pipeline/
│ ├── session/ # Session runner
│ ├── speak/ # LLM -> TTS -> 合成流水线
│ └── recording/ # 录制与离线导出
├── runtime/ # Worker 进程 glue、总线、时序
├── avatar/ # Avatar bundle 加载与校验
├── voice/ # 声音复刻目录
├── media/ # 帧与 avatar 媒体工具
└── events/ # Event emitter 与 API event schema